mirror of
https://github.com/astaxie/beego.git
synced 2025-10-09 02:38:57 +00:00
@@ -1,7 +1,6 @@
|
||||
language: go
|
||||
|
||||
go:
|
||||
- "1.9.x"
|
||||
- "1.10.x"
|
||||
- "1.11.x"
|
||||
services:
|
||||
@@ -51,7 +50,7 @@ before_script:
|
||||
- mkdir -p res/var
|
||||
- ./ssdb/ssdb-server ./ssdb/ssdb.conf -d
|
||||
after_script:
|
||||
-killall -w ssdb-server
|
||||
- killall -w ssdb-server
|
||||
- rm -rf ./res/var/*
|
||||
script:
|
||||
- go test -v ./...
|
||||
|
||||
3
admin.go
3
admin.go
@@ -20,11 +20,10 @@ import (
|
||||
"fmt"
|
||||
"net/http"
|
||||
"os"
|
||||
"reflect"
|
||||
"text/template"
|
||||
"time"
|
||||
|
||||
"reflect"
|
||||
|
||||
"github.com/astaxie/beego/grace"
|
||||
"github.com/astaxie/beego/logs"
|
||||
"github.com/astaxie/beego/toolbox"
|
||||
|
||||
2
beego.go
2
beego.go
@@ -23,7 +23,7 @@ import (
|
||||
|
||||
const (
|
||||
// VERSION represent beego web framework version.
|
||||
VERSION = "1.11.0"
|
||||
VERSION = "1.11.1"
|
||||
|
||||
// DEV is for develop
|
||||
DEV = "dev"
|
||||
|
||||
@@ -201,6 +201,7 @@ type Response struct {
|
||||
http.ResponseWriter
|
||||
Started bool
|
||||
Status int
|
||||
Elapsed time.Duration
|
||||
}
|
||||
|
||||
func (r *Response) reset(rw http.ResponseWriter) {
|
||||
@@ -259,4 +260,4 @@ func (r *Response) Pusher() (pusher http.Pusher) {
|
||||
return pusher
|
||||
}
|
||||
return nil
|
||||
}
|
||||
}
|
||||
|
||||
25
go.mod
25
go.mod
@@ -1,40 +1,39 @@
|
||||
module github.com/astaxie/beego
|
||||
|
||||
require (
|
||||
github.com/BurntSushi/toml v0.3.1 // indirect
|
||||
github.com/Knetic/govaluate v3.0.0+incompatible // indirect
|
||||
github.com/beego/goyaml2 v0.0.0-20130207012346-5545475820dd
|
||||
github.com/beego/x2j v0.0.0-20131220205130-a0352aadc542
|
||||
github.com/belogik/goes v0.0.0-20151229125003-e54d722c3aff
|
||||
github.com/bradfitz/gomemcache v0.0.0-20180710155616-bc664df96737
|
||||
github.com/casbin/casbin v1.6.0
|
||||
github.com/casbin/casbin v1.7.0
|
||||
github.com/cloudflare/golz4 v0.0.0-20150217214814-ef862a3cdc58
|
||||
github.com/couchbase/go-couchbase v0.0.0-20181019154153-595f46701cbc
|
||||
github.com/couchbase/gomemcached v0.0.0-20180723192129-20e69a1ee160 // indirect
|
||||
github.com/couchbase/go-couchbase v0.0.0-20181122212707-3e9b6e1258bb
|
||||
github.com/couchbase/gomemcached v0.0.0-20181122193126-5125a94a666c // indirect
|
||||
github.com/couchbase/goutils v0.0.0-20180530154633-e865a1461c8a // indirect
|
||||
github.com/cupcake/rdb v0.0.0-20161107195141-43ba34106c76 // indirect
|
||||
github.com/davecgh/go-spew v1.1.1 // indirect
|
||||
github.com/edsrzf/mmap-go v0.0.0-20170320065105-0bce6a688712 // indirect
|
||||
github.com/elazarl/go-bindata-assetfs v0.0.0-20180223110309-38087fe4dafb
|
||||
github.com/elazarl/go-bindata-assetfs v1.0.0
|
||||
github.com/go-redis/redis v6.14.2+incompatible
|
||||
github.com/go-sql-driver/mysql v1.4.0
|
||||
github.com/go-sql-driver/mysql v1.4.1
|
||||
github.com/gogo/protobuf v1.1.1
|
||||
github.com/golang/snappy v0.0.0-20180518054509-2e65f85255db // indirect
|
||||
github.com/gomodule/redigo v2.0.0+incompatible
|
||||
github.com/lib/pq v1.0.0
|
||||
github.com/mattn/go-sqlite3 v1.10.0
|
||||
github.com/onsi/gomega v1.4.2 // indirect
|
||||
github.com/pelletier/go-toml v1.2.0 // indirect
|
||||
github.com/pkg/errors v0.8.0 // indirect
|
||||
github.com/pmezard/go-difflib v1.0.0 // indirect
|
||||
github.com/siddontang/go v0.0.0-20180604090527-bdc77568d726 // indirect
|
||||
github.com/siddontang/ledisdb v0.0.0-20181029004158-becf5f38d373
|
||||
github.com/siddontang/rdb v0.0.0-20150307021120-fc89ed2e418d // indirect
|
||||
github.com/ssdb/gossdb v0.0.0-20180723034631-88f6b59b84ec
|
||||
github.com/stretchr/testify v1.2.2 // indirect
|
||||
github.com/syndtr/goleveldb v0.0.0-20181105012736-f9080354173f // indirect
|
||||
github.com/syndtr/goleveldb v0.0.0-20181127023241-353a9fca669c // indirect
|
||||
github.com/wendal/errors v0.0.0-20130201093226-f66c77a7882b // indirect
|
||||
golang.org/x/crypto v0.0.0-20180723164146-c126467f60eb
|
||||
google.golang.org/appengine v1.1.0 // indirect
|
||||
golang.org/x/crypto v0.0.0-20181127143415-eb0de9b17e85
|
||||
golang.org/x/net v0.0.0-20181114220301-adae6a3d119a // indirect
|
||||
gopkg.in/yaml.v2 v2.2.1
|
||||
)
|
||||
|
||||
replace golang.org/x/crypto v0.0.0-20181127143415-eb0de9b17e85 => github.com/golang/crypto v0.0.0-20181127143415-eb0de9b17e85
|
||||
|
||||
replace gopkg.in/yaml.v2 v2.2.1 => github.com/go-yaml/yaml v0.0.0-20180328195020-5420a8b6744d
|
||||
|
||||
67
go.sum
67
go.sum
@@ -1,5 +1,3 @@
|
||||
github.com/BurntSushi/toml v0.3.1 h1:WXkYYl6Yr3qBf1K79EBnL4mak0OimBfB0XUf9Vl28OQ=
|
||||
github.com/BurntSushi/toml v0.3.1/go.mod h1:xHWCNGjB5oqiDr8zfno3MHue2Ht5sIBksp03qcyfWMU=
|
||||
github.com/Knetic/govaluate v3.0.0+incompatible h1:7o6+MAPhYTCF0+fdvoz1xDedhRb4f6s9Tn1Tt7/WTEg=
|
||||
github.com/Knetic/govaluate v3.0.0+incompatible/go.mod h1:r7JcOSlj0wfOMncg0iLm8Leh48TZaKVeNIfJntJ2wa0=
|
||||
github.com/beego/goyaml2 v0.0.0-20130207012346-5545475820dd h1:jZtX5jh5IOMu0fpOTC3ayh6QGSPJ/KWOv1lgPvbRw1M=
|
||||
@@ -10,54 +8,44 @@ github.com/belogik/goes v0.0.0-20151229125003-e54d722c3aff h1:/kO0p2RTGLB8R5gub7
|
||||
github.com/belogik/goes v0.0.0-20151229125003-e54d722c3aff/go.mod h1:PhH1ZhyCzHKt4uAasyx+ljRCgoezetRNf59CUtwUkqY=
|
||||
github.com/bradfitz/gomemcache v0.0.0-20180710155616-bc664df96737 h1:rRISKWyXfVxvoa702s91Zl5oREZTrR3yv+tXrrX7G/g=
|
||||
github.com/bradfitz/gomemcache v0.0.0-20180710155616-bc664df96737/go.mod h1:PmM6Mmwb0LSuEubjR8N7PtNe1KxZLtOUHtbeikc5h60=
|
||||
github.com/casbin/casbin v1.6.0 h1:uIhuV5I0ilXGUm3y+xJ8nG7VOnYDeZZQiNsFOTF2QmI=
|
||||
github.com/casbin/casbin v1.6.0/go.mod h1:c67qKN6Oum3UF5Q1+BByfFxkwKvhwW57ITjqwtzR1KE=
|
||||
github.com/casbin/casbin v1.7.0 h1:PuzlE8w0JBg/DhIqnkF1Dewf3z+qmUZMVN07PonvVUQ=
|
||||
github.com/casbin/casbin v1.7.0/go.mod h1:c67qKN6Oum3UF5Q1+BByfFxkwKvhwW57ITjqwtzR1KE=
|
||||
github.com/cloudflare/golz4 v0.0.0-20150217214814-ef862a3cdc58 h1:F1EaeKL/ta07PY/k9Os/UFtwERei2/XzGemhpGnBKNg=
|
||||
github.com/cloudflare/golz4 v0.0.0-20150217214814-ef862a3cdc58/go.mod h1:EOBUe0h4xcZ5GoxqC5SDxFQ8gwyZPKQoEzownBlhI80=
|
||||
github.com/couchbase/go-couchbase v0.0.0-20181019154153-595f46701cbc h1:Byzmalcea3rzOdgt4Ny3xrtXkd25zUMPFI5oeKksSbU=
|
||||
github.com/couchbase/go-couchbase v0.0.0-20181019154153-595f46701cbc/go.mod h1:TWI8EKQMs5u5jLKW/tsb9VwauIrMIxQG1r5fMsswK5U=
|
||||
github.com/couchbase/gomemcached v0.0.0-20180723192129-20e69a1ee160 h1:yaqs73s76owCkJbPZo8GKSosZoMjezdLDslJ8aaDk0w=
|
||||
github.com/couchbase/gomemcached v0.0.0-20180723192129-20e69a1ee160/go.mod h1:srVSlQLB8iXBVXHgnqemxUXqN6FCvClgCMPCsjBDR7c=
|
||||
github.com/couchbase/go-couchbase v0.0.0-20181122212707-3e9b6e1258bb h1:w3RapLhkA5+km9Z8vUkC6VCaskduJXvXwJg5neKnfDU=
|
||||
github.com/couchbase/go-couchbase v0.0.0-20181122212707-3e9b6e1258bb/go.mod h1:TWI8EKQMs5u5jLKW/tsb9VwauIrMIxQG1r5fMsswK5U=
|
||||
github.com/couchbase/gomemcached v0.0.0-20181122193126-5125a94a666c h1:K4FIibkr4//ziZKOKmt4RL0YImuTjLLBtwElf+F2lSQ=
|
||||
github.com/couchbase/gomemcached v0.0.0-20181122193126-5125a94a666c/go.mod h1:srVSlQLB8iXBVXHgnqemxUXqN6FCvClgCMPCsjBDR7c=
|
||||
github.com/couchbase/goutils v0.0.0-20180530154633-e865a1461c8a h1:Y5XsLCEhtEI8qbD9RP3Qlv5FXdTDHxZM9UPUnMRgBp8=
|
||||
github.com/couchbase/goutils v0.0.0-20180530154633-e865a1461c8a/go.mod h1:BQwMFlJzDjFDG3DJUdU0KORxn88UlsOULuxLExMh3Hs=
|
||||
github.com/cupcake/rdb v0.0.0-20161107195141-43ba34106c76 h1:Lgdd/Qp96Qj8jqLpq2cI1I1X7BJnu06efS+XkhRoLUQ=
|
||||
github.com/cupcake/rdb v0.0.0-20161107195141-43ba34106c76/go.mod h1:vYwsqCOLxGiisLwp9rITslkFNpZD5rz43tf41QFkTWY=
|
||||
github.com/davecgh/go-spew v1.1.1 h1:vj9j/u1bqnvCEfJOwUhtlOARqs3+rkHYY13jYWTU97c=
|
||||
github.com/davecgh/go-spew v1.1.1/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38=
|
||||
github.com/edsrzf/mmap-go v0.0.0-20170320065105-0bce6a688712 h1:aaQcKT9WumO6JEJcRyTqFVq4XUZiUcKR2/GI31TOcz8=
|
||||
github.com/edsrzf/mmap-go v0.0.0-20170320065105-0bce6a688712/go.mod h1:YO35OhQPt3KJa3ryjFM5Bs14WD66h8eGKpfaBNrHW5M=
|
||||
github.com/elazarl/go-bindata-assetfs v0.0.0-20180223110309-38087fe4dafb h1:T6FhFH6fLQPEu7n7PauDhb4mhpxhlfaL7a7MZEpIgDc=
|
||||
github.com/elazarl/go-bindata-assetfs v0.0.0-20180223110309-38087fe4dafb/go.mod h1:v+YaWX3bdea5J/mo8dSETolEo7R71Vk1u8bnjau5yw4=
|
||||
github.com/fsnotify/fsnotify v1.4.7 h1:IXs+QLmnXW2CcXuY+8Mzv/fWEsPGWxqefPtCP5CnV9I=
|
||||
github.com/fsnotify/fsnotify v1.4.7/go.mod h1:jwhsz4b93w/PPRr/qN1Yymfu8t87LnFCMoQvtojpjFo=
|
||||
github.com/elazarl/go-bindata-assetfs v1.0.0 h1:G/bYguwHIzWq9ZoyUQqrjTmJbbYn3j3CKKpKinvZLFk=
|
||||
github.com/elazarl/go-bindata-assetfs v1.0.0/go.mod h1:v+YaWX3bdea5J/mo8dSETolEo7R71Vk1u8bnjau5yw4=
|
||||
github.com/go-redis/redis v6.14.2+incompatible h1:UE9pLhzmWf+xHNmZsoccjXosPicuiNaInPgym8nzfg0=
|
||||
github.com/go-redis/redis v6.14.2+incompatible/go.mod h1:NAIEuMOZ/fxfXJIrKDQDz8wamY7mA7PouImQ2Jvg6kA=
|
||||
github.com/go-sql-driver/mysql v1.4.0 h1:7LxgVwFb2hIQtMm87NdgAVfXjnt4OePseqT1tKx+opk=
|
||||
github.com/go-sql-driver/mysql v1.4.0/go.mod h1:zAC/RDZ24gD3HViQzih4MyKcchzm+sOG5ZlKdlhCg5w=
|
||||
github.com/go-sql-driver/mysql v1.4.1 h1:g24URVg0OFbNUTx9qqY1IRZ9D9z3iPyi5zKhQZpNwpA=
|
||||
github.com/go-sql-driver/mysql v1.4.1/go.mod h1:zAC/RDZ24gD3HViQzih4MyKcchzm+sOG5ZlKdlhCg5w=
|
||||
github.com/go-yaml/yaml v0.0.0-20180328195020-5420a8b6744d h1:xy93KVe+KrIIwWDEAfQBdIfsiHJkepbYsDr+VY3g9/o=
|
||||
github.com/go-yaml/yaml v0.0.0-20180328195020-5420a8b6744d/go.mod h1:hI93XBmqTisBFMUTm0b8Fm+jr3Dg1NNxqwp+5A1VGuI=
|
||||
github.com/gogo/protobuf v1.1.1 h1:72R+M5VuhED/KujmZVcIquuo8mBgX4oVda//DQb3PXo=
|
||||
github.com/gogo/protobuf v1.1.1/go.mod h1:r8qH/GZQm5c6nD/R0oafs1akxWv10x8SbQlK7atdtwQ=
|
||||
github.com/golang/protobuf v1.2.0 h1:P3YflyNX/ehuJFLhxviNdFxQPkGK5cDcApsge1SqnvM=
|
||||
github.com/golang/protobuf v1.2.0/go.mod h1:6lQm79b+lXiMfvg/cZm0SGofjICqVBUtrP5yJMmIC1U=
|
||||
github.com/golang/crypto v0.0.0-20181127143415-eb0de9b17e85 h1:B7ZbAFz7NOmvpUE5RGtu3u0WIizy5GdvbNpEf4RPnWs=
|
||||
github.com/golang/crypto v0.0.0-20181127143415-eb0de9b17e85/go.mod h1:uZvAcrsnNaCxlh1HorK5dUQHGmEKPh2H/Rl1kehswPo=
|
||||
github.com/golang/snappy v0.0.0-20180518054509-2e65f85255db h1:woRePGFeVFfLKN/pOkfl+p/TAqKOfFu+7KPlMVpok/w=
|
||||
github.com/golang/snappy v0.0.0-20180518054509-2e65f85255db/go.mod h1:/XxbfmMg8lxefKM7IXC3fBNl/7bRcc72aCRzEWrmP2Q=
|
||||
github.com/gomodule/redigo v2.0.0+incompatible h1:K/R+8tc58AaqLkqG2Ol3Qk+DR/TlNuhuh457pBFPtt0=
|
||||
github.com/gomodule/redigo v2.0.0+incompatible/go.mod h1:B4C85qUVwatsJoIUNIfCRsp7qO0iAmpGFZ4EELWSbC4=
|
||||
github.com/hpcloud/tail v1.0.0 h1:nfCOvKYfkgYP8hkirhJocXT2+zOD8yUNjXaWfTlyFKI=
|
||||
github.com/hpcloud/tail v1.0.0/go.mod h1:ab1qPbhIpdTxEkNHXyeSf5vhxWSCs/tWer42PpOxQnU=
|
||||
github.com/lib/pq v1.0.0 h1:X5PMW56eZitiTeO7tKzZxFCSpbFZJtkMMooicw2us9A=
|
||||
github.com/lib/pq v1.0.0/go.mod h1:5WUZQaWbwv1U+lTReE5YruASi9Al49XbQIvNi/34Woo=
|
||||
github.com/mattn/go-sqlite3 v1.10.0 h1:jbhqpg7tQe4SupckyijYiy0mJJ/pRyHvXf7JdWK860o=
|
||||
github.com/mattn/go-sqlite3 v1.10.0/go.mod h1:FPy6KqzDD04eiIsT53CuJW3U88zkxoIYsOqkbpncsNc=
|
||||
github.com/onsi/ginkgo v1.6.0 h1:Ix8l273rp3QzYgXSR+c8d1fTG7UPgYkOSELPhiY/YGw=
|
||||
github.com/onsi/ginkgo v1.6.0/go.mod h1:lLunBs/Ym6LB5Z9jYTR76FiuTmxDTDusOGeTQH+WWjE=
|
||||
github.com/onsi/gomega v1.4.2 h1:3mYCb7aPxS/RU7TI1y4rkEn1oKmPRjNJLNEXgw7MH2I=
|
||||
github.com/onsi/gomega v1.4.2/go.mod h1:ex+gbHU/CVuBBDIJjb2X0qEXbFg53c61hWP/1CpauHY=
|
||||
github.com/pelletier/go-toml v1.2.0 h1:T5zMGML61Wp+FlcbWjRDT7yAxhJNAiPPLOFECq181zc=
|
||||
github.com/pelletier/go-toml v1.2.0/go.mod h1:5z9KED0ma1S8pY6P1sdut58dfprrGBbd/94hg7ilaic=
|
||||
github.com/pkg/errors v0.8.0 h1:WdK/asTD0HN+q6hsWO3/vpuAkAr+tw6aNJNDFFf0+qw=
|
||||
github.com/pkg/errors v0.8.0/go.mod h1:bwawxfHBFNV+L2hUp1rHADufV3IMtnDRdf1r5NINEl0=
|
||||
github.com/pmezard/go-difflib v1.0.0 h1:4DBwDE0NGyQoBHbLQYPwSUPoCMWR5BEzIk/f1lZbAQM=
|
||||
github.com/pmezard/go-difflib v1.0.0/go.mod h1:iKH77koFhYxTK1pcRnkKkqfTogsbg7gZNVY4sRDYZ/4=
|
||||
github.com/siddontang/go v0.0.0-20180604090527-bdc77568d726 h1:xT+JlYxNGqyT+XcU8iUrN18JYed2TvG9yN5ULG2jATM=
|
||||
github.com/siddontang/go v0.0.0-20180604090527-bdc77568d726/go.mod h1:3yhqj7WBBfRhbBlzyOC3gUxftwsU0u8gqevxwIHQpMw=
|
||||
github.com/siddontang/ledisdb v0.0.0-20181029004158-becf5f38d373 h1:p6IxqQMjab30l4lb9mmkIkkcE1yv6o0SKbPhW5pxqHI=
|
||||
@@ -66,29 +54,14 @@ github.com/siddontang/rdb v0.0.0-20150307021120-fc89ed2e418d h1:NVwnfyR3rENtlz62
|
||||
github.com/siddontang/rdb v0.0.0-20150307021120-fc89ed2e418d/go.mod h1:AMEsy7v5z92TR1JKMkLLoaOQk++LVnOKL3ScbJ8GNGA=
|
||||
github.com/ssdb/gossdb v0.0.0-20180723034631-88f6b59b84ec h1:q6XVwXmKvCRHRqesF3cSv6lNqqHi0QWOvgDlSohg8UA=
|
||||
github.com/ssdb/gossdb v0.0.0-20180723034631-88f6b59b84ec/go.mod h1:QBvMkMya+gXctz3kmljlUCu/yB3GZ6oee+dUozsezQE=
|
||||
github.com/stretchr/testify v1.2.2 h1:bSDNvY7ZPG5RlJ8otE/7V6gMiyenm9RtJ7IUVIAoJ1w=
|
||||
github.com/stretchr/testify v1.2.2/go.mod h1:a8OnRcib4nhh0OaRAV+Yts87kKdq0PP7pXfy6kDkUVs=
|
||||
github.com/syndtr/goleveldb v0.0.0-20181105012736-f9080354173f h1:EEVjSRihF8NIbfyCcErpSpNHEKrY3s8EAwqiPENZZn8=
|
||||
github.com/syndtr/goleveldb v0.0.0-20181105012736-f9080354173f/go.mod h1:Z4AUp2Km+PwemOoO/VB5AOx9XSsIItzFjoJlOSiYmn0=
|
||||
github.com/syndtr/goleveldb v0.0.0-20181127023241-353a9fca669c h1:3eGShk3EQf5gJCYW+WzA0TEJQd37HLOmlYF7N0YJwv0=
|
||||
github.com/syndtr/goleveldb v0.0.0-20181127023241-353a9fca669c/go.mod h1:Z4AUp2Km+PwemOoO/VB5AOx9XSsIItzFjoJlOSiYmn0=
|
||||
github.com/wendal/errors v0.0.0-20130201093226-f66c77a7882b h1:0Ve0/CCjiAiyKddUMUn3RwIGlq2iTW4GuVzyoKBYO/8=
|
||||
github.com/wendal/errors v0.0.0-20130201093226-f66c77a7882b/go.mod h1:Q12BUT7DqIlHRmgv3RskH+UCM/4eqVMgI0EMmlSpAXc=
|
||||
golang.org/x/crypto v0.0.0-20180723164146-c126467f60eb h1:Ah9YqXLj6fEgeKqcmBuLCbAsrF3ScD7dJ/bYM0C6tXI=
|
||||
golang.org/x/crypto v0.0.0-20180723164146-c126467f60eb/go.mod h1:6SG95UA2DQfeDnfUPMdvaQW0Q7yPrPDi9nlGo2tz2b4=
|
||||
golang.org/x/net v0.0.0-20180906233101-161cd47e91fd h1:nTDtHvHSdCn1m6ITfMRqtOd/9+7a3s8RBNOZ3eYZzJA=
|
||||
golang.org/x/net v0.0.0-20180906233101-161cd47e91fd/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
|
||||
golang.org/x/sync v0.0.0-20180314180146-1d60e4601c6f h1:wMNYb4v58l5UBM7MYRLPG6ZhfOqbKu7X5eyFl8ZhKvA=
|
||||
golang.org/x/sync v0.0.0-20180314180146-1d60e4601c6f/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
golang.org/x/sys v0.0.0-20180909124046-d0be0721c37e h1:o3PsSEY8E4eXWkXrIP9YJALUkVZqzHJT5DOasTyn8Vs=
|
||||
golang.org/x/sys v0.0.0-20180909124046-d0be0721c37e/go.mod h1:STP8DvDyc/dI5b8T5hshtkjS+E42TnysNCUPdjciGhY=
|
||||
golang.org/x/text v0.3.0 h1:g61tztE5qeGQ89tm6NTjjM9VPIm088od1l6aSorWRWg=
|
||||
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
|
||||
google.golang.org/appengine v1.1.0 h1:igQkv0AAhEIvTEpD5LIpAfav2eeVO9HBTjvKHVJPRSs=
|
||||
google.golang.org/appengine v1.1.0/go.mod h1:EbEs0AVv82hx2wNQdGPgUI5lhzA/G0D9YwlJXL52JkM=
|
||||
gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405 h1:yhCVgyC4o1eVCa2tZl7eS0r+SDo693bJlVdllGtEeKM=
|
||||
golang.org/x/crypto v0.0.0-20181127143415-eb0de9b17e85 h1:et7+NAX3lLIk5qUCTA9QelBjGE/NkhzYw/mhnr0s7nI=
|
||||
golang.org/x/crypto v0.0.0-20181127143415-eb0de9b17e85/go.mod h1:6SG95UA2DQfeDnfUPMdvaQW0Q7yPrPDi9nlGo2tz2b4=
|
||||
golang.org/x/net v0.0.0-20181114220301-adae6a3d119a h1:gOpx8G595UYyvj8UK4+OFyY4rx037g3fmfhe5SasG3U=
|
||||
golang.org/x/net v0.0.0-20181114220301-adae6a3d119a/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
|
||||
gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||
gopkg.in/fsnotify.v1 v1.4.7 h1:xOHLXZwVvI9hhs+cLKq5+I5onOuwQLhQwiu63xxlHs4=
|
||||
gopkg.in/fsnotify.v1 v1.4.7/go.mod h1:Tz8NjZHkW78fSQdbUxIjBTcgA1z1m8ZHf0WmKUhAMys=
|
||||
gopkg.in/tomb.v1 v1.0.0-20141024135613-dd632973f1e7 h1:uRGJdciOHaEIrze2W8Q3AKkepLTh2hOroT7a+7czfdQ=
|
||||
gopkg.in/tomb.v1 v1.0.0-20141024135613-dd632973f1e7/go.mod h1:dt/ZhP58zS4L8KSrWDmTeBkI65Dw0HsyUHuEVlX15mw=
|
||||
gopkg.in/yaml.v2 v2.2.1 h1:mUhvW9EsL+naU5Q3cakzfE91YhliOondGd6ZrsDBHQE=
|
||||
gopkg.in/yaml.v2 v2.2.1/go.mod h1:hI93XBmqTisBFMUTm0b8Fm+jr3Dg1NNxqwp+5A1VGuI=
|
||||
|
||||
2
hooks.go
2
hooks.go
@@ -11,7 +11,7 @@ import (
|
||||
"github.com/astaxie/beego/session"
|
||||
)
|
||||
|
||||
//
|
||||
// register MIME type with content type
|
||||
func registerMime() error {
|
||||
for k, v := range mimemaps {
|
||||
mime.AddExtensionType(k, v)
|
||||
|
||||
42
orm/db.go
42
orm/db.go
@@ -762,7 +762,13 @@ func (d *dbBase) UpdateBatch(q dbQuerier, qs *querySet, mi *modelInfo, cond *Con
|
||||
}
|
||||
|
||||
d.ins.ReplaceMarks(&query)
|
||||
res, err := q.Exec(query, values...)
|
||||
var err error
|
||||
var res sql.Result
|
||||
if qs != nil && qs.forContext {
|
||||
res, err = q.ExecContext(qs.ctx, query, values...)
|
||||
} else {
|
||||
res, err = q.Exec(query, values...)
|
||||
}
|
||||
if err == nil {
|
||||
return res.RowsAffected()
|
||||
}
|
||||
@@ -851,11 +857,16 @@ func (d *dbBase) DeleteBatch(q dbQuerier, qs *querySet, mi *modelInfo, cond *Con
|
||||
for i := range marks {
|
||||
marks[i] = "?"
|
||||
}
|
||||
sql := fmt.Sprintf("IN (%s)", strings.Join(marks, ", "))
|
||||
query = fmt.Sprintf("DELETE FROM %s%s%s WHERE %s%s%s %s", Q, mi.table, Q, Q, mi.fields.pk.column, Q, sql)
|
||||
sqlIn := fmt.Sprintf("IN (%s)", strings.Join(marks, ", "))
|
||||
query = fmt.Sprintf("DELETE FROM %s%s%s WHERE %s%s%s %s", Q, mi.table, Q, Q, mi.fields.pk.column, Q, sqlIn)
|
||||
|
||||
d.ins.ReplaceMarks(&query)
|
||||
res, err := q.Exec(query, args...)
|
||||
var res sql.Result
|
||||
if qs != nil && qs.forContext {
|
||||
res, err = q.ExecContext(qs.ctx, query, args...)
|
||||
} else {
|
||||
res, err = q.Exec(query, args...)
|
||||
}
|
||||
if err == nil {
|
||||
num, err := res.RowsAffected()
|
||||
if err != nil {
|
||||
@@ -978,11 +989,18 @@ func (d *dbBase) ReadBatch(q dbQuerier, qs *querySet, mi *modelInfo, cond *Condi
|
||||
d.ins.ReplaceMarks(&query)
|
||||
|
||||
var rs *sql.Rows
|
||||
r, err := q.Query(query, args...)
|
||||
if err != nil {
|
||||
return 0, err
|
||||
var err error
|
||||
if qs != nil && qs.forContext {
|
||||
rs, err = q.QueryContext(qs.ctx, query, args...)
|
||||
if err != nil {
|
||||
return 0, err
|
||||
}
|
||||
} else {
|
||||
rs, err = q.Query(query, args...)
|
||||
if err != nil {
|
||||
return 0, err
|
||||
}
|
||||
}
|
||||
rs = r
|
||||
|
||||
refs := make([]interface{}, colsNum)
|
||||
for i := range refs {
|
||||
@@ -1111,8 +1129,12 @@ func (d *dbBase) Count(q dbQuerier, qs *querySet, mi *modelInfo, cond *Condition
|
||||
|
||||
d.ins.ReplaceMarks(&query)
|
||||
|
||||
row := q.QueryRow(query, args...)
|
||||
|
||||
var row *sql.Row
|
||||
if qs != nil && qs.forContext {
|
||||
row = q.QueryRowContext(qs.ctx, query, args...)
|
||||
} else {
|
||||
row = q.QueryRow(query, args...)
|
||||
}
|
||||
err = row.Scan(&cnt)
|
||||
return
|
||||
}
|
||||
|
||||
@@ -109,7 +109,7 @@ func getTableUnique(val reflect.Value) [][]string {
|
||||
func getColumnName(ft int, addrField reflect.Value, sf reflect.StructField, col string) string {
|
||||
column := col
|
||||
if col == "" {
|
||||
column = snakeString(sf.Name)
|
||||
column = nameStrategyMap[nameStrategy](sf.Name)
|
||||
}
|
||||
switch ft {
|
||||
case RelForeignKey, RelOneToOne:
|
||||
|
||||
@@ -425,7 +425,7 @@ func (o *orm) getRelQs(md interface{}, mi *modelInfo, fi *fieldInfo) *querySet {
|
||||
func (o *orm) QueryTable(ptrStructOrTableName interface{}) (qs QuerySeter) {
|
||||
var name string
|
||||
if table, ok := ptrStructOrTableName.(string); ok {
|
||||
name = snakeString(table)
|
||||
name = nameStrategyMap[defaultNameStrategy](table)
|
||||
if mi, ok := modelCache.get(name); ok {
|
||||
qs = newQuerySet(o, mi)
|
||||
}
|
||||
@@ -549,7 +549,7 @@ func NewOrmWithDB(driverName, aliasName string, db *sql.DB) (Ormer, error) {
|
||||
al.Name = aliasName
|
||||
al.DriverName = driverName
|
||||
al.DB = db
|
||||
|
||||
|
||||
detectTZ(al)
|
||||
|
||||
o := new(orm)
|
||||
|
||||
@@ -123,6 +123,13 @@ func (d *dbQueryLog) Prepare(query string) (*sql.Stmt, error) {
|
||||
return stmt, err
|
||||
}
|
||||
|
||||
func (d *dbQueryLog) PrepareContext(ctx context.Context, query string) (*sql.Stmt, error) {
|
||||
a := time.Now()
|
||||
stmt, err := d.db.PrepareContext(ctx, query)
|
||||
debugLogQueies(d.alias, "db.Prepare", query, a, err)
|
||||
return stmt, err
|
||||
}
|
||||
|
||||
func (d *dbQueryLog) Exec(query string, args ...interface{}) (sql.Result, error) {
|
||||
a := time.Now()
|
||||
res, err := d.db.Exec(query, args...)
|
||||
@@ -130,6 +137,13 @@ func (d *dbQueryLog) Exec(query string, args ...interface{}) (sql.Result, error)
|
||||
return res, err
|
||||
}
|
||||
|
||||
func (d *dbQueryLog) ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error) {
|
||||
a := time.Now()
|
||||
res, err := d.db.ExecContext(ctx, query, args...)
|
||||
debugLogQueies(d.alias, "db.Exec", query, a, err, args...)
|
||||
return res, err
|
||||
}
|
||||
|
||||
func (d *dbQueryLog) Query(query string, args ...interface{}) (*sql.Rows, error) {
|
||||
a := time.Now()
|
||||
res, err := d.db.Query(query, args...)
|
||||
@@ -137,6 +151,13 @@ func (d *dbQueryLog) Query(query string, args ...interface{}) (*sql.Rows, error)
|
||||
return res, err
|
||||
}
|
||||
|
||||
func (d *dbQueryLog) QueryContext(ctx context.Context, query string, args ...interface{}) (*sql.Rows, error) {
|
||||
a := time.Now()
|
||||
res, err := d.db.QueryContext(ctx, query, args...)
|
||||
debugLogQueies(d.alias, "db.Query", query, a, err, args...)
|
||||
return res, err
|
||||
}
|
||||
|
||||
func (d *dbQueryLog) QueryRow(query string, args ...interface{}) *sql.Row {
|
||||
a := time.Now()
|
||||
res := d.db.QueryRow(query, args...)
|
||||
@@ -144,6 +165,13 @@ func (d *dbQueryLog) QueryRow(query string, args ...interface{}) *sql.Row {
|
||||
return res
|
||||
}
|
||||
|
||||
func (d *dbQueryLog) QueryRowContext(ctx context.Context, query string, args ...interface{}) *sql.Row {
|
||||
a := time.Now()
|
||||
res := d.db.QueryRowContext(ctx, query, args...)
|
||||
debugLogQueies(d.alias, "db.QueryRow", query, a, nil, args...)
|
||||
return res
|
||||
}
|
||||
|
||||
func (d *dbQueryLog) Begin() (*sql.Tx, error) {
|
||||
a := time.Now()
|
||||
tx, err := d.db.(txer).Begin()
|
||||
|
||||
@@ -15,6 +15,7 @@
|
||||
package orm
|
||||
|
||||
import (
|
||||
"context"
|
||||
"fmt"
|
||||
)
|
||||
|
||||
@@ -55,17 +56,19 @@ func ColValue(opt operator, value interface{}) interface{} {
|
||||
|
||||
// real query struct
|
||||
type querySet struct {
|
||||
mi *modelInfo
|
||||
cond *Condition
|
||||
related []string
|
||||
relDepth int
|
||||
limit int64
|
||||
offset int64
|
||||
groups []string
|
||||
orders []string
|
||||
distinct bool
|
||||
forupdate bool
|
||||
orm *orm
|
||||
mi *modelInfo
|
||||
cond *Condition
|
||||
related []string
|
||||
relDepth int
|
||||
limit int64
|
||||
offset int64
|
||||
groups []string
|
||||
orders []string
|
||||
distinct bool
|
||||
forupdate bool
|
||||
orm *orm
|
||||
ctx context.Context
|
||||
forContext bool
|
||||
}
|
||||
|
||||
var _ QuerySeter = new(querySet)
|
||||
@@ -275,6 +278,13 @@ func (o *querySet) RowsToStruct(ptrStruct interface{}, keyCol, valueCol string)
|
||||
panic(ErrNotImplement)
|
||||
}
|
||||
|
||||
// set context to QuerySeter.
|
||||
func (o querySet) WithContext(ctx context.Context) QuerySeter {
|
||||
o.ctx = ctx
|
||||
o.forContext = true
|
||||
return &o
|
||||
}
|
||||
|
||||
// create new QuerySeter.
|
||||
func newQuerySet(orm *orm, mi *modelInfo) QuerySeter {
|
||||
o := new(querySet)
|
||||
|
||||
@@ -358,7 +358,7 @@ func (o *rawSet) QueryRow(containers ...interface{}) error {
|
||||
_, tags := parseStructTag(fe.Tag.Get(defaultStructTagName))
|
||||
var col string
|
||||
if col = tags["column"]; col == "" {
|
||||
col = snakeString(fe.Name)
|
||||
col = nameStrategyMap[nameStrategy](fe.Name)
|
||||
}
|
||||
if v, ok := columnsMp[col]; ok {
|
||||
value := reflect.ValueOf(v).Elem().Interface()
|
||||
@@ -509,7 +509,7 @@ func (o *rawSet) QueryRows(containers ...interface{}) (int64, error) {
|
||||
_, tags := parseStructTag(fe.Tag.Get(defaultStructTagName))
|
||||
var col string
|
||||
if col = tags["column"]; col == "" {
|
||||
col = snakeString(fe.Name)
|
||||
col = nameStrategyMap[nameStrategy](fe.Name)
|
||||
}
|
||||
if v, ok := columnsMp[col]; ok {
|
||||
value := reflect.ValueOf(v).Elem().Interface()
|
||||
|
||||
@@ -395,16 +395,23 @@ type RawSeter interface {
|
||||
type stmtQuerier interface {
|
||||
Close() error
|
||||
Exec(args ...interface{}) (sql.Result, error)
|
||||
//ExecContext(ctx context.Context, args ...interface{}) (sql.Result, error)
|
||||
Query(args ...interface{}) (*sql.Rows, error)
|
||||
//QueryContext(args ...interface{}) (*sql.Rows, error)
|
||||
QueryRow(args ...interface{}) *sql.Row
|
||||
//QueryRowContext(ctx context.Context, args ...interface{}) *sql.Row
|
||||
}
|
||||
|
||||
// db querier
|
||||
type dbQuerier interface {
|
||||
Prepare(query string) (*sql.Stmt, error)
|
||||
PrepareContext(ctx context.Context, query string) (*sql.Stmt, error)
|
||||
Exec(query string, args ...interface{}) (sql.Result, error)
|
||||
ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error)
|
||||
Query(query string, args ...interface{}) (*sql.Rows, error)
|
||||
QueryContext(ctx context.Context, query string, args ...interface{}) (*sql.Rows, error)
|
||||
QueryRow(query string, args ...interface{}) *sql.Row
|
||||
QueryRowContext(ctx context.Context, query string, args ...interface{}) *sql.Row
|
||||
}
|
||||
|
||||
// type DB interface {
|
||||
|
||||
41
orm/utils.go
41
orm/utils.go
@@ -23,6 +23,18 @@ import (
|
||||
"time"
|
||||
)
|
||||
|
||||
type fn func(string) string
|
||||
|
||||
var (
|
||||
nameStrategyMap = map[string]fn{
|
||||
defaultNameStrategy: snakeString,
|
||||
SnakeAcronymNameStrategy: snakeStringWithAcronym,
|
||||
}
|
||||
defaultNameStrategy = "snakeString"
|
||||
SnakeAcronymNameStrategy = "snakeStringWithAcronym"
|
||||
nameStrategy = defaultNameStrategy
|
||||
)
|
||||
|
||||
// StrTo is the target string
|
||||
type StrTo string
|
||||
|
||||
@@ -198,6 +210,27 @@ func ToInt64(value interface{}) (d int64) {
|
||||
return
|
||||
}
|
||||
|
||||
func snakeStringWithAcronym(s string) string {
|
||||
data := make([]byte, 0, len(s)*2)
|
||||
num := len(s)
|
||||
for i := 0; i < num; i++ {
|
||||
d := s[i]
|
||||
before := false
|
||||
after := false
|
||||
if i > 0 {
|
||||
before = s[i-1] >= 'a' && s[i-1] <= 'z'
|
||||
}
|
||||
if i+1 < num {
|
||||
after = s[i+1] >= 'a' && s[i+1] <= 'z'
|
||||
}
|
||||
if i > 0 && d >= 'A' && d <= 'Z' && (before || after) {
|
||||
data = append(data, '_')
|
||||
}
|
||||
data = append(data, d)
|
||||
}
|
||||
return strings.ToLower(string(data[:]))
|
||||
}
|
||||
|
||||
// snake string, XxYy to xx_yy , XxYY to xx_y_y
|
||||
func snakeString(s string) string {
|
||||
data := make([]byte, 0, len(s)*2)
|
||||
@@ -216,6 +249,14 @@ func snakeString(s string) string {
|
||||
return strings.ToLower(string(data[:]))
|
||||
}
|
||||
|
||||
// SetNameStrategy set different name strategy
|
||||
func SetNameStrategy(s string) {
|
||||
if SnakeAcronymNameStrategy != s {
|
||||
nameStrategy = defaultNameStrategy
|
||||
}
|
||||
nameStrategy = s
|
||||
}
|
||||
|
||||
// camel string, xx_yy to XxYy
|
||||
func camelString(s string) string {
|
||||
data := make([]byte, 0, len(s))
|
||||
|
||||
@@ -51,3 +51,20 @@ func TestSnakeString(t *testing.T) {
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestSnakeStringWithAcronym(t *testing.T) {
|
||||
camel := []string{"ID", "PicURL", "HelloWorld", "HelloWorld", "HelLOWord", "PicUrl1", "XyXX"}
|
||||
snake := []string{"id", "pic_url", "hello_world", "hello_world", "hel_lo_word", "pic_url1", "xy_xx"}
|
||||
|
||||
answer := make(map[string]string)
|
||||
for i, v := range camel {
|
||||
answer[v] = snake[i]
|
||||
}
|
||||
|
||||
for _, v := range camel {
|
||||
res := snakeStringWithAcronym(v)
|
||||
if res != answer[v] {
|
||||
t.Error("Unit Test Fail:", v, res, answer[v])
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
15
router.go
15
router.go
@@ -133,14 +133,15 @@ type ControllerRegister struct {
|
||||
|
||||
// NewControllerRegister returns a new ControllerRegister.
|
||||
func NewControllerRegister() *ControllerRegister {
|
||||
cr := &ControllerRegister{
|
||||
return &ControllerRegister{
|
||||
routers: make(map[string]*Tree),
|
||||
policies: make(map[string]*Tree),
|
||||
pool: sync.Pool{
|
||||
New: func() interface{} {
|
||||
return beecontext.NewContext()
|
||||
},
|
||||
},
|
||||
}
|
||||
cr.pool.New = func() interface{} {
|
||||
return beecontext.NewContext()
|
||||
}
|
||||
return cr
|
||||
}
|
||||
|
||||
// Add controller handler and pattern rules to ControllerRegister.
|
||||
@@ -890,8 +891,9 @@ Admin:
|
||||
|
||||
logAccess(context, &startTime, statusCode)
|
||||
|
||||
timeDur := time.Since(startTime)
|
||||
context.ResponseWriter.Elapsed = timeDur
|
||||
if BConfig.Listen.EnableAdmin {
|
||||
timeDur := time.Since(startTime)
|
||||
pattern := ""
|
||||
if routerInfo != nil {
|
||||
pattern = routerInfo.pattern
|
||||
@@ -908,7 +910,6 @@ Admin:
|
||||
|
||||
if BConfig.RunMode == DEV && !BConfig.Log.AccessLogs {
|
||||
var devInfo string
|
||||
timeDur := time.Since(startTime)
|
||||
iswin := (runtime.GOOS == "windows")
|
||||
statusColor := logs.ColorByStatus(iswin, statusCode)
|
||||
methodColor := logs.ColorByMethod(iswin, r.Method)
|
||||
|
||||
@@ -186,13 +186,13 @@ func BuildTemplate(dir string, files ...string) error {
|
||||
var err error
|
||||
fs := beeTemplateFS()
|
||||
f, err := fs.Open(dir)
|
||||
defer f.Close()
|
||||
if err != nil {
|
||||
if os.IsNotExist(err) {
|
||||
return nil
|
||||
}
|
||||
return errors.New("dir open err")
|
||||
}
|
||||
defer f.Close()
|
||||
|
||||
beeTemplates, ok := beeViewPathTemplates[dir]
|
||||
if !ok {
|
||||
@@ -361,6 +361,8 @@ type templateFSFunc func() http.FileSystem
|
||||
func defaultFSFunc() http.FileSystem {
|
||||
return FileSystem{}
|
||||
}
|
||||
|
||||
// SetTemplateFSFunc set default filesystem function
|
||||
func SetTemplateFSFunc(fnt templateFSFunc) {
|
||||
beeTemplateFS = fnt
|
||||
}
|
||||
|
||||
28
vendor/github.com/Knetic/govaluate/.gitignore
generated
vendored
28
vendor/github.com/Knetic/govaluate/.gitignore
generated
vendored
@@ -1,28 +0,0 @@
|
||||
# Compiled Object files, Static and Dynamic libs (Shared Objects)
|
||||
*.o
|
||||
*.a
|
||||
*.so
|
||||
|
||||
# Folders
|
||||
_obj
|
||||
_test
|
||||
|
||||
# Architecture specific extensions/prefixes
|
||||
*.[568vq]
|
||||
[568vq].out
|
||||
|
||||
*.cgo1.go
|
||||
*.cgo2.c
|
||||
_cgo_defun.c
|
||||
_cgo_gotypes.go
|
||||
_cgo_export.*
|
||||
|
||||
_testmain.go
|
||||
|
||||
*.exe
|
||||
*.test
|
||||
coverage.out
|
||||
|
||||
manual_test.go
|
||||
*.out
|
||||
*.err
|
||||
10
vendor/github.com/Knetic/govaluate/.travis.yml
generated
vendored
10
vendor/github.com/Knetic/govaluate/.travis.yml
generated
vendored
@@ -1,10 +0,0 @@
|
||||
language: go
|
||||
|
||||
script: ./test.sh
|
||||
|
||||
go:
|
||||
- 1.2
|
||||
- 1.3
|
||||
- 1.4
|
||||
- 1.5
|
||||
- 1.6
|
||||
12
vendor/github.com/Knetic/govaluate/CONTRIBUTORS
generated
vendored
12
vendor/github.com/Knetic/govaluate/CONTRIBUTORS
generated
vendored
@@ -1,12 +0,0 @@
|
||||
This library was authored by George Lester, and contains contributions from:
|
||||
|
||||
vjeantet (regex support)
|
||||
iasci (ternary operator)
|
||||
oxtoacart (parameter structures, deferred parameter retrieval)
|
||||
wmiller848 (bitwise operators)
|
||||
prashantv (optimization of bools)
|
||||
dpaolella (exposure of variables used in an expression)
|
||||
benpaxton (fix for missing type checks during literal elide process)
|
||||
abrander (panic-finding testing tool)
|
||||
xfennec (fix for dates being parsed in the current Location)
|
||||
bgaifullin (lifting restriction on complex/struct types)
|
||||
272
vendor/github.com/Knetic/govaluate/EvaluableExpression.go
generated
vendored
272
vendor/github.com/Knetic/govaluate/EvaluableExpression.go
generated
vendored
@@ -1,272 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
)
|
||||
|
||||
const isoDateFormat string = "2006-01-02T15:04:05.999999999Z0700"
|
||||
const shortCircuitHolder int = -1
|
||||
|
||||
var DUMMY_PARAMETERS = MapParameters(map[string]interface{}{})
|
||||
|
||||
/*
|
||||
EvaluableExpression represents a set of ExpressionTokens which, taken together,
|
||||
are an expression that can be evaluated down into a single value.
|
||||
*/
|
||||
type EvaluableExpression struct {
|
||||
|
||||
/*
|
||||
Represents the query format used to output dates. Typically only used when creating SQL or Mongo queries from an expression.
|
||||
Defaults to the complete ISO8601 format, including nanoseconds.
|
||||
*/
|
||||
QueryDateFormat string
|
||||
|
||||
/*
|
||||
Whether or not to safely check types when evaluating.
|
||||
If true, this library will return error messages when invalid types are used.
|
||||
If false, the library will panic when operators encounter types they can't use.
|
||||
|
||||
This is exclusively for users who need to squeeze every ounce of speed out of the library as they can,
|
||||
and you should only set this to false if you know exactly what you're doing.
|
||||
*/
|
||||
ChecksTypes bool
|
||||
|
||||
tokens []ExpressionToken
|
||||
evaluationStages *evaluationStage
|
||||
inputExpression string
|
||||
}
|
||||
|
||||
/*
|
||||
Parses a new EvaluableExpression from the given [expression] string.
|
||||
Returns an error if the given expression has invalid syntax.
|
||||
*/
|
||||
func NewEvaluableExpression(expression string) (*EvaluableExpression, error) {
|
||||
|
||||
functions := make(map[string]ExpressionFunction)
|
||||
return NewEvaluableExpressionWithFunctions(expression, functions)
|
||||
}
|
||||
|
||||
/*
|
||||
Similar to [NewEvaluableExpression], except that instead of a string, an already-tokenized expression is given.
|
||||
This is useful in cases where you may be generating an expression automatically, or using some other parser (e.g., to parse from a query language)
|
||||
*/
|
||||
func NewEvaluableExpressionFromTokens(tokens []ExpressionToken) (*EvaluableExpression, error) {
|
||||
|
||||
var ret *EvaluableExpression
|
||||
var err error
|
||||
|
||||
ret = new(EvaluableExpression)
|
||||
ret.QueryDateFormat = isoDateFormat
|
||||
|
||||
err = checkBalance(tokens)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
err = checkExpressionSyntax(tokens)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
ret.tokens, err = optimizeTokens(tokens)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
ret.evaluationStages, err = planStages(ret.tokens)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
ret.ChecksTypes = true
|
||||
return ret, nil
|
||||
}
|
||||
|
||||
/*
|
||||
Similar to [NewEvaluableExpression], except enables the use of user-defined functions.
|
||||
Functions passed into this will be available to the expression.
|
||||
*/
|
||||
func NewEvaluableExpressionWithFunctions(expression string, functions map[string]ExpressionFunction) (*EvaluableExpression, error) {
|
||||
|
||||
var ret *EvaluableExpression
|
||||
var err error
|
||||
|
||||
ret = new(EvaluableExpression)
|
||||
ret.QueryDateFormat = isoDateFormat
|
||||
ret.inputExpression = expression
|
||||
|
||||
ret.tokens, err = parseTokens(expression, functions)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
err = checkBalance(ret.tokens)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
err = checkExpressionSyntax(ret.tokens)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
ret.tokens, err = optimizeTokens(ret.tokens)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
ret.evaluationStages, err = planStages(ret.tokens)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
ret.ChecksTypes = true
|
||||
return ret, nil
|
||||
}
|
||||
|
||||
/*
|
||||
Same as `Eval`, but automatically wraps a map of parameters into a `govalute.Parameters` structure.
|
||||
*/
|
||||
func (this EvaluableExpression) Evaluate(parameters map[string]interface{}) (interface{}, error) {
|
||||
|
||||
if parameters == nil {
|
||||
return this.Eval(nil)
|
||||
}
|
||||
return this.Eval(MapParameters(parameters))
|
||||
}
|
||||
|
||||
/*
|
||||
Runs the entire expression using the given [parameters].
|
||||
e.g., If the expression contains a reference to the variable "foo", it will be taken from `parameters.Get("foo")`.
|
||||
|
||||
This function returns errors if the combination of expression and parameters cannot be run,
|
||||
such as if a variable in the expression is not present in [parameters].
|
||||
|
||||
In all non-error circumstances, this returns the single value result of the expression and parameters given.
|
||||
e.g., if the expression is "1 + 1", this will return 2.0.
|
||||
e.g., if the expression is "foo + 1" and parameters contains "foo" = 2, this will return 3.0
|
||||
*/
|
||||
func (this EvaluableExpression) Eval(parameters Parameters) (interface{}, error) {
|
||||
|
||||
if this.evaluationStages == nil {
|
||||
return nil, nil
|
||||
}
|
||||
|
||||
if parameters != nil {
|
||||
parameters = &sanitizedParameters{parameters}
|
||||
}
|
||||
return this.evaluateStage(this.evaluationStages, parameters)
|
||||
}
|
||||
|
||||
func (this EvaluableExpression) evaluateStage(stage *evaluationStage, parameters Parameters) (interface{}, error) {
|
||||
|
||||
var left, right interface{}
|
||||
var err error
|
||||
|
||||
if stage.leftStage != nil {
|
||||
left, err = this.evaluateStage(stage.leftStage, parameters)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
}
|
||||
|
||||
if stage.isShortCircuitable() {
|
||||
switch stage.symbol {
|
||||
case AND:
|
||||
if left == false {
|
||||
return false, nil
|
||||
}
|
||||
case OR:
|
||||
if left == true {
|
||||
return true, nil
|
||||
}
|
||||
case COALESCE:
|
||||
if left != nil {
|
||||
return left, nil
|
||||
}
|
||||
|
||||
case TERNARY_TRUE:
|
||||
if left == false {
|
||||
right = shortCircuitHolder
|
||||
}
|
||||
case TERNARY_FALSE:
|
||||
if left != nil {
|
||||
right = shortCircuitHolder
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if right != shortCircuitHolder && stage.rightStage != nil {
|
||||
right, err = this.evaluateStage(stage.rightStage, parameters)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
}
|
||||
|
||||
if this.ChecksTypes {
|
||||
if stage.typeCheck == nil {
|
||||
|
||||
err = typeCheck(stage.leftTypeCheck, left, stage.symbol, stage.typeErrorFormat)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
err = typeCheck(stage.rightTypeCheck, right, stage.symbol, stage.typeErrorFormat)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
} else {
|
||||
// special case where the type check needs to know both sides to determine if the operator can handle it
|
||||
if !stage.typeCheck(left, right) {
|
||||
errorMsg := fmt.Sprintf(stage.typeErrorFormat, left, stage.symbol.String())
|
||||
return nil, errors.New(errorMsg)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return stage.operator(left, right, parameters)
|
||||
}
|
||||
|
||||
func typeCheck(check stageTypeCheck, value interface{}, symbol OperatorSymbol, format string) error {
|
||||
|
||||
if check == nil {
|
||||
return nil
|
||||
}
|
||||
|
||||
if check(value) {
|
||||
return nil
|
||||
}
|
||||
|
||||
errorMsg := fmt.Sprintf(format, value, symbol.String())
|
||||
return errors.New(errorMsg)
|
||||
}
|
||||
|
||||
/*
|
||||
Returns an array representing the ExpressionTokens that make up this expression.
|
||||
*/
|
||||
func (this EvaluableExpression) Tokens() []ExpressionToken {
|
||||
|
||||
return this.tokens
|
||||
}
|
||||
|
||||
/*
|
||||
Returns the original expression used to create this EvaluableExpression.
|
||||
*/
|
||||
func (this EvaluableExpression) String() string {
|
||||
|
||||
return this.inputExpression
|
||||
}
|
||||
|
||||
/*
|
||||
Returns an array representing the variables contained in this EvaluableExpression.
|
||||
*/
|
||||
func (this EvaluableExpression) Vars() []string {
|
||||
var varlist []string
|
||||
for _, val := range this.Tokens() {
|
||||
if val.Kind == VARIABLE {
|
||||
varlist = append(varlist, val.Value.(string))
|
||||
}
|
||||
}
|
||||
return varlist
|
||||
}
|
||||
167
vendor/github.com/Knetic/govaluate/EvaluableExpression_sql.go
generated
vendored
167
vendor/github.com/Knetic/govaluate/EvaluableExpression_sql.go
generated
vendored
@@ -1,167 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"regexp"
|
||||
"time"
|
||||
)
|
||||
|
||||
/*
|
||||
Returns a string representing this expression as if it were written in SQL.
|
||||
This function assumes that all parameters exist within the same table, and that the table essentially represents
|
||||
a serialized object of some sort (e.g., hibernate).
|
||||
If your data model is more normalized, you may need to consider iterating through each actual token given by `Tokens()`
|
||||
to create your query.
|
||||
|
||||
Boolean values are considered to be "1" for true, "0" for false.
|
||||
|
||||
Times are formatted according to this.QueryDateFormat.
|
||||
*/
|
||||
func (this EvaluableExpression) ToSQLQuery() (string, error) {
|
||||
|
||||
var stream *tokenStream
|
||||
var transactions *expressionOutputStream
|
||||
var transaction string
|
||||
var err error
|
||||
|
||||
stream = newTokenStream(this.tokens)
|
||||
transactions = new(expressionOutputStream)
|
||||
|
||||
for stream.hasNext() {
|
||||
|
||||
transaction, err = this.findNextSQLString(stream, transactions)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
transactions.add(transaction)
|
||||
}
|
||||
|
||||
return transactions.createString(" "), nil
|
||||
}
|
||||
|
||||
func (this EvaluableExpression) findNextSQLString(stream *tokenStream, transactions *expressionOutputStream) (string, error) {
|
||||
|
||||
var token ExpressionToken
|
||||
var ret string
|
||||
|
||||
token = stream.next()
|
||||
|
||||
switch token.Kind {
|
||||
|
||||
case STRING:
|
||||
ret = fmt.Sprintf("'%v'", token.Value)
|
||||
case PATTERN:
|
||||
ret = fmt.Sprintf("'%s'", token.Value.(*regexp.Regexp).String())
|
||||
case TIME:
|
||||
ret = fmt.Sprintf("'%s'", token.Value.(time.Time).Format(this.QueryDateFormat))
|
||||
|
||||
case LOGICALOP:
|
||||
switch logicalSymbols[token.Value.(string)] {
|
||||
|
||||
case AND:
|
||||
ret = "AND"
|
||||
case OR:
|
||||
ret = "OR"
|
||||
}
|
||||
|
||||
case BOOLEAN:
|
||||
if token.Value.(bool) {
|
||||
ret = "1"
|
||||
} else {
|
||||
ret = "0"
|
||||
}
|
||||
|
||||
case VARIABLE:
|
||||
ret = fmt.Sprintf("[%s]", token.Value.(string))
|
||||
|
||||
case NUMERIC:
|
||||
ret = fmt.Sprintf("%g", token.Value.(float64))
|
||||
|
||||
case COMPARATOR:
|
||||
switch comparatorSymbols[token.Value.(string)] {
|
||||
|
||||
case EQ:
|
||||
ret = "="
|
||||
case NEQ:
|
||||
ret = "<>"
|
||||
case REQ:
|
||||
ret = "RLIKE"
|
||||
case NREQ:
|
||||
ret = "NOT RLIKE"
|
||||
default:
|
||||
ret = fmt.Sprintf("%s", token.Value.(string))
|
||||
}
|
||||
|
||||
case TERNARY:
|
||||
|
||||
switch ternarySymbols[token.Value.(string)] {
|
||||
|
||||
case COALESCE:
|
||||
|
||||
left := transactions.rollback()
|
||||
right, err := this.findNextSQLString(stream, transactions)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
ret = fmt.Sprintf("COALESCE(%v, %v)", left, right)
|
||||
case TERNARY_TRUE:
|
||||
fallthrough
|
||||
case TERNARY_FALSE:
|
||||
return "", errors.New("Ternary operators are unsupported in SQL output")
|
||||
}
|
||||
case PREFIX:
|
||||
switch prefixSymbols[token.Value.(string)] {
|
||||
|
||||
case INVERT:
|
||||
ret = fmt.Sprintf("NOT")
|
||||
default:
|
||||
|
||||
right, err := this.findNextSQLString(stream, transactions)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
ret = fmt.Sprintf("%s%s", token.Value.(string), right)
|
||||
}
|
||||
case MODIFIER:
|
||||
|
||||
switch modifierSymbols[token.Value.(string)] {
|
||||
|
||||
case EXPONENT:
|
||||
|
||||
left := transactions.rollback()
|
||||
right, err := this.findNextSQLString(stream, transactions)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
ret = fmt.Sprintf("POW(%s, %s)", left, right)
|
||||
case MODULUS:
|
||||
|
||||
left := transactions.rollback()
|
||||
right, err := this.findNextSQLString(stream, transactions)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
ret = fmt.Sprintf("MOD(%s, %s)", left, right)
|
||||
default:
|
||||
ret = fmt.Sprintf("%s", token.Value.(string))
|
||||
}
|
||||
case CLAUSE:
|
||||
ret = "("
|
||||
case CLAUSE_CLOSE:
|
||||
ret = ")"
|
||||
case SEPARATOR:
|
||||
ret = ","
|
||||
|
||||
default:
|
||||
errorMsg := fmt.Sprintf("Unrecognized query token '%s' of kind '%s'", token.Value, token.Kind)
|
||||
return "", errors.New(errorMsg)
|
||||
}
|
||||
|
||||
return ret, nil
|
||||
}
|
||||
9
vendor/github.com/Knetic/govaluate/ExpressionToken.go
generated
vendored
9
vendor/github.com/Knetic/govaluate/ExpressionToken.go
generated
vendored
@@ -1,9 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
/*
|
||||
Represents a single parsed token.
|
||||
*/
|
||||
type ExpressionToken struct {
|
||||
Kind TokenKind
|
||||
Value interface{}
|
||||
}
|
||||
21
vendor/github.com/Knetic/govaluate/LICENSE
generated
vendored
21
vendor/github.com/Knetic/govaluate/LICENSE
generated
vendored
@@ -1,21 +0,0 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2014-2016 George Lester
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
176
vendor/github.com/Knetic/govaluate/MANUAL.md
generated
vendored
176
vendor/github.com/Knetic/govaluate/MANUAL.md
generated
vendored
@@ -1,176 +0,0 @@
|
||||
govaluate
|
||||
====
|
||||
|
||||
This library contains quite a lot of functionality, this document is meant to be formal documentation on the operators and features of it.
|
||||
Some of this documentation may duplicate what's in README.md, but should never conflict.
|
||||
|
||||
# Types
|
||||
|
||||
This library only officially deals with four types; `float64`, `bool`, `string`, and arrays.
|
||||
|
||||
All numeric literals, with or without a radix, will be converted to `float64` for evaluation. For instance; in practice, there is no difference between the literals "1.0" and "1", they both end up as `float64`. This matters to users because if you intend to return numeric values from your expressions, then the returned value will be `float64`, not any other numeric type.
|
||||
|
||||
Any string _literal_ (not parameter) which is interpretable as a date will be converted to a `float64` representation of that date's unix time. Any `time.Time` parameters will not be operable with these date literals; such parameters will need to use the `time.Time.Unix()` method to get a numeric representation.
|
||||
|
||||
Arrays are untyped, and can be mixed-type. Internally they're all just `interface{}`. Only two operators can interact with arrays, `IN` and `,`. All other operators will refuse to operate on arrays.
|
||||
|
||||
# Operators
|
||||
|
||||
## Modifiers
|
||||
|
||||
### Addition, concatenation `+`
|
||||
|
||||
If either left or right sides of the `+` operator are a `string`, then this operator will perform string concatenation and return that result. If neither are string, then both must be numeric, and this will return a numeric result.
|
||||
|
||||
Any other case is invalid.
|
||||
|
||||
### Arithmetic `-` `*` `/` `**` `%`
|
||||
|
||||
`**` refers to "take to the power of". For instance, `3 ** 4` == 81.
|
||||
|
||||
* _Left side_: numeric
|
||||
* _Right side_: numeric
|
||||
* _Returns_: numeric
|
||||
|
||||
### Bitwise shifts, masks `>>` `<<` `|` `&` `^`
|
||||
|
||||
All of these operators convert their `float64` left and right sides to `int64`, perform their operation, and then convert back.
|
||||
Given how this library assumes numeric are represented (as `float64`), it is unlikely that this behavior will change, even though it may cause havoc with extremely large or small numbers.
|
||||
|
||||
* _Left side_: numeric
|
||||
* _Right side_: numeric
|
||||
* _Returns_: numeric
|
||||
|
||||
### Negation `-`
|
||||
|
||||
Prefix only. This can never have a left-hand value.
|
||||
|
||||
* _Right side_: numeric
|
||||
* _Returns_: numeric
|
||||
|
||||
### Inversion `!`
|
||||
|
||||
Prefix only. This can never have a left-hand value.
|
||||
|
||||
* _Right side_: bool
|
||||
* _Returns_: bool
|
||||
|
||||
### Bitwise NOT `~`
|
||||
|
||||
Prefix only. This can never have a left-hand value.
|
||||
|
||||
* _Right side_: numeric
|
||||
* _Returns_: numeric
|
||||
|
||||
## Logical Operators
|
||||
|
||||
For all logical operators, this library will short-circuit the operation if the left-hand side is sufficient to determine what to do. For instance, `true || expensiveOperation()` will not actually call `expensiveOperation()`, since it knows the left-hand side is `true`.
|
||||
|
||||
### Logical AND/OR `&&` `||`
|
||||
|
||||
* _Left side_: bool
|
||||
* _Right side_: bool
|
||||
* _Returns_: bool
|
||||
|
||||
### Ternary true `?`
|
||||
|
||||
Checks if the left side is `true`. If so, returns the right side. If the left side is `false`, returns `nil`.
|
||||
In practice, this is commonly used with the other ternary operator.
|
||||
|
||||
* _Left side_: bool
|
||||
* _Right side_: Any type.
|
||||
* _Returns_: Right side or `nil`
|
||||
|
||||
### Ternary false `:`
|
||||
|
||||
Checks if the left side is `nil`. If so, returns the right side. If the left side is non-nil, returns the left side.
|
||||
In practice, this is commonly used with the other ternary operator.
|
||||
|
||||
* _Left side_: Any type.
|
||||
* _Right side_: Any type.
|
||||
* _Returns_: Right side or `nil`
|
||||
|
||||
### Null coalescence `??`
|
||||
|
||||
Similar to the C# operator. If the left value is non-nil, it returns that. If not, then the right-value is returned.
|
||||
|
||||
* _Left side_: Any type.
|
||||
* _Right side_: Any type.
|
||||
* _Returns_: No specific type - whichever is passed to it.
|
||||
|
||||
## Comparators
|
||||
|
||||
### Numeric/lexicographic comparators `>` `<` `>=` `<=`
|
||||
|
||||
If both sides are numeric, this returns the usual greater/lesser behavior that would be expected.
|
||||
If both sides are string, this returns the lexicographic comparison of the strings. This uses Go's standard lexicographic compare.
|
||||
|
||||
* _Accepts_: Left and right side must either be both string, or both numeric.
|
||||
* _Returns_: bool
|
||||
|
||||
### Regex comparators `=~` `!~`
|
||||
|
||||
These use go's standard `regexp` flavor of regex. The left side is expected to be the candidate string, the right side is the pattern. `=~` returns whether or not the candidate string matches the regex pattern given on the right. `!~` is the inverted version of the same logic.
|
||||
|
||||
* _Left side_: string
|
||||
* _Right side_: string
|
||||
* _Returns_: bool
|
||||
|
||||
## Arrays
|
||||
|
||||
### Separator `,`
|
||||
|
||||
The separator, always paired with parenthesis, creates arrays. It must always have both a left and right-hand value, so for instance `(, 0)` and `(0,)` are invalid uses of it.
|
||||
|
||||
Again, this should always be used with parenthesis; like `(1, 2, 3, 4)`.
|
||||
|
||||
### Membership `IN`
|
||||
|
||||
The only operator with a text name, this operator checks the right-hand side array to see if it contains a value that is equal to the left-side value.
|
||||
Equality is determined by the use of the `==` operator, and this library doesn't check types between the values. Any two values, when cast to `interface{}`, and can still be checked for equality with `==` will act as expected.
|
||||
|
||||
Note that you can use a parameter for the array, but it must be an `[]interface{}`.
|
||||
|
||||
* _Left side_: Any type.
|
||||
* _Right side_: array
|
||||
* _Returns_: bool
|
||||
|
||||
# Parameters
|
||||
|
||||
Parameters must be passed in every time the expression is evaluated. Parameters can be of any type, but will not cause errors unless actually used in an erroneous way. There is no difference in behavior for any of the above operators for parameters - they are type checked when used.
|
||||
|
||||
All `int` and `float` values of any width will be converted to `float64` before use.
|
||||
|
||||
At no point is the parameter structure, or any value thereof, modified by this library.
|
||||
|
||||
## Alternates to maps
|
||||
|
||||
The default form of parameters as a map may not serve your use case. You may have parameters in some other structure, you may want to change the no-parameter-found behavior, or maybe even just have some debugging print statements invoked when a parameter is accessed.
|
||||
|
||||
To do this, define a type that implements the `govaluate.Parameters` interface. When you want to evaluate, instead call `EvaluableExpression.Eval` and pass your parameter structure.
|
||||
|
||||
# Functions
|
||||
|
||||
During expression parsing (_not_ evaluation), a map of functions can be given to `govaluate.NewEvaluableExpressionWithFunctions` (the lengthiest and finest of function names). The resultant expression will be able to invoke those functions during evaluation. Once parsed, an expression cannot have functions added or removed - a new expression will need to be created if you want to change the functions, or behavior of said functions.
|
||||
|
||||
Functions always take the form `<name>(<parameters>)`, including parens. Functions can have an empty list of parameters, like `<name>()`, but still must have parens.
|
||||
|
||||
If the expression contains something that looks like it ought to be a function (such as `foo()`), but no such function was given to it, it will error on parsing.
|
||||
|
||||
Functions must be of type `map[string]govaluate.ExpressionFunction`. `ExpressionFunction`, for brevity, has the following signature:
|
||||
|
||||
`func(args ...interface{}) (interface{}, error)`
|
||||
|
||||
Where `args` is whatever is passed to the function when called. If a non-nil error is returned from a function during evaluation, the evaluation stops and ultimately returns that error to the caller of `Evaluate()` or `Eval()`.
|
||||
|
||||
## Built-in functions
|
||||
|
||||
There aren't any builtin functions. The author is opposed to maintaining a standard library of functions to be used.
|
||||
|
||||
Every use case of this library is different, and even in simple use cases (such as parameters, see above) different users need different behavior, naming, or even functionality. The author prefers that users make their own decisions about what functions they need, and how they operate.
|
||||
|
||||
# Equality
|
||||
|
||||
The `==` and `!=` operators involve a moderately complex workflow. They use [`reflect.DeepEqual`](https://golang.org/pkg/reflect/#DeepEqual). This is for complicated reasons, but there are some types in Go that cannot be compared with the native `==` operator. Arrays, in particular, cannot be compared - Go will panic if you try. One might assume this could be handled with the type checking system in `govaluate`, but unfortunately without reflection there is no way to know if a variable is a slice/array. Worse, structs can be incomparable if they _contain incomparable types_.
|
||||
|
||||
It's all very complicated. Fortunately, Go includes the `reflect.DeepEqual` function to handle all the edge cases. Currently, `govaluate` uses that for all equality/inequality.
|
||||
306
vendor/github.com/Knetic/govaluate/OperatorSymbol.go
generated
vendored
306
vendor/github.com/Knetic/govaluate/OperatorSymbol.go
generated
vendored
@@ -1,306 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
/*
|
||||
Represents the valid symbols for operators.
|
||||
|
||||
*/
|
||||
type OperatorSymbol int
|
||||
|
||||
const (
|
||||
VALUE OperatorSymbol = iota
|
||||
LITERAL
|
||||
NOOP
|
||||
EQ
|
||||
NEQ
|
||||
GT
|
||||
LT
|
||||
GTE
|
||||
LTE
|
||||
REQ
|
||||
NREQ
|
||||
IN
|
||||
|
||||
AND
|
||||
OR
|
||||
|
||||
PLUS
|
||||
MINUS
|
||||
BITWISE_AND
|
||||
BITWISE_OR
|
||||
BITWISE_XOR
|
||||
BITWISE_LSHIFT
|
||||
BITWISE_RSHIFT
|
||||
MULTIPLY
|
||||
DIVIDE
|
||||
MODULUS
|
||||
EXPONENT
|
||||
|
||||
NEGATE
|
||||
INVERT
|
||||
BITWISE_NOT
|
||||
|
||||
TERNARY_TRUE
|
||||
TERNARY_FALSE
|
||||
COALESCE
|
||||
|
||||
FUNCTIONAL
|
||||
SEPARATE
|
||||
)
|
||||
|
||||
type operatorPrecedence int
|
||||
|
||||
const (
|
||||
noopPrecedence operatorPrecedence = iota
|
||||
valuePrecedence
|
||||
functionalPrecedence
|
||||
prefixPrecedence
|
||||
exponentialPrecedence
|
||||
additivePrecedence
|
||||
bitwisePrecedence
|
||||
bitwiseShiftPrecedence
|
||||
multiplicativePrecedence
|
||||
comparatorPrecedence
|
||||
ternaryPrecedence
|
||||
logicalAndPrecedence
|
||||
logicalOrPrecedence
|
||||
separatePrecedence
|
||||
)
|
||||
|
||||
func findOperatorPrecedenceForSymbol(symbol OperatorSymbol) operatorPrecedence {
|
||||
|
||||
switch symbol {
|
||||
case NOOP:
|
||||
return noopPrecedence
|
||||
case VALUE:
|
||||
return valuePrecedence
|
||||
case EQ:
|
||||
fallthrough
|
||||
case NEQ:
|
||||
fallthrough
|
||||
case GT:
|
||||
fallthrough
|
||||
case LT:
|
||||
fallthrough
|
||||
case GTE:
|
||||
fallthrough
|
||||
case LTE:
|
||||
fallthrough
|
||||
case REQ:
|
||||
fallthrough
|
||||
case NREQ:
|
||||
fallthrough
|
||||
case IN:
|
||||
return comparatorPrecedence
|
||||
case AND:
|
||||
return logicalAndPrecedence
|
||||
case OR:
|
||||
return logicalOrPrecedence
|
||||
case BITWISE_AND:
|
||||
fallthrough
|
||||
case BITWISE_OR:
|
||||
fallthrough
|
||||
case BITWISE_XOR:
|
||||
return bitwisePrecedence
|
||||
case BITWISE_LSHIFT:
|
||||
fallthrough
|
||||
case BITWISE_RSHIFT:
|
||||
return bitwiseShiftPrecedence
|
||||
case PLUS:
|
||||
fallthrough
|
||||
case MINUS:
|
||||
return additivePrecedence
|
||||
case MULTIPLY:
|
||||
fallthrough
|
||||
case DIVIDE:
|
||||
fallthrough
|
||||
case MODULUS:
|
||||
return multiplicativePrecedence
|
||||
case EXPONENT:
|
||||
return exponentialPrecedence
|
||||
case BITWISE_NOT:
|
||||
fallthrough
|
||||
case NEGATE:
|
||||
fallthrough
|
||||
case INVERT:
|
||||
return prefixPrecedence
|
||||
case COALESCE:
|
||||
fallthrough
|
||||
case TERNARY_TRUE:
|
||||
fallthrough
|
||||
case TERNARY_FALSE:
|
||||
return ternaryPrecedence
|
||||
case FUNCTIONAL:
|
||||
return functionalPrecedence
|
||||
case SEPARATE:
|
||||
return separatePrecedence
|
||||
}
|
||||
|
||||
return valuePrecedence
|
||||
}
|
||||
|
||||
/*
|
||||
Map of all valid comparators, and their string equivalents.
|
||||
Used during parsing of expressions to determine if a symbol is, in fact, a comparator.
|
||||
Also used during evaluation to determine exactly which comparator is being used.
|
||||
*/
|
||||
var comparatorSymbols = map[string]OperatorSymbol{
|
||||
"==": EQ,
|
||||
"!=": NEQ,
|
||||
">": GT,
|
||||
">=": GTE,
|
||||
"<": LT,
|
||||
"<=": LTE,
|
||||
"=~": REQ,
|
||||
"!~": NREQ,
|
||||
"in": IN,
|
||||
}
|
||||
|
||||
var logicalSymbols = map[string]OperatorSymbol{
|
||||
"&&": AND,
|
||||
"||": OR,
|
||||
}
|
||||
|
||||
var bitwiseSymbols = map[string]OperatorSymbol{
|
||||
"^": BITWISE_XOR,
|
||||
"&": BITWISE_AND,
|
||||
"|": BITWISE_OR,
|
||||
}
|
||||
|
||||
var bitwiseShiftSymbols = map[string]OperatorSymbol{
|
||||
">>": BITWISE_RSHIFT,
|
||||
"<<": BITWISE_LSHIFT,
|
||||
}
|
||||
|
||||
var additiveSymbols = map[string]OperatorSymbol{
|
||||
"+": PLUS,
|
||||
"-": MINUS,
|
||||
}
|
||||
|
||||
var multiplicativeSymbols = map[string]OperatorSymbol{
|
||||
"*": MULTIPLY,
|
||||
"/": DIVIDE,
|
||||
"%": MODULUS,
|
||||
}
|
||||
|
||||
var exponentialSymbolsS = map[string]OperatorSymbol{
|
||||
"**": EXPONENT,
|
||||
}
|
||||
|
||||
var prefixSymbols = map[string]OperatorSymbol{
|
||||
"-": NEGATE,
|
||||
"!": INVERT,
|
||||
"~": BITWISE_NOT,
|
||||
}
|
||||
|
||||
var ternarySymbols = map[string]OperatorSymbol{
|
||||
"?": TERNARY_TRUE,
|
||||
":": TERNARY_FALSE,
|
||||
"??": COALESCE,
|
||||
}
|
||||
|
||||
// this is defined separately from additiveSymbols et al because it's needed for parsing, not stage planning.
|
||||
var modifierSymbols = map[string]OperatorSymbol{
|
||||
"+": PLUS,
|
||||
"-": MINUS,
|
||||
"*": MULTIPLY,
|
||||
"/": DIVIDE,
|
||||
"%": MODULUS,
|
||||
"**": EXPONENT,
|
||||
"&": BITWISE_AND,
|
||||
"|": BITWISE_OR,
|
||||
"^": BITWISE_XOR,
|
||||
">>": BITWISE_RSHIFT,
|
||||
"<<": BITWISE_LSHIFT,
|
||||
}
|
||||
|
||||
var separatorSymbols = map[string]OperatorSymbol{
|
||||
",": SEPARATE,
|
||||
}
|
||||
|
||||
/*
|
||||
Returns true if this operator is contained by the given array of candidate symbols.
|
||||
False otherwise.
|
||||
*/
|
||||
func (this OperatorSymbol) IsModifierType(candidate []OperatorSymbol) bool {
|
||||
|
||||
for _, symbolType := range candidate {
|
||||
if this == symbolType {
|
||||
return true
|
||||
}
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
/*
|
||||
Generally used when formatting type check errors.
|
||||
We could store the stringified symbol somewhere else and not require a duplicated codeblock to translate
|
||||
OperatorSymbol to string, but that would require more memory, and another field somewhere.
|
||||
Adding operators is rare enough that we just stringify it here instead.
|
||||
*/
|
||||
func (this OperatorSymbol) String() string {
|
||||
|
||||
switch this {
|
||||
case NOOP:
|
||||
return "NOOP"
|
||||
case VALUE:
|
||||
return "VALUE"
|
||||
case EQ:
|
||||
return "="
|
||||
case NEQ:
|
||||
return "!="
|
||||
case GT:
|
||||
return ">"
|
||||
case LT:
|
||||
return "<"
|
||||
case GTE:
|
||||
return ">="
|
||||
case LTE:
|
||||
return "<="
|
||||
case REQ:
|
||||
return "=~"
|
||||
case NREQ:
|
||||
return "!~"
|
||||
case AND:
|
||||
return "&&"
|
||||
case OR:
|
||||
return "||"
|
||||
case IN:
|
||||
return "in"
|
||||
case BITWISE_AND:
|
||||
return "&"
|
||||
case BITWISE_OR:
|
||||
return "|"
|
||||
case BITWISE_XOR:
|
||||
return "^"
|
||||
case BITWISE_LSHIFT:
|
||||
return "<<"
|
||||
case BITWISE_RSHIFT:
|
||||
return ">>"
|
||||
case PLUS:
|
||||
return "+"
|
||||
case MINUS:
|
||||
return "-"
|
||||
case MULTIPLY:
|
||||
return "*"
|
||||
case DIVIDE:
|
||||
return "/"
|
||||
case MODULUS:
|
||||
return "%"
|
||||
case EXPONENT:
|
||||
return "**"
|
||||
case NEGATE:
|
||||
return "-"
|
||||
case INVERT:
|
||||
return "!"
|
||||
case BITWISE_NOT:
|
||||
return "~"
|
||||
case TERNARY_TRUE:
|
||||
return "?"
|
||||
case TERNARY_FALSE:
|
||||
return ":"
|
||||
case COALESCE:
|
||||
return "??"
|
||||
}
|
||||
return ""
|
||||
}
|
||||
210
vendor/github.com/Knetic/govaluate/README.md
generated
vendored
210
vendor/github.com/Knetic/govaluate/README.md
generated
vendored
@@ -1,210 +0,0 @@
|
||||
govaluate
|
||||
====
|
||||
|
||||
[](https://travis-ci.org/Knetic/govaluate)
|
||||
[](https://godoc.org/github.com/Knetic/govaluate)
|
||||
|
||||
|
||||
Provides support for evaluating arbitrary C-like artithmetic/string expressions.
|
||||
|
||||
Why can't you just write these expressions in code?
|
||||
--
|
||||
|
||||
Sometimes, you can't know ahead-of-time what an expression will look like, or you want those expressions to be configurable.
|
||||
Perhaps you've got a set of data running through your application, and you want to allow your users to specify some validations to run on it before committing it to a database. Or maybe you've written a monitoring framework which is capable of gathering a bunch of metrics, then evaluating a few expressions to see if any metrics should be alerted upon, but the conditions for alerting are different for each monitor.
|
||||
|
||||
A lot of people wind up writing their own half-baked style of evaluation language that fits their needs, but isn't complete. Or they wind up baking the expression into the actual executable, even if they know it's subject to change. These strategies may work, but they take time to implement, time for users to learn, and induce technical debt as requirements change. This library is meant to cover all the normal C-like expressions, so that you don't have to reinvent one of the oldest wheels on a computer.
|
||||
|
||||
How do I use it?
|
||||
--
|
||||
|
||||
You create a new EvaluableExpression, then call "Evaluate" on it.
|
||||
|
||||
```go
|
||||
expression, err := govaluate.NewEvaluableExpression("10 > 0");
|
||||
result, err := expression.Evaluate(nil);
|
||||
// result is now set to "true", the bool value.
|
||||
```
|
||||
|
||||
Cool, but how about with parameters?
|
||||
|
||||
```go
|
||||
expression, err := govaluate.NewEvaluableExpression("foo > 0");
|
||||
|
||||
parameters := make(map[string]interface{}, 8)
|
||||
parameters["foo"] = -1;
|
||||
|
||||
result, err := expression.Evaluate(parameters);
|
||||
// result is now set to "false", the bool value.
|
||||
```
|
||||
|
||||
That's cool, but we can almost certainly have done all that in code. What about a complex use case that involves some math?
|
||||
|
||||
```go
|
||||
expression, err := govaluate.NewEvaluableExpression("(requests_made * requests_succeeded / 100) >= 90");
|
||||
|
||||
parameters := make(map[string]interface{}, 8)
|
||||
parameters["requests_made"] = 100;
|
||||
parameters["requests_succeeded"] = 80;
|
||||
|
||||
result, err := expression.Evaluate(parameters);
|
||||
// result is now set to "false", the bool value.
|
||||
```
|
||||
|
||||
Or maybe you want to check the status of an alive check ("smoketest") page, which will be a string?
|
||||
|
||||
```go
|
||||
expression, err := govaluate.NewEvaluableExpression("http_response_body == 'service is ok'");
|
||||
|
||||
parameters := make(map[string]interface{}, 8)
|
||||
parameters["http_response_body"] = "service is ok";
|
||||
|
||||
result, err := expression.Evaluate(parameters);
|
||||
// result is now set to "true", the bool value.
|
||||
```
|
||||
|
||||
These examples have all returned boolean values, but it's equally possible to return numeric ones.
|
||||
|
||||
```go
|
||||
expression, err := govaluate.NewEvaluableExpression("(mem_used / total_mem) * 100");
|
||||
|
||||
parameters := make(map[string]interface{}, 8)
|
||||
parameters["total_mem"] = 1024;
|
||||
parameters["mem_used"] = 512;
|
||||
|
||||
result, err := expression.Evaluate(parameters);
|
||||
// result is now set to "50.0", the float64 value.
|
||||
```
|
||||
|
||||
You can also do date parsing, though the formats are somewhat limited. Stick to RF3339, ISO8061, unix date, or ruby date formats. If you're having trouble getting a date string to parse, check the list of formats actually used: [parsing.go:248](https://github.com/Knetic/govaluate/blob/0580e9b47a69125afa0e4ebd1cf93c49eb5a43ec/parsing.go#L258).
|
||||
|
||||
```go
|
||||
expression, err := govaluate.NewEvaluableExpression("'2014-01-02' > '2014-01-01 23:59:59'");
|
||||
result, err := expression.Evaluate(nil);
|
||||
|
||||
// result is now set to true
|
||||
```
|
||||
|
||||
Expressions are parsed once, and can be re-used multiple times. Parsing is the compute-intensive phase of the process, so if you intend to use the same expression with different parameters, just parse it once. Like so;
|
||||
|
||||
```go
|
||||
expression, err := govaluate.NewEvaluableExpression("response_time <= 100");
|
||||
parameters := make(map[string]interface{}, 8)
|
||||
|
||||
for {
|
||||
parameters["response_time"] = pingSomething();
|
||||
result, err := expression.Evaluate(parameters)
|
||||
}
|
||||
```
|
||||
|
||||
The normal C-standard order of operators is respected. When writing an expression, be sure that you either order the operators correctly, or use parenthesis to clarify which portions of an expression should be run first.
|
||||
|
||||
Escaping characters
|
||||
--
|
||||
|
||||
Sometimes you'll have parameters that have spaces, slashes, pluses, ampersands or some other character
|
||||
that this library interprets as something special. For example, the following expression will not
|
||||
act as one might expect:
|
||||
|
||||
"response-time < 100"
|
||||
|
||||
As written, the library will parse it as "[response] minus [time] is less than 100". In reality,
|
||||
"response-time" is meant to be one variable that just happens to have a dash in it.
|
||||
|
||||
There are two ways to work around this. First, you can escape the entire parameter name:
|
||||
|
||||
"[response-time] < 100"
|
||||
|
||||
Or you can use backslashes to escape only the minus sign.
|
||||
|
||||
"response\\-time < 100"
|
||||
|
||||
Backslashes can be used anywhere in an expression to escape the very next character. Square bracketed parameter names can be used instead of plain parameter names at any time.
|
||||
|
||||
Functions
|
||||
--
|
||||
|
||||
You may have cases where you want to call a function on a parameter during execution of the expression. Perhaps you want to aggregate some set of data, but don't know the exact aggregation you want to use until you're writing the expression itself. Or maybe you have a mathematical operation you want to perform, for which there is no operator; like `log` or `tan` or `sqrt`. For cases like this, you can provide a map of functions to `NewEvaluableExpressionWithFunctions`, which will then be able to use them during execution. For instance;
|
||||
|
||||
```go
|
||||
functions := map[string]govaluate.ExpressionFunction {
|
||||
"strlen": func(args ...interface{}) (interface{}, error) {
|
||||
length := len(args[0].(string))
|
||||
return (float64)(length), nil
|
||||
},
|
||||
}
|
||||
|
||||
expString := "strlen('someReallyLongInputString') <= 16"
|
||||
expression, _ := govaluate.NewEvaluableExpressionWithFunctions(expString, functions)
|
||||
|
||||
result, _ := expression.Evaluate(nil)
|
||||
// result is now "false", the boolean value
|
||||
```
|
||||
|
||||
Functions can accept any number of arguments, correctly handles nested functions, and arguments can be of any type (even if none of this library's operators support evaluation of that type). For instance, each of these usages of functions in an expression are valid (assuming that the appropriate functions and parameters are given):
|
||||
|
||||
```go
|
||||
"sqrt(x1 ** y1, x2 ** y2)"
|
||||
"max(someValue, abs(anotherValue), 10 * lastValue)"
|
||||
```
|
||||
|
||||
Functions cannot be passed as parameters, they must be known at the time when the expression is parsed, and are unchangeable after parsing.
|
||||
|
||||
What operators and types does this support?
|
||||
--
|
||||
|
||||
* Modifiers: `+` `-` `/` `*` `&` `|` `^` `**` `%` `>>` `<<`
|
||||
* Comparators: `>` `>=` `<` `<=` `==` `!=` `=~` `!~`
|
||||
* Logical ops: `||` `&&`
|
||||
* Numeric constants, as 64-bit floating point (`12345.678`)
|
||||
* String constants (single quotes: `'foobar'`)
|
||||
* Date constants (single quotes, using any permutation of RFC3339, ISO8601, ruby date, or unix date; date parsing is automatically tried with any string constant)
|
||||
* Boolean constants: `true` `false`
|
||||
* Parenthesis to control order of evaluation `(` `)`
|
||||
* Arrays (anything separated by `,` within parenthesis: `(1, 2, 'foo')`)
|
||||
* Prefixes: `!` `-` `~`
|
||||
* Ternary conditional: `?` `:`
|
||||
* Null coalescence: `??`
|
||||
|
||||
See [MANUAL.md](https://github.com/Knetic/govaluate/blob/master/MANUAL.md) for exacting details on what types each operator supports.
|
||||
|
||||
Types
|
||||
--
|
||||
|
||||
Some operators don't make sense when used with some types. For instance, what does it mean to get the modulo of a string? What happens if you check to see if two numbers are logically AND'ed together?
|
||||
|
||||
Everyone has a different intuition about the answers to these questions. To prevent confusion, this library will _refuse to operate_ upon types for which there is not an unambiguous meaning for the operation. See [MANUAL.md](https://github.com/Knetic/govaluate/blob/master/MANUAL.md) for details about what operators are valid for which types.
|
||||
|
||||
Benchmarks
|
||||
--
|
||||
|
||||
If you're concerned about the overhead of this library, a good range of benchmarks are built into this repo. You can run them with `go test -bench=.`. The library is built with an eye towards being quick, but has not been aggressively profiled and optimized. For most applications, though, it is completely fine.
|
||||
|
||||
For a very rough idea of performance, here are the results output from a benchmark run on a 3rd-gen Macbook Pro (Linux Mint 17.1).
|
||||
|
||||
```
|
||||
BenchmarkSingleParse-12 1000000 1382 ns/op
|
||||
BenchmarkSimpleParse-12 200000 10771 ns/op
|
||||
BenchmarkFullParse-12 30000 49383 ns/op
|
||||
BenchmarkEvaluationSingle-12 50000000 30.1 ns/op
|
||||
BenchmarkEvaluationNumericLiteral-12 10000000 119 ns/op
|
||||
BenchmarkEvaluationLiteralModifiers-12 10000000 236 ns/op
|
||||
BenchmarkEvaluationParameters-12 5000000 260 ns/op
|
||||
BenchmarkEvaluationParametersModifiers-12 3000000 547 ns/op
|
||||
BenchmarkComplexExpression-12 2000000 963 ns/op
|
||||
BenchmarkRegexExpression-12 100000 20357 ns/op
|
||||
BenchmarkConstantRegexExpression-12 1000000 1392 ns/op
|
||||
ok
|
||||
```
|
||||
|
||||
API Breaks
|
||||
--
|
||||
|
||||
While this library has very few cases which will ever result in an API break, it can (and [has](https://github.com/Knetic/govaluate/releases/tag/2.0.0)) happened. If you are using this in production, vendor the commit you've tested against, or use gopkg.in to redirect your import (e.g., `import "gopkg.in/Knetic/govaluate.v2"`). Master branch (while infrequent) _may_ at some point contain API breaking changes, and the author will have no way to communicate these to downstreams, other than creating a new major release.
|
||||
|
||||
Releases will explicitly state when an API break happens, and if they do not specify an API break it should be safe to upgrade.
|
||||
|
||||
License
|
||||
--
|
||||
|
||||
This project is licensed under the MIT general use license. You're free to integrate, fork, and play with this code as you feel fit without consulting the author, as long as you provide proper credit to the author in your works.
|
||||
72
vendor/github.com/Knetic/govaluate/TokenKind.go
generated
vendored
72
vendor/github.com/Knetic/govaluate/TokenKind.go
generated
vendored
@@ -1,72 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
/*
|
||||
Represents all valid types of tokens that a token can be.
|
||||
*/
|
||||
type TokenKind int
|
||||
|
||||
const (
|
||||
UNKNOWN TokenKind = iota
|
||||
|
||||
PREFIX
|
||||
NUMERIC
|
||||
BOOLEAN
|
||||
STRING
|
||||
PATTERN
|
||||
TIME
|
||||
VARIABLE
|
||||
FUNCTION
|
||||
SEPARATOR
|
||||
|
||||
COMPARATOR
|
||||
LOGICALOP
|
||||
MODIFIER
|
||||
|
||||
CLAUSE
|
||||
CLAUSE_CLOSE
|
||||
|
||||
TERNARY
|
||||
)
|
||||
|
||||
/*
|
||||
GetTokenKindString returns a string that describes the given TokenKind.
|
||||
e.g., when passed the NUMERIC TokenKind, this returns the string "NUMERIC".
|
||||
*/
|
||||
func (kind TokenKind) String() string {
|
||||
|
||||
switch kind {
|
||||
|
||||
case PREFIX:
|
||||
return "PREFIX"
|
||||
case NUMERIC:
|
||||
return "NUMERIC"
|
||||
case BOOLEAN:
|
||||
return "BOOLEAN"
|
||||
case STRING:
|
||||
return "STRING"
|
||||
case PATTERN:
|
||||
return "PATTERN"
|
||||
case TIME:
|
||||
return "TIME"
|
||||
case VARIABLE:
|
||||
return "VARIABLE"
|
||||
case FUNCTION:
|
||||
return "FUNCTION"
|
||||
case SEPARATOR:
|
||||
return "SEPARATOR"
|
||||
case COMPARATOR:
|
||||
return "COMPARATOR"
|
||||
case LOGICALOP:
|
||||
return "LOGICALOP"
|
||||
case MODIFIER:
|
||||
return "MODIFIER"
|
||||
case CLAUSE:
|
||||
return "CLAUSE"
|
||||
case CLAUSE_CLOSE:
|
||||
return "CLAUSE_CLOSE"
|
||||
case TERNARY:
|
||||
return "TERNARY"
|
||||
}
|
||||
|
||||
return "UNKNOWN"
|
||||
}
|
||||
359
vendor/github.com/Knetic/govaluate/evaluationStage.go
generated
vendored
359
vendor/github.com/Knetic/govaluate/evaluationStage.go
generated
vendored
@@ -1,359 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"math"
|
||||
"regexp"
|
||||
"reflect"
|
||||
)
|
||||
|
||||
const (
|
||||
logicalErrorFormat string = "Value '%v' cannot be used with the logical operator '%v', it is not a bool"
|
||||
modifierErrorFormat string = "Value '%v' cannot be used with the modifier '%v', it is not a number"
|
||||
comparatorErrorFormat string = "Value '%v' cannot be used with the comparator '%v', it is not a number"
|
||||
ternaryErrorFormat string = "Value '%v' cannot be used with the ternary operator '%v', it is not a bool"
|
||||
prefixErrorFormat string = "Value '%v' cannot be used with the prefix '%v'"
|
||||
)
|
||||
|
||||
type evaluationOperator func(left interface{}, right interface{}, parameters Parameters) (interface{}, error)
|
||||
type stageTypeCheck func(value interface{}) bool
|
||||
type stageCombinedTypeCheck func(left interface{}, right interface{}) bool
|
||||
|
||||
type evaluationStage struct {
|
||||
symbol OperatorSymbol
|
||||
|
||||
leftStage, rightStage *evaluationStage
|
||||
|
||||
// the operation that will be used to evaluate this stage (such as adding [left] to [right] and return the result)
|
||||
operator evaluationOperator
|
||||
|
||||
// ensures that both left and right values are appropriate for this stage. Returns an error if they aren't operable.
|
||||
leftTypeCheck stageTypeCheck
|
||||
rightTypeCheck stageTypeCheck
|
||||
|
||||
// if specified, will override whatever is used in "leftTypeCheck" and "rightTypeCheck".
|
||||
// primarily used for specific operators that don't care which side a given type is on, but still requires one side to be of a given type
|
||||
// (like string concat)
|
||||
typeCheck stageCombinedTypeCheck
|
||||
|
||||
// regardless of which type check is used, this string format will be used as the error message for type errors
|
||||
typeErrorFormat string
|
||||
}
|
||||
|
||||
var (
|
||||
_true = interface{}(true)
|
||||
_false = interface{}(false)
|
||||
)
|
||||
|
||||
func (this *evaluationStage) swapWith(other *evaluationStage) {
|
||||
|
||||
temp := *other
|
||||
other.setToNonStage(*this)
|
||||
this.setToNonStage(temp)
|
||||
}
|
||||
|
||||
func (this *evaluationStage) setToNonStage(other evaluationStage) {
|
||||
|
||||
this.symbol = other.symbol
|
||||
this.operator = other.operator
|
||||
this.leftTypeCheck = other.leftTypeCheck
|
||||
this.rightTypeCheck = other.rightTypeCheck
|
||||
this.typeCheck = other.typeCheck
|
||||
this.typeErrorFormat = other.typeErrorFormat
|
||||
}
|
||||
|
||||
func (this *evaluationStage) isShortCircuitable() bool {
|
||||
|
||||
switch this.symbol {
|
||||
case AND:
|
||||
fallthrough
|
||||
case OR:
|
||||
fallthrough
|
||||
case TERNARY_TRUE:
|
||||
fallthrough
|
||||
case TERNARY_FALSE:
|
||||
fallthrough
|
||||
case COALESCE:
|
||||
return true
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
func noopStageRight(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return right, nil
|
||||
}
|
||||
|
||||
func addStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
|
||||
// string concat if either are strings
|
||||
if isString(left) || isString(right) {
|
||||
return fmt.Sprintf("%v%v", left, right), nil
|
||||
}
|
||||
|
||||
return left.(float64) + right.(float64), nil
|
||||
}
|
||||
func subtractStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return left.(float64) - right.(float64), nil
|
||||
}
|
||||
func multiplyStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return left.(float64) * right.(float64), nil
|
||||
}
|
||||
func divideStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return left.(float64) / right.(float64), nil
|
||||
}
|
||||
func exponentStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return math.Pow(left.(float64), right.(float64)), nil
|
||||
}
|
||||
func modulusStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return math.Mod(left.(float64), right.(float64)), nil
|
||||
}
|
||||
func gteStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
if isString(left) && isString(right) {
|
||||
return boolIface(left.(string) >= right.(string)), nil
|
||||
}
|
||||
return boolIface(left.(float64) >= right.(float64)), nil
|
||||
}
|
||||
func gtStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
if isString(left) && isString(right) {
|
||||
return boolIface(left.(string) > right.(string)), nil
|
||||
}
|
||||
return boolIface(left.(float64) > right.(float64)), nil
|
||||
}
|
||||
func lteStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
if isString(left) && isString(right) {
|
||||
return boolIface(left.(string) <= right.(string)), nil
|
||||
}
|
||||
return boolIface(left.(float64) <= right.(float64)), nil
|
||||
}
|
||||
func ltStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
if isString(left) && isString(right) {
|
||||
return boolIface(left.(string) < right.(string)), nil
|
||||
}
|
||||
return boolIface(left.(float64) < right.(float64)), nil
|
||||
}
|
||||
func equalStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return boolIface(reflect.DeepEqual(left, right)), nil
|
||||
}
|
||||
func notEqualStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return boolIface(!reflect.DeepEqual(left, right)), nil
|
||||
}
|
||||
func andStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return boolIface(left.(bool) && right.(bool)), nil
|
||||
}
|
||||
func orStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return boolIface(left.(bool) || right.(bool)), nil
|
||||
}
|
||||
func negateStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return -right.(float64), nil
|
||||
}
|
||||
func invertStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return boolIface(!right.(bool)), nil
|
||||
}
|
||||
func bitwiseNotStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return float64(^int64(right.(float64))), nil
|
||||
}
|
||||
func ternaryIfStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
if left.(bool) {
|
||||
return right, nil
|
||||
}
|
||||
return nil, nil
|
||||
}
|
||||
func ternaryElseStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
if left != nil {
|
||||
return left, nil
|
||||
}
|
||||
return right, nil
|
||||
}
|
||||
|
||||
func regexStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
|
||||
var pattern *regexp.Regexp
|
||||
var err error
|
||||
|
||||
switch right.(type) {
|
||||
case string:
|
||||
pattern, err = regexp.Compile(right.(string))
|
||||
if err != nil {
|
||||
return nil, errors.New(fmt.Sprintf("Unable to compile regexp pattern '%v': %v", right, err))
|
||||
}
|
||||
case *regexp.Regexp:
|
||||
pattern = right.(*regexp.Regexp)
|
||||
}
|
||||
|
||||
return pattern.Match([]byte(left.(string))), nil
|
||||
}
|
||||
|
||||
func notRegexStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
|
||||
ret, err := regexStage(left, right, parameters)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return !(ret.(bool)), nil
|
||||
}
|
||||
|
||||
func bitwiseOrStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return float64(int64(left.(float64)) | int64(right.(float64))), nil
|
||||
}
|
||||
func bitwiseAndStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return float64(int64(left.(float64)) & int64(right.(float64))), nil
|
||||
}
|
||||
func bitwiseXORStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return float64(int64(left.(float64)) ^ int64(right.(float64))), nil
|
||||
}
|
||||
func leftShiftStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return float64(uint64(left.(float64)) << uint64(right.(float64))), nil
|
||||
}
|
||||
func rightShiftStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return float64(uint64(left.(float64)) >> uint64(right.(float64))), nil
|
||||
}
|
||||
|
||||
func makeParameterStage(parameterName string) evaluationOperator {
|
||||
|
||||
return func(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
value, err := parameters.Get(parameterName)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return value, nil
|
||||
}
|
||||
}
|
||||
|
||||
func makeLiteralStage(literal interface{}) evaluationOperator {
|
||||
return func(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
return literal, nil
|
||||
}
|
||||
}
|
||||
|
||||
func makeFunctionStage(function ExpressionFunction) evaluationOperator {
|
||||
|
||||
return func(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
|
||||
if right == nil {
|
||||
return function()
|
||||
}
|
||||
|
||||
switch right.(type) {
|
||||
case []interface{}:
|
||||
return function(right.([]interface{})...)
|
||||
default:
|
||||
return function(right)
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
func separatorStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
|
||||
var ret []interface{}
|
||||
|
||||
switch left.(type) {
|
||||
case []interface{}:
|
||||
ret = append(left.([]interface{}), right)
|
||||
default:
|
||||
ret = []interface{}{left, right}
|
||||
}
|
||||
|
||||
return ret, nil
|
||||
}
|
||||
|
||||
func inStage(left interface{}, right interface{}, parameters Parameters) (interface{}, error) {
|
||||
|
||||
for _, value := range right.([]interface{}) {
|
||||
if left == value {
|
||||
return true, nil
|
||||
}
|
||||
}
|
||||
return false, nil
|
||||
}
|
||||
|
||||
//
|
||||
|
||||
func isString(value interface{}) bool {
|
||||
|
||||
switch value.(type) {
|
||||
case string:
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func isRegexOrString(value interface{}) bool {
|
||||
|
||||
switch value.(type) {
|
||||
case string:
|
||||
return true
|
||||
case *regexp.Regexp:
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func isBool(value interface{}) bool {
|
||||
switch value.(type) {
|
||||
case bool:
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func isFloat64(value interface{}) bool {
|
||||
switch value.(type) {
|
||||
case float64:
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
/*
|
||||
Addition usually means between numbers, but can also mean string concat.
|
||||
String concat needs one (or both) of the sides to be a string.
|
||||
*/
|
||||
func additionTypeCheck(left interface{}, right interface{}) bool {
|
||||
|
||||
if isFloat64(left) && isFloat64(right) {
|
||||
return true
|
||||
}
|
||||
if !isString(left) && !isString(right) {
|
||||
return false
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
/*
|
||||
Comparison can either be between numbers, or lexicographic between two strings,
|
||||
but never between the two.
|
||||
*/
|
||||
func comparatorTypeCheck(left interface{}, right interface{}) bool {
|
||||
|
||||
if isFloat64(left) && isFloat64(right) {
|
||||
return true
|
||||
}
|
||||
if isString(left) && isString(right) {
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func isArray(value interface{}) bool {
|
||||
switch value.(type) {
|
||||
case []interface{}:
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
/*
|
||||
Converting a boolean to an interface{} requires an allocation.
|
||||
We can use interned bools to avoid this cost.
|
||||
*/
|
||||
func boolIface(b bool) interface{} {
|
||||
if b {
|
||||
return _true
|
||||
}
|
||||
return _false
|
||||
}
|
||||
8
vendor/github.com/Knetic/govaluate/expressionFunctions.go
generated
vendored
8
vendor/github.com/Knetic/govaluate/expressionFunctions.go
generated
vendored
@@ -1,8 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
/*
|
||||
Represents a function that can be called from within an expression.
|
||||
This method must return an error if, for any reason, it is unable to produce exactly one unambiguous result.
|
||||
An error returned will halt execution of the expression.
|
||||
*/
|
||||
type ExpressionFunction func(arguments ...interface{}) (interface{}, error)
|
||||
46
vendor/github.com/Knetic/govaluate/expressionOutputStream.go
generated
vendored
46
vendor/github.com/Knetic/govaluate/expressionOutputStream.go
generated
vendored
@@ -1,46 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
)
|
||||
|
||||
/*
|
||||
Holds a series of "transactions" which represent each token as it is output by an outputter (such as ToSQLQuery()).
|
||||
Some outputs (such as SQL) require a function call or non-c-like syntax to represent an expression.
|
||||
To accomplish this, this struct keeps track of each translated token as it is output, and can return and rollback those transactions.
|
||||
*/
|
||||
type expressionOutputStream struct {
|
||||
transactions []string
|
||||
}
|
||||
|
||||
func (this *expressionOutputStream) add(transaction string) {
|
||||
this.transactions = append(this.transactions, transaction)
|
||||
}
|
||||
|
||||
func (this *expressionOutputStream) rollback() string {
|
||||
|
||||
index := len(this.transactions) - 1
|
||||
ret := this.transactions[index]
|
||||
|
||||
this.transactions = this.transactions[:index]
|
||||
return ret
|
||||
}
|
||||
|
||||
func (this *expressionOutputStream) createString(delimiter string) string {
|
||||
|
||||
var retBuffer bytes.Buffer
|
||||
var transaction string
|
||||
|
||||
penultimate := len(this.transactions) - 1
|
||||
|
||||
for i := 0; i < penultimate; i++ {
|
||||
|
||||
transaction = this.transactions[i]
|
||||
|
||||
retBuffer.WriteString(transaction)
|
||||
retBuffer.WriteString(delimiter)
|
||||
}
|
||||
retBuffer.WriteString(this.transactions[penultimate])
|
||||
|
||||
return retBuffer.String()
|
||||
}
|
||||
350
vendor/github.com/Knetic/govaluate/lexerState.go
generated
vendored
350
vendor/github.com/Knetic/govaluate/lexerState.go
generated
vendored
@@ -1,350 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
)
|
||||
|
||||
type lexerState struct {
|
||||
isEOF bool
|
||||
isNullable bool
|
||||
kind TokenKind
|
||||
validNextKinds []TokenKind
|
||||
}
|
||||
|
||||
// lexer states.
|
||||
// Constant for all purposes except compiler.
|
||||
var validLexerStates = []lexerState{
|
||||
|
||||
lexerState{
|
||||
kind: UNKNOWN,
|
||||
isEOF: false,
|
||||
isNullable: true,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
PREFIX,
|
||||
NUMERIC,
|
||||
BOOLEAN,
|
||||
VARIABLE,
|
||||
PATTERN,
|
||||
FUNCTION,
|
||||
STRING,
|
||||
TIME,
|
||||
CLAUSE,
|
||||
},
|
||||
},
|
||||
|
||||
lexerState{
|
||||
|
||||
kind: CLAUSE,
|
||||
isEOF: false,
|
||||
isNullable: true,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
PREFIX,
|
||||
NUMERIC,
|
||||
BOOLEAN,
|
||||
VARIABLE,
|
||||
PATTERN,
|
||||
FUNCTION,
|
||||
STRING,
|
||||
TIME,
|
||||
CLAUSE,
|
||||
CLAUSE_CLOSE,
|
||||
},
|
||||
},
|
||||
|
||||
lexerState{
|
||||
|
||||
kind: CLAUSE_CLOSE,
|
||||
isEOF: true,
|
||||
isNullable: true,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
COMPARATOR,
|
||||
MODIFIER,
|
||||
NUMERIC,
|
||||
BOOLEAN,
|
||||
VARIABLE,
|
||||
STRING,
|
||||
PATTERN,
|
||||
TIME,
|
||||
CLAUSE,
|
||||
CLAUSE_CLOSE,
|
||||
LOGICALOP,
|
||||
TERNARY,
|
||||
SEPARATOR,
|
||||
},
|
||||
},
|
||||
|
||||
lexerState{
|
||||
|
||||
kind: NUMERIC,
|
||||
isEOF: true,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
MODIFIER,
|
||||
COMPARATOR,
|
||||
LOGICALOP,
|
||||
CLAUSE_CLOSE,
|
||||
TERNARY,
|
||||
SEPARATOR,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: BOOLEAN,
|
||||
isEOF: true,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
MODIFIER,
|
||||
COMPARATOR,
|
||||
LOGICALOP,
|
||||
CLAUSE_CLOSE,
|
||||
TERNARY,
|
||||
SEPARATOR,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: STRING,
|
||||
isEOF: true,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
MODIFIER,
|
||||
COMPARATOR,
|
||||
LOGICALOP,
|
||||
CLAUSE_CLOSE,
|
||||
TERNARY,
|
||||
SEPARATOR,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: TIME,
|
||||
isEOF: true,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
MODIFIER,
|
||||
COMPARATOR,
|
||||
LOGICALOP,
|
||||
CLAUSE_CLOSE,
|
||||
SEPARATOR,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: PATTERN,
|
||||
isEOF: true,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
MODIFIER,
|
||||
COMPARATOR,
|
||||
LOGICALOP,
|
||||
CLAUSE_CLOSE,
|
||||
SEPARATOR,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: VARIABLE,
|
||||
isEOF: true,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
MODIFIER,
|
||||
COMPARATOR,
|
||||
LOGICALOP,
|
||||
CLAUSE_CLOSE,
|
||||
TERNARY,
|
||||
SEPARATOR,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: MODIFIER,
|
||||
isEOF: false,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
PREFIX,
|
||||
NUMERIC,
|
||||
VARIABLE,
|
||||
FUNCTION,
|
||||
STRING,
|
||||
BOOLEAN,
|
||||
CLAUSE,
|
||||
CLAUSE_CLOSE,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: COMPARATOR,
|
||||
isEOF: false,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
PREFIX,
|
||||
NUMERIC,
|
||||
BOOLEAN,
|
||||
VARIABLE,
|
||||
FUNCTION,
|
||||
STRING,
|
||||
TIME,
|
||||
CLAUSE,
|
||||
CLAUSE_CLOSE,
|
||||
PATTERN,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: LOGICALOP,
|
||||
isEOF: false,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
PREFIX,
|
||||
NUMERIC,
|
||||
BOOLEAN,
|
||||
VARIABLE,
|
||||
FUNCTION,
|
||||
STRING,
|
||||
TIME,
|
||||
CLAUSE,
|
||||
CLAUSE_CLOSE,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: PREFIX,
|
||||
isEOF: false,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
NUMERIC,
|
||||
BOOLEAN,
|
||||
VARIABLE,
|
||||
FUNCTION,
|
||||
CLAUSE,
|
||||
CLAUSE_CLOSE,
|
||||
},
|
||||
},
|
||||
|
||||
lexerState{
|
||||
|
||||
kind: TERNARY,
|
||||
isEOF: false,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
PREFIX,
|
||||
NUMERIC,
|
||||
BOOLEAN,
|
||||
STRING,
|
||||
TIME,
|
||||
VARIABLE,
|
||||
FUNCTION,
|
||||
CLAUSE,
|
||||
SEPARATOR,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: FUNCTION,
|
||||
isEOF: false,
|
||||
isNullable: false,
|
||||
validNextKinds: []TokenKind{
|
||||
CLAUSE,
|
||||
},
|
||||
},
|
||||
lexerState{
|
||||
|
||||
kind: SEPARATOR,
|
||||
isEOF: false,
|
||||
isNullable: true,
|
||||
validNextKinds: []TokenKind{
|
||||
|
||||
PREFIX,
|
||||
NUMERIC,
|
||||
BOOLEAN,
|
||||
STRING,
|
||||
TIME,
|
||||
VARIABLE,
|
||||
FUNCTION,
|
||||
CLAUSE,
|
||||
},
|
||||
},
|
||||
}
|
||||
|
||||
func (this lexerState) canTransitionTo(kind TokenKind) bool {
|
||||
|
||||
for _, validKind := range this.validNextKinds {
|
||||
|
||||
if validKind == kind {
|
||||
return true
|
||||
}
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
func checkExpressionSyntax(tokens []ExpressionToken) error {
|
||||
|
||||
var state lexerState
|
||||
var lastToken ExpressionToken
|
||||
var err error
|
||||
|
||||
state = validLexerStates[0]
|
||||
|
||||
for _, token := range tokens {
|
||||
|
||||
if !state.canTransitionTo(token.Kind) {
|
||||
|
||||
// call out a specific error for tokens looking like they want to be functions.
|
||||
if lastToken.Kind == VARIABLE && token.Kind == CLAUSE {
|
||||
return errors.New("Undefined function " + lastToken.Value.(string))
|
||||
}
|
||||
|
||||
firstStateName := fmt.Sprintf("%s [%v]", state.kind.String(), lastToken.Value)
|
||||
nextStateName := fmt.Sprintf("%s [%v]", token.Kind.String(), token.Value)
|
||||
|
||||
return errors.New("Cannot transition token types from " + firstStateName + " to " + nextStateName)
|
||||
}
|
||||
|
||||
state, err = getLexerStateForToken(token.Kind)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
if !state.isNullable && token.Value == nil {
|
||||
|
||||
errorMsg := fmt.Sprintf("Token kind '%v' cannot have a nil value", token.Kind.String())
|
||||
return errors.New(errorMsg)
|
||||
}
|
||||
|
||||
lastToken = token
|
||||
}
|
||||
|
||||
if !state.isEOF {
|
||||
return errors.New("Unexpected end of expression")
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func getLexerStateForToken(kind TokenKind) (lexerState, error) {
|
||||
|
||||
for _, possibleState := range validLexerStates {
|
||||
|
||||
if possibleState.kind == kind {
|
||||
return possibleState, nil
|
||||
}
|
||||
}
|
||||
|
||||
errorMsg := fmt.Sprintf("No lexer state found for token kind '%v'\n", kind.String())
|
||||
return validLexerStates[0], errors.New(errorMsg)
|
||||
}
|
||||
39
vendor/github.com/Knetic/govaluate/lexerStream.go
generated
vendored
39
vendor/github.com/Knetic/govaluate/lexerStream.go
generated
vendored
@@ -1,39 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
type lexerStream struct {
|
||||
source []rune
|
||||
position int
|
||||
length int
|
||||
}
|
||||
|
||||
func newLexerStream(source string) *lexerStream {
|
||||
|
||||
var ret *lexerStream
|
||||
var runes []rune
|
||||
|
||||
for _, character := range source {
|
||||
runes = append(runes, character)
|
||||
}
|
||||
|
||||
ret = new(lexerStream)
|
||||
ret.source = runes
|
||||
ret.length = len(runes)
|
||||
return ret
|
||||
}
|
||||
|
||||
func (this *lexerStream) readCharacter() rune {
|
||||
|
||||
var character rune
|
||||
|
||||
character = this.source[this.position]
|
||||
this.position += 1
|
||||
return character
|
||||
}
|
||||
|
||||
func (this *lexerStream) rewind(amount int) {
|
||||
this.position -= amount
|
||||
}
|
||||
|
||||
func (this lexerStream) canRead() bool {
|
||||
return this.position < this.length
|
||||
}
|
||||
32
vendor/github.com/Knetic/govaluate/parameters.go
generated
vendored
32
vendor/github.com/Knetic/govaluate/parameters.go
generated
vendored
@@ -1,32 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
import (
|
||||
"errors"
|
||||
)
|
||||
|
||||
/*
|
||||
Parameters is a collection of named parameters that can be used by an EvaluableExpression to retrieve parameters
|
||||
when an expression tries to use them.
|
||||
*/
|
||||
type Parameters interface {
|
||||
|
||||
/*
|
||||
Get gets the parameter of the given name, or an error if the parameter is unavailable.
|
||||
Failure to find the given parameter should be indicated by returning an error.
|
||||
*/
|
||||
Get(name string) (interface{}, error)
|
||||
}
|
||||
|
||||
type MapParameters map[string]interface{}
|
||||
|
||||
func (p MapParameters) Get(name string) (interface{}, error) {
|
||||
|
||||
value, found := p[name]
|
||||
|
||||
if !found {
|
||||
errorMessage := "No parameter '" + name + "' found."
|
||||
return nil, errors.New(errorMessage)
|
||||
}
|
||||
|
||||
return value, nil
|
||||
}
|
||||
450
vendor/github.com/Knetic/govaluate/parsing.go
generated
vendored
450
vendor/github.com/Knetic/govaluate/parsing.go
generated
vendored
@@ -1,450 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"errors"
|
||||
"fmt"
|
||||
"regexp"
|
||||
"strconv"
|
||||
"time"
|
||||
"unicode"
|
||||
)
|
||||
|
||||
func parseTokens(expression string, functions map[string]ExpressionFunction) ([]ExpressionToken, error) {
|
||||
|
||||
var ret []ExpressionToken
|
||||
var token ExpressionToken
|
||||
var stream *lexerStream
|
||||
var state lexerState
|
||||
var err error
|
||||
var found bool
|
||||
|
||||
stream = newLexerStream(expression)
|
||||
state = validLexerStates[0]
|
||||
|
||||
for stream.canRead() {
|
||||
|
||||
token, err, found = readToken(stream, state, functions)
|
||||
|
||||
if err != nil {
|
||||
return ret, err
|
||||
}
|
||||
|
||||
if !found {
|
||||
break
|
||||
}
|
||||
|
||||
state, err = getLexerStateForToken(token.Kind)
|
||||
if err != nil {
|
||||
return ret, err
|
||||
}
|
||||
|
||||
// append this valid token
|
||||
ret = append(ret, token)
|
||||
}
|
||||
|
||||
err = checkBalance(ret)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return ret, nil
|
||||
}
|
||||
|
||||
func readToken(stream *lexerStream, state lexerState, functions map[string]ExpressionFunction) (ExpressionToken, error, bool) {
|
||||
|
||||
var function ExpressionFunction
|
||||
var ret ExpressionToken
|
||||
var tokenValue interface{}
|
||||
var tokenTime time.Time
|
||||
var tokenString string
|
||||
var kind TokenKind
|
||||
var character rune
|
||||
var found bool
|
||||
var completed bool
|
||||
var err error
|
||||
|
||||
// numeric is 0-9, or .
|
||||
// string starts with '
|
||||
// variable is alphanumeric, always starts with a letter
|
||||
// bracket always means variable
|
||||
// symbols are anything non-alphanumeric
|
||||
// all others read into a buffer until they reach the end of the stream
|
||||
for stream.canRead() {
|
||||
|
||||
character = stream.readCharacter()
|
||||
|
||||
if unicode.IsSpace(character) {
|
||||
continue
|
||||
}
|
||||
|
||||
kind = UNKNOWN
|
||||
|
||||
// numeric constant
|
||||
if isNumeric(character) {
|
||||
|
||||
tokenString = readTokenUntilFalse(stream, isNumeric)
|
||||
tokenValue, err = strconv.ParseFloat(tokenString, 64)
|
||||
|
||||
if err != nil {
|
||||
errorMsg := fmt.Sprintf("Unable to parse numeric value '%v' to float64\n", tokenString)
|
||||
return ExpressionToken{}, errors.New(errorMsg), false
|
||||
}
|
||||
kind = NUMERIC
|
||||
break
|
||||
}
|
||||
|
||||
// comma, separator
|
||||
if character == ',' {
|
||||
|
||||
tokenValue = ","
|
||||
kind = SEPARATOR
|
||||
break
|
||||
}
|
||||
|
||||
// escaped variable
|
||||
if character == '[' {
|
||||
|
||||
tokenValue, completed = readUntilFalse(stream, true, false, true, isNotClosingBracket)
|
||||
kind = VARIABLE
|
||||
|
||||
if !completed {
|
||||
return ExpressionToken{}, errors.New("Unclosed parameter bracket"), false
|
||||
}
|
||||
|
||||
// above method normally rewinds us to the closing bracket, which we want to skip.
|
||||
stream.rewind(-1)
|
||||
break
|
||||
}
|
||||
|
||||
// regular variable - or function?
|
||||
if unicode.IsLetter(character) {
|
||||
|
||||
tokenString = readTokenUntilFalse(stream, isVariableName)
|
||||
|
||||
tokenValue = tokenString
|
||||
kind = VARIABLE
|
||||
|
||||
// boolean?
|
||||
if tokenValue == "true" {
|
||||
|
||||
kind = BOOLEAN
|
||||
tokenValue = true
|
||||
} else {
|
||||
|
||||
if tokenValue == "false" {
|
||||
|
||||
kind = BOOLEAN
|
||||
tokenValue = false
|
||||
}
|
||||
}
|
||||
|
||||
// textual operator?
|
||||
if tokenValue == "in" || tokenValue == "IN" {
|
||||
|
||||
// force lower case for consistency
|
||||
tokenValue = "in"
|
||||
kind = COMPARATOR
|
||||
}
|
||||
|
||||
// function?
|
||||
function, found = functions[tokenString]
|
||||
if found {
|
||||
kind = FUNCTION
|
||||
tokenValue = function
|
||||
}
|
||||
break
|
||||
}
|
||||
|
||||
if !isNotQuote(character) {
|
||||
tokenValue, completed = readUntilFalse(stream, true, false, true, isNotQuote)
|
||||
|
||||
if !completed {
|
||||
return ExpressionToken{}, errors.New("Unclosed string literal"), false
|
||||
}
|
||||
|
||||
// advance the stream one position, since reading until false assumes the terminator is a real token
|
||||
stream.rewind(-1)
|
||||
|
||||
// check to see if this can be parsed as a time.
|
||||
tokenTime, found = tryParseTime(tokenValue.(string))
|
||||
if found {
|
||||
kind = TIME
|
||||
tokenValue = tokenTime
|
||||
} else {
|
||||
kind = STRING
|
||||
}
|
||||
break
|
||||
}
|
||||
|
||||
if character == '(' {
|
||||
tokenValue = character
|
||||
kind = CLAUSE
|
||||
break
|
||||
}
|
||||
|
||||
if character == ')' {
|
||||
tokenValue = character
|
||||
kind = CLAUSE_CLOSE
|
||||
break
|
||||
}
|
||||
|
||||
// must be a known symbol
|
||||
tokenString = readTokenUntilFalse(stream, isNotAlphanumeric)
|
||||
tokenValue = tokenString
|
||||
|
||||
// quick hack for the case where "-" can mean "prefixed negation" or "minus", which are used
|
||||
// very differently.
|
||||
if state.canTransitionTo(PREFIX) {
|
||||
_, found = prefixSymbols[tokenString]
|
||||
if found {
|
||||
|
||||
kind = PREFIX
|
||||
break
|
||||
}
|
||||
}
|
||||
_, found = modifierSymbols[tokenString]
|
||||
if found {
|
||||
|
||||
kind = MODIFIER
|
||||
break
|
||||
}
|
||||
|
||||
_, found = logicalSymbols[tokenString]
|
||||
if found {
|
||||
|
||||
kind = LOGICALOP
|
||||
break
|
||||
}
|
||||
|
||||
_, found = comparatorSymbols[tokenString]
|
||||
if found {
|
||||
|
||||
kind = COMPARATOR
|
||||
break
|
||||
}
|
||||
|
||||
_, found = ternarySymbols[tokenString]
|
||||
if found {
|
||||
|
||||
kind = TERNARY
|
||||
break
|
||||
}
|
||||
|
||||
errorMessage := fmt.Sprintf("Invalid token: '%s'", tokenString)
|
||||
return ret, errors.New(errorMessage), false
|
||||
}
|
||||
|
||||
ret.Kind = kind
|
||||
ret.Value = tokenValue
|
||||
|
||||
return ret, nil, (kind != UNKNOWN)
|
||||
}
|
||||
|
||||
func readTokenUntilFalse(stream *lexerStream, condition func(rune) bool) string {
|
||||
|
||||
var ret string
|
||||
|
||||
stream.rewind(1)
|
||||
ret, _ = readUntilFalse(stream, false, true, true, condition)
|
||||
return ret
|
||||
}
|
||||
|
||||
/*
|
||||
Returns the string that was read until the given [condition] was false, or whitespace was broken.
|
||||
Returns false if the stream ended before whitespace was broken or condition was met.
|
||||
*/
|
||||
func readUntilFalse(stream *lexerStream, includeWhitespace bool, breakWhitespace bool, allowEscaping bool, condition func(rune) bool) (string, bool) {
|
||||
|
||||
var tokenBuffer bytes.Buffer
|
||||
var character rune
|
||||
var conditioned bool
|
||||
|
||||
conditioned = false
|
||||
|
||||
for stream.canRead() {
|
||||
|
||||
character = stream.readCharacter()
|
||||
|
||||
// Use backslashes to escape anything
|
||||
if allowEscaping && character == '\\' {
|
||||
|
||||
character = stream.readCharacter()
|
||||
tokenBuffer.WriteString(string(character))
|
||||
continue
|
||||
}
|
||||
|
||||
if unicode.IsSpace(character) {
|
||||
|
||||
if breakWhitespace && tokenBuffer.Len() > 0 {
|
||||
conditioned = true
|
||||
break
|
||||
}
|
||||
if !includeWhitespace {
|
||||
continue
|
||||
}
|
||||
}
|
||||
|
||||
if condition(character) {
|
||||
tokenBuffer.WriteString(string(character))
|
||||
} else {
|
||||
conditioned = true
|
||||
stream.rewind(1)
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
return tokenBuffer.String(), conditioned
|
||||
}
|
||||
|
||||
/*
|
||||
Checks to see if any optimizations can be performed on the given [tokens], which form a complete, valid expression.
|
||||
The returns slice will represent the optimized (or unmodified) list of tokens to use.
|
||||
*/
|
||||
func optimizeTokens(tokens []ExpressionToken) ([]ExpressionToken, error) {
|
||||
|
||||
var token ExpressionToken
|
||||
var symbol OperatorSymbol
|
||||
var err error
|
||||
var index int
|
||||
|
||||
for index, token = range tokens {
|
||||
|
||||
// if we find a regex operator, and the right-hand value is a constant, precompile and replace with a pattern.
|
||||
if token.Kind != COMPARATOR {
|
||||
continue
|
||||
}
|
||||
|
||||
symbol = comparatorSymbols[token.Value.(string)]
|
||||
if symbol != REQ && symbol != NREQ {
|
||||
continue
|
||||
}
|
||||
|
||||
index++
|
||||
token = tokens[index]
|
||||
if token.Kind == STRING {
|
||||
|
||||
token.Kind = PATTERN
|
||||
token.Value, err = regexp.Compile(token.Value.(string))
|
||||
|
||||
if err != nil {
|
||||
return tokens, err
|
||||
}
|
||||
|
||||
tokens[index] = token
|
||||
}
|
||||
}
|
||||
return tokens, nil
|
||||
}
|
||||
|
||||
/*
|
||||
Checks the balance of tokens which have multiple parts, such as parenthesis.
|
||||
*/
|
||||
func checkBalance(tokens []ExpressionToken) error {
|
||||
|
||||
var stream *tokenStream
|
||||
var token ExpressionToken
|
||||
var parens int
|
||||
|
||||
stream = newTokenStream(tokens)
|
||||
|
||||
for stream.hasNext() {
|
||||
|
||||
token = stream.next()
|
||||
if token.Kind == CLAUSE {
|
||||
parens++
|
||||
continue
|
||||
}
|
||||
if token.Kind == CLAUSE_CLOSE {
|
||||
parens--
|
||||
continue
|
||||
}
|
||||
}
|
||||
|
||||
if parens != 0 {
|
||||
return errors.New("Unbalanced parenthesis")
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func isNumeric(character rune) bool {
|
||||
|
||||
return unicode.IsDigit(character) || character == '.'
|
||||
}
|
||||
|
||||
func isNotQuote(character rune) bool {
|
||||
|
||||
return character != '\'' && character != '"'
|
||||
}
|
||||
|
||||
func isNotAlphanumeric(character rune) bool {
|
||||
|
||||
return !(unicode.IsDigit(character) ||
|
||||
unicode.IsLetter(character) ||
|
||||
character == '(' ||
|
||||
character == ')' ||
|
||||
!isNotQuote(character))
|
||||
}
|
||||
|
||||
func isVariableName(character rune) bool {
|
||||
|
||||
return unicode.IsLetter(character) ||
|
||||
unicode.IsDigit(character) ||
|
||||
character == '_'
|
||||
}
|
||||
|
||||
func isNotClosingBracket(character rune) bool {
|
||||
|
||||
return character != ']'
|
||||
}
|
||||
|
||||
/*
|
||||
Attempts to parse the [candidate] as a Time.
|
||||
Tries a series of standardized date formats, returns the Time if one applies,
|
||||
otherwise returns false through the second return.
|
||||
*/
|
||||
func tryParseTime(candidate string) (time.Time, bool) {
|
||||
|
||||
var ret time.Time
|
||||
var found bool
|
||||
|
||||
timeFormats := [...]string{
|
||||
time.ANSIC,
|
||||
time.UnixDate,
|
||||
time.RubyDate,
|
||||
time.Kitchen,
|
||||
time.RFC3339,
|
||||
time.RFC3339Nano,
|
||||
"2006-01-02", // RFC 3339
|
||||
"2006-01-02 15:04", // RFC 3339 with minutes
|
||||
"2006-01-02 15:04:05", // RFC 3339 with seconds
|
||||
"2006-01-02 15:04:05-07:00", // RFC 3339 with seconds and timezone
|
||||
"2006-01-02T15Z0700", // ISO8601 with hour
|
||||
"2006-01-02T15:04Z0700", // ISO8601 with minutes
|
||||
"2006-01-02T15:04:05Z0700", // ISO8601 with seconds
|
||||
"2006-01-02T15:04:05.999999999Z0700", // ISO8601 with nanoseconds
|
||||
}
|
||||
|
||||
for _, format := range timeFormats {
|
||||
|
||||
ret, found = tryParseExactTime(candidate, format)
|
||||
if found {
|
||||
return ret, true
|
||||
}
|
||||
}
|
||||
|
||||
return time.Now(), false
|
||||
}
|
||||
|
||||
func tryParseExactTime(candidate string, format string) (time.Time, bool) {
|
||||
|
||||
var ret time.Time
|
||||
var err error
|
||||
|
||||
ret, err = time.ParseInLocation(format, candidate, time.Local)
|
||||
if err != nil {
|
||||
return time.Now(), false
|
||||
}
|
||||
|
||||
return ret, true
|
||||
}
|
||||
71
vendor/github.com/Knetic/govaluate/sanitizedParameters.go
generated
vendored
71
vendor/github.com/Knetic/govaluate/sanitizedParameters.go
generated
vendored
@@ -1,71 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
// sanitizedParameters is a wrapper for Parameters that does sanitization as
|
||||
// parameters are accessed.
|
||||
type sanitizedParameters struct {
|
||||
orig Parameters
|
||||
}
|
||||
|
||||
func (p sanitizedParameters) Get(key string) (interface{}, error) {
|
||||
value, err := p.orig.Get(key)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// should be converted to fixed point?
|
||||
if isFixedPoint(value) {
|
||||
return castFixedPoint(value), nil
|
||||
}
|
||||
|
||||
return value, nil
|
||||
}
|
||||
|
||||
func isFixedPoint(value interface{}) bool {
|
||||
|
||||
switch value.(type) {
|
||||
case uint8:
|
||||
return true
|
||||
case uint16:
|
||||
return true
|
||||
case uint32:
|
||||
return true
|
||||
case uint64:
|
||||
return true
|
||||
case int8:
|
||||
return true
|
||||
case int16:
|
||||
return true
|
||||
case int32:
|
||||
return true
|
||||
case int64:
|
||||
return true
|
||||
case int:
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func castFixedPoint(value interface{}) float64 {
|
||||
switch value.(type) {
|
||||
case uint8:
|
||||
return float64(value.(uint8))
|
||||
case uint16:
|
||||
return float64(value.(uint16))
|
||||
case uint32:
|
||||
return float64(value.(uint32))
|
||||
case uint64:
|
||||
return float64(value.(uint64))
|
||||
case int8:
|
||||
return float64(value.(int8))
|
||||
case int16:
|
||||
return float64(value.(int16))
|
||||
case int32:
|
||||
return float64(value.(int32))
|
||||
case int64:
|
||||
return float64(value.(int64))
|
||||
case int:
|
||||
return float64(value.(int))
|
||||
}
|
||||
|
||||
return 0.0
|
||||
}
|
||||
675
vendor/github.com/Knetic/govaluate/stagePlanner.go
generated
vendored
675
vendor/github.com/Knetic/govaluate/stagePlanner.go
generated
vendored
@@ -1,675 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"time"
|
||||
"fmt"
|
||||
)
|
||||
|
||||
var stageSymbolMap = map[OperatorSymbol]evaluationOperator{
|
||||
EQ: equalStage,
|
||||
NEQ: notEqualStage,
|
||||
GT: gtStage,
|
||||
LT: ltStage,
|
||||
GTE: gteStage,
|
||||
LTE: lteStage,
|
||||
REQ: regexStage,
|
||||
NREQ: notRegexStage,
|
||||
AND: andStage,
|
||||
OR: orStage,
|
||||
IN: inStage,
|
||||
BITWISE_OR: bitwiseOrStage,
|
||||
BITWISE_AND: bitwiseAndStage,
|
||||
BITWISE_XOR: bitwiseXORStage,
|
||||
BITWISE_LSHIFT: leftShiftStage,
|
||||
BITWISE_RSHIFT: rightShiftStage,
|
||||
PLUS: addStage,
|
||||
MINUS: subtractStage,
|
||||
MULTIPLY: multiplyStage,
|
||||
DIVIDE: divideStage,
|
||||
MODULUS: modulusStage,
|
||||
EXPONENT: exponentStage,
|
||||
NEGATE: negateStage,
|
||||
INVERT: invertStage,
|
||||
BITWISE_NOT: bitwiseNotStage,
|
||||
TERNARY_TRUE: ternaryIfStage,
|
||||
TERNARY_FALSE: ternaryElseStage,
|
||||
COALESCE: ternaryElseStage,
|
||||
SEPARATE: separatorStage,
|
||||
}
|
||||
|
||||
/*
|
||||
A "precedent" is a function which will recursively parse new evaluateionStages from a given stream of tokens.
|
||||
It's called a `precedent` because it is expected to handle exactly what precedence of operator,
|
||||
and defer to other `precedent`s for other operators.
|
||||
*/
|
||||
type precedent func(stream *tokenStream) (*evaluationStage, error)
|
||||
|
||||
/*
|
||||
A convenience function for specifying the behavior of a `precedent`.
|
||||
Most `precedent` functions can be described by the same function, just with different type checks, symbols, and error formats.
|
||||
This struct is passed to `makePrecedentFromPlanner` to create a `precedent` function.
|
||||
*/
|
||||
type precedencePlanner struct {
|
||||
validSymbols map[string]OperatorSymbol
|
||||
validKinds []TokenKind
|
||||
|
||||
typeErrorFormat string
|
||||
|
||||
next precedent
|
||||
nextRight precedent
|
||||
}
|
||||
|
||||
var planPrefix precedent
|
||||
var planExponential precedent
|
||||
var planMultiplicative precedent
|
||||
var planAdditive precedent
|
||||
var planBitwise precedent
|
||||
var planShift precedent
|
||||
var planComparator precedent
|
||||
var planLogicalAnd precedent
|
||||
var planLogicalOr precedent
|
||||
var planTernary precedent
|
||||
var planSeparator precedent
|
||||
|
||||
func init() {
|
||||
|
||||
// all these stages can use the same code (in `planPrecedenceLevel`) to execute,
|
||||
// they simply need different type checks, symbols, and recursive precedents.
|
||||
// While not all precedent phases are listed here, most can be represented this way.
|
||||
planPrefix = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: prefixSymbols,
|
||||
validKinds: []TokenKind{PREFIX},
|
||||
typeErrorFormat: prefixErrorFormat,
|
||||
nextRight: planFunction,
|
||||
})
|
||||
planExponential = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: exponentialSymbolsS,
|
||||
validKinds: []TokenKind{MODIFIER},
|
||||
typeErrorFormat: modifierErrorFormat,
|
||||
next: planFunction,
|
||||
})
|
||||
planMultiplicative = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: multiplicativeSymbols,
|
||||
validKinds: []TokenKind{MODIFIER},
|
||||
typeErrorFormat: modifierErrorFormat,
|
||||
next: planExponential,
|
||||
})
|
||||
planAdditive = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: additiveSymbols,
|
||||
validKinds: []TokenKind{MODIFIER},
|
||||
typeErrorFormat: modifierErrorFormat,
|
||||
next: planMultiplicative,
|
||||
})
|
||||
planShift = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: bitwiseShiftSymbols,
|
||||
validKinds: []TokenKind{MODIFIER},
|
||||
typeErrorFormat: modifierErrorFormat,
|
||||
next: planAdditive,
|
||||
})
|
||||
planBitwise = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: bitwiseSymbols,
|
||||
validKinds: []TokenKind{MODIFIER},
|
||||
typeErrorFormat: modifierErrorFormat,
|
||||
next: planShift,
|
||||
})
|
||||
planComparator = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: comparatorSymbols,
|
||||
validKinds: []TokenKind{COMPARATOR},
|
||||
typeErrorFormat: comparatorErrorFormat,
|
||||
next: planBitwise,
|
||||
})
|
||||
planLogicalAnd = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: map[string]OperatorSymbol{"&&": AND},
|
||||
validKinds: []TokenKind{LOGICALOP},
|
||||
typeErrorFormat: logicalErrorFormat,
|
||||
next: planComparator,
|
||||
})
|
||||
planLogicalOr = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: map[string]OperatorSymbol{"||": OR},
|
||||
validKinds: []TokenKind{LOGICALOP},
|
||||
typeErrorFormat: logicalErrorFormat,
|
||||
next: planLogicalAnd,
|
||||
})
|
||||
planTernary = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: ternarySymbols,
|
||||
validKinds: []TokenKind{TERNARY},
|
||||
typeErrorFormat: ternaryErrorFormat,
|
||||
next: planLogicalOr,
|
||||
})
|
||||
planSeparator = makePrecedentFromPlanner(&precedencePlanner{
|
||||
validSymbols: separatorSymbols,
|
||||
validKinds: []TokenKind{SEPARATOR},
|
||||
next: planTernary,
|
||||
})
|
||||
}
|
||||
|
||||
/*
|
||||
Given a planner, creates a function which will evaluate a specific precedence level of operators,
|
||||
and link it to other `precedent`s which recurse to parse other precedence levels.
|
||||
*/
|
||||
func makePrecedentFromPlanner(planner *precedencePlanner) precedent {
|
||||
|
||||
var generated precedent
|
||||
var nextRight precedent
|
||||
|
||||
generated = func(stream *tokenStream) (*evaluationStage, error) {
|
||||
return planPrecedenceLevel(
|
||||
stream,
|
||||
planner.typeErrorFormat,
|
||||
planner.validSymbols,
|
||||
planner.validKinds,
|
||||
nextRight,
|
||||
planner.next,
|
||||
)
|
||||
}
|
||||
|
||||
if planner.nextRight != nil {
|
||||
nextRight = planner.nextRight
|
||||
} else {
|
||||
nextRight = generated
|
||||
}
|
||||
|
||||
return generated
|
||||
}
|
||||
|
||||
/*
|
||||
Creates a `evaluationStageList` object which represents an execution plan (or tree)
|
||||
which is used to completely evaluate a set of tokens at evaluation-time.
|
||||
The three stages of evaluation can be thought of as parsing strings to tokens, then tokens to a stage list, then evaluation with parameters.
|
||||
*/
|
||||
func planStages(tokens []ExpressionToken) (*evaluationStage, error) {
|
||||
|
||||
stream := newTokenStream(tokens)
|
||||
|
||||
stage, err := planTokens(stream)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// while we're now fully-planned, we now need to re-order same-precedence operators.
|
||||
// this could probably be avoided with a different planning method
|
||||
reorderStages(stage)
|
||||
|
||||
stage = elideLiterals(stage)
|
||||
return stage, nil
|
||||
}
|
||||
|
||||
func planTokens(stream *tokenStream) (*evaluationStage, error) {
|
||||
|
||||
if !stream.hasNext() {
|
||||
return nil, nil
|
||||
}
|
||||
|
||||
return planSeparator(stream)
|
||||
}
|
||||
|
||||
/*
|
||||
The most usual method of parsing an evaluation stage for a given precedence.
|
||||
Most stages use the same logic
|
||||
*/
|
||||
func planPrecedenceLevel(
|
||||
stream *tokenStream,
|
||||
typeErrorFormat string,
|
||||
validSymbols map[string]OperatorSymbol,
|
||||
validKinds []TokenKind,
|
||||
rightPrecedent precedent,
|
||||
leftPrecedent precedent) (*evaluationStage, error) {
|
||||
|
||||
var token ExpressionToken
|
||||
var symbol OperatorSymbol
|
||||
var leftStage, rightStage *evaluationStage
|
||||
var checks typeChecks
|
||||
var err error
|
||||
var keyFound bool
|
||||
|
||||
if leftPrecedent != nil {
|
||||
|
||||
leftStage, err = leftPrecedent(stream)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
}
|
||||
|
||||
for stream.hasNext() {
|
||||
|
||||
token = stream.next()
|
||||
|
||||
if len(validKinds) > 0 {
|
||||
|
||||
keyFound = false
|
||||
for _, kind := range validKinds {
|
||||
if kind == token.Kind {
|
||||
keyFound = true
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
if !keyFound {
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
if validSymbols != nil {
|
||||
|
||||
if !isString(token.Value) {
|
||||
break
|
||||
}
|
||||
|
||||
symbol, keyFound = validSymbols[token.Value.(string)]
|
||||
if !keyFound {
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
if rightPrecedent != nil {
|
||||
rightStage, err = rightPrecedent(stream)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
}
|
||||
|
||||
checks = findTypeChecks(symbol)
|
||||
|
||||
return &evaluationStage{
|
||||
|
||||
symbol: symbol,
|
||||
leftStage: leftStage,
|
||||
rightStage: rightStage,
|
||||
operator: stageSymbolMap[symbol],
|
||||
|
||||
leftTypeCheck: checks.left,
|
||||
rightTypeCheck: checks.right,
|
||||
typeCheck: checks.combined,
|
||||
typeErrorFormat: typeErrorFormat,
|
||||
}, nil
|
||||
}
|
||||
|
||||
stream.rewind()
|
||||
return leftStage, nil
|
||||
}
|
||||
|
||||
/*
|
||||
A special case where functions need to be of higher precedence than values, and need a special wrapped execution stage operator.
|
||||
*/
|
||||
func planFunction(stream *tokenStream) (*evaluationStage, error) {
|
||||
|
||||
var token ExpressionToken
|
||||
var rightStage *evaluationStage
|
||||
var err error
|
||||
|
||||
token = stream.next()
|
||||
|
||||
if token.Kind != FUNCTION {
|
||||
stream.rewind()
|
||||
return planValue(stream)
|
||||
}
|
||||
|
||||
rightStage, err = planValue(stream)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return &evaluationStage{
|
||||
|
||||
symbol: FUNCTIONAL,
|
||||
rightStage: rightStage,
|
||||
operator: makeFunctionStage(token.Value.(ExpressionFunction)),
|
||||
typeErrorFormat: "Unable to run function '%v': %v",
|
||||
}, nil
|
||||
}
|
||||
|
||||
/*
|
||||
A truly special precedence function, this handles all the "lowest-case" errata of the process, including literals, parmeters,
|
||||
clauses, and prefixes.
|
||||
*/
|
||||
func planValue(stream *tokenStream) (*evaluationStage, error) {
|
||||
|
||||
var token ExpressionToken
|
||||
var symbol OperatorSymbol
|
||||
var ret *evaluationStage
|
||||
var operator evaluationOperator
|
||||
var err error
|
||||
|
||||
token = stream.next()
|
||||
|
||||
switch token.Kind {
|
||||
|
||||
case CLAUSE:
|
||||
|
||||
ret, err = planTokens(stream)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// advance past the CLAUSE_CLOSE token. We know that it's a CLAUSE_CLOSE, because at parse-time we check for unbalanced parens.
|
||||
stream.next()
|
||||
|
||||
// the stage we got represents all of the logic contained within the parens
|
||||
// but for technical reasons, we need to wrap this stage in a "noop" stage which breaks long chains of precedence.
|
||||
// see github #33.
|
||||
ret = &evaluationStage {
|
||||
rightStage: ret,
|
||||
operator: noopStageRight,
|
||||
symbol: NOOP,
|
||||
}
|
||||
|
||||
return ret, nil
|
||||
|
||||
case CLAUSE_CLOSE:
|
||||
|
||||
// when functions have empty params, this will be hit. In this case, we don't have any evaluation stage to do,
|
||||
// so we just return nil so that the stage planner continues on its way.
|
||||
stream.rewind()
|
||||
return nil, nil
|
||||
|
||||
case VARIABLE:
|
||||
operator = makeParameterStage(token.Value.(string))
|
||||
|
||||
case NUMERIC:
|
||||
fallthrough
|
||||
case STRING:
|
||||
fallthrough
|
||||
case PATTERN:
|
||||
fallthrough
|
||||
case BOOLEAN:
|
||||
symbol = LITERAL
|
||||
operator = makeLiteralStage(token.Value)
|
||||
case TIME:
|
||||
symbol = LITERAL
|
||||
operator = makeLiteralStage(float64(token.Value.(time.Time).Unix()))
|
||||
|
||||
case PREFIX:
|
||||
stream.rewind()
|
||||
return planPrefix(stream)
|
||||
}
|
||||
|
||||
if operator == nil {
|
||||
errorMsg := fmt.Sprintf("Unable to plan token kind: '%s', value: '%v'", token.Kind.String(), token.Value)
|
||||
return nil, errors.New(errorMsg)
|
||||
}
|
||||
|
||||
return &evaluationStage{
|
||||
symbol: symbol,
|
||||
operator: operator,
|
||||
}, nil
|
||||
}
|
||||
|
||||
/*
|
||||
Convenience function to pass a triplet of typechecks between `findTypeChecks` and `planPrecedenceLevel`.
|
||||
Each of these members may be nil, which indicates that type does not matter for that value.
|
||||
*/
|
||||
type typeChecks struct {
|
||||
left stageTypeCheck
|
||||
right stageTypeCheck
|
||||
combined stageCombinedTypeCheck
|
||||
}
|
||||
|
||||
/*
|
||||
Maps a given [symbol] to a set of typechecks to be used during runtime.
|
||||
*/
|
||||
func findTypeChecks(symbol OperatorSymbol) typeChecks {
|
||||
|
||||
switch symbol {
|
||||
case GT:
|
||||
fallthrough
|
||||
case LT:
|
||||
fallthrough
|
||||
case GTE:
|
||||
fallthrough
|
||||
case LTE:
|
||||
return typeChecks{
|
||||
combined: comparatorTypeCheck,
|
||||
}
|
||||
case REQ:
|
||||
fallthrough
|
||||
case NREQ:
|
||||
return typeChecks{
|
||||
left: isString,
|
||||
right: isRegexOrString,
|
||||
}
|
||||
case AND:
|
||||
fallthrough
|
||||
case OR:
|
||||
return typeChecks{
|
||||
left: isBool,
|
||||
right: isBool,
|
||||
}
|
||||
case IN:
|
||||
return typeChecks{
|
||||
right: isArray,
|
||||
}
|
||||
case BITWISE_LSHIFT:
|
||||
fallthrough
|
||||
case BITWISE_RSHIFT:
|
||||
fallthrough
|
||||
case BITWISE_OR:
|
||||
fallthrough
|
||||
case BITWISE_AND:
|
||||
fallthrough
|
||||
case BITWISE_XOR:
|
||||
return typeChecks{
|
||||
left: isFloat64,
|
||||
right: isFloat64,
|
||||
}
|
||||
case PLUS:
|
||||
return typeChecks{
|
||||
combined: additionTypeCheck,
|
||||
}
|
||||
case MINUS:
|
||||
fallthrough
|
||||
case MULTIPLY:
|
||||
fallthrough
|
||||
case DIVIDE:
|
||||
fallthrough
|
||||
case MODULUS:
|
||||
fallthrough
|
||||
case EXPONENT:
|
||||
return typeChecks{
|
||||
left: isFloat64,
|
||||
right: isFloat64,
|
||||
}
|
||||
case NEGATE:
|
||||
return typeChecks{
|
||||
right: isFloat64,
|
||||
}
|
||||
case INVERT:
|
||||
return typeChecks{
|
||||
right: isBool,
|
||||
}
|
||||
case BITWISE_NOT:
|
||||
return typeChecks{
|
||||
right: isFloat64,
|
||||
}
|
||||
case TERNARY_TRUE:
|
||||
return typeChecks{
|
||||
left: isBool,
|
||||
}
|
||||
|
||||
// unchecked cases
|
||||
case EQ:
|
||||
fallthrough
|
||||
case NEQ:
|
||||
return typeChecks{}
|
||||
case TERNARY_FALSE:
|
||||
fallthrough
|
||||
case COALESCE:
|
||||
fallthrough
|
||||
default:
|
||||
return typeChecks{}
|
||||
}
|
||||
}
|
||||
|
||||
/*
|
||||
During stage planning, stages of equal precedence are parsed such that they'll be evaluated in reverse order.
|
||||
For commutative operators like "+" or "-", it's no big deal. But for order-specific operators, it ruins the expected result.
|
||||
*/
|
||||
func reorderStages(rootStage *evaluationStage) {
|
||||
|
||||
// traverse every rightStage until we find multiples in a row of the same precedence.
|
||||
var identicalPrecedences []*evaluationStage
|
||||
var currentStage, nextStage *evaluationStage
|
||||
var precedence, currentPrecedence operatorPrecedence
|
||||
|
||||
nextStage = rootStage
|
||||
precedence = findOperatorPrecedenceForSymbol(rootStage.symbol)
|
||||
|
||||
for nextStage != nil {
|
||||
|
||||
currentStage = nextStage
|
||||
nextStage = currentStage.rightStage
|
||||
|
||||
// left depth first, since this entire method only looks for precedences down the right side of the tree
|
||||
if currentStage.leftStage != nil {
|
||||
reorderStages(currentStage.leftStage)
|
||||
}
|
||||
|
||||
currentPrecedence = findOperatorPrecedenceForSymbol(currentStage.symbol)
|
||||
|
||||
if currentPrecedence == precedence {
|
||||
identicalPrecedences = append(identicalPrecedences, currentStage)
|
||||
continue
|
||||
}
|
||||
|
||||
// precedence break.
|
||||
// See how many in a row we had, and reorder if there's more than one.
|
||||
if len(identicalPrecedences) > 1 {
|
||||
mirrorStageSubtree(identicalPrecedences)
|
||||
}
|
||||
|
||||
identicalPrecedences = []*evaluationStage{currentStage}
|
||||
precedence = currentPrecedence
|
||||
}
|
||||
|
||||
if len(identicalPrecedences) > 1 {
|
||||
mirrorStageSubtree(identicalPrecedences)
|
||||
}
|
||||
}
|
||||
|
||||
/*
|
||||
Performs a "mirror" on a subtree of stages.
|
||||
This mirror functionally inverts the order of execution for all members of the [stages] list.
|
||||
That list is assumed to be a root-to-leaf (ordered) list of evaluation stages, where each is a right-hand stage of the last.
|
||||
*/
|
||||
func mirrorStageSubtree(stages []*evaluationStage) {
|
||||
|
||||
var rootStage, inverseStage, carryStage, frontStage *evaluationStage
|
||||
|
||||
stagesLength := len(stages)
|
||||
|
||||
// reverse all right/left
|
||||
for _, frontStage = range stages {
|
||||
|
||||
carryStage = frontStage.rightStage
|
||||
frontStage.rightStage = frontStage.leftStage
|
||||
frontStage.leftStage = carryStage
|
||||
}
|
||||
|
||||
// end left swaps with root right
|
||||
rootStage = stages[0]
|
||||
frontStage = stages[stagesLength-1]
|
||||
|
||||
carryStage = frontStage.leftStage
|
||||
frontStage.leftStage = rootStage.rightStage
|
||||
rootStage.rightStage = carryStage
|
||||
|
||||
// for all non-root non-end stages, right is swapped with inverse stage right in list
|
||||
for i := 0; i < (stagesLength-2)/2+1; i++ {
|
||||
|
||||
frontStage = stages[i+1]
|
||||
inverseStage = stages[stagesLength-i-1]
|
||||
|
||||
carryStage = frontStage.rightStage
|
||||
frontStage.rightStage = inverseStage.rightStage
|
||||
inverseStage.rightStage = carryStage
|
||||
}
|
||||
|
||||
// swap all other information with inverse stages
|
||||
for i := 0; i < stagesLength/2; i++ {
|
||||
|
||||
frontStage = stages[i]
|
||||
inverseStage = stages[stagesLength-i-1]
|
||||
frontStage.swapWith(inverseStage)
|
||||
}
|
||||
}
|
||||
|
||||
/*
|
||||
Recurses through all operators in the entire tree, eliding operators where both sides are literals.
|
||||
*/
|
||||
func elideLiterals(root *evaluationStage) *evaluationStage {
|
||||
|
||||
if root.leftStage != nil {
|
||||
root.leftStage = elideLiterals(root.leftStage)
|
||||
}
|
||||
|
||||
if root.rightStage != nil {
|
||||
root.rightStage = elideLiterals(root.rightStage)
|
||||
}
|
||||
|
||||
return elideStage(root)
|
||||
}
|
||||
|
||||
/*
|
||||
Elides a specific stage, if possible.
|
||||
Returns the unmodified [root] stage if it cannot or should not be elided.
|
||||
Otherwise, returns a new stage representing the condensed value from the elided stages.
|
||||
*/
|
||||
func elideStage(root *evaluationStage) *evaluationStage {
|
||||
|
||||
var leftValue, rightValue, result interface{}
|
||||
var err error
|
||||
|
||||
// right side must be a non-nil value. Left side must be nil or a value.
|
||||
if root.rightStage == nil ||
|
||||
root.rightStage.symbol != LITERAL ||
|
||||
root.leftStage == nil ||
|
||||
root.leftStage.symbol != LITERAL {
|
||||
return root
|
||||
}
|
||||
|
||||
// don't elide some operators
|
||||
switch root.symbol {
|
||||
case SEPARATE:
|
||||
fallthrough
|
||||
case IN:
|
||||
return root
|
||||
}
|
||||
|
||||
// both sides are values, get their actual values.
|
||||
// errors should be near-impossible here. If we encounter them, just abort this optimization.
|
||||
leftValue, err = root.leftStage.operator(nil, nil, nil)
|
||||
if err != nil {
|
||||
return root
|
||||
}
|
||||
|
||||
rightValue, err = root.rightStage.operator(nil, nil, nil)
|
||||
if err != nil {
|
||||
return root
|
||||
}
|
||||
|
||||
// typcheck, since the grammar checker is a bit loose with which operator symbols go together.
|
||||
err = typeCheck(root.leftTypeCheck, leftValue, root.symbol, root.typeErrorFormat)
|
||||
if err != nil {
|
||||
return root
|
||||
}
|
||||
|
||||
err = typeCheck(root.rightTypeCheck, rightValue, root.symbol, root.typeErrorFormat)
|
||||
if err != nil {
|
||||
return root
|
||||
}
|
||||
|
||||
if root.typeCheck != nil && !root.typeCheck(leftValue, rightValue) {
|
||||
return root
|
||||
}
|
||||
|
||||
// pre-calculate, and return a new stage representing the result.
|
||||
result, err = root.operator(leftValue, rightValue, nil)
|
||||
if err != nil {
|
||||
return root
|
||||
}
|
||||
|
||||
return &evaluationStage {
|
||||
symbol: LITERAL,
|
||||
operator: makeLiteralStage(result),
|
||||
}
|
||||
}
|
||||
32
vendor/github.com/Knetic/govaluate/test.sh
generated
vendored
32
vendor/github.com/Knetic/govaluate/test.sh
generated
vendored
@@ -1,32 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
# Script that runs tests, code coverage, and benchmarks all at once.
|
||||
# Builds a symlink in /tmp, mostly to avoid messing with GOPATH at the user's shell level.
|
||||
|
||||
TEMPORARY_PATH="/tmp/govaluate_test"
|
||||
SRC_PATH="${TEMPORARY_PATH}/src"
|
||||
FULL_PATH="${TEMPORARY_PATH}/src/govaluate"
|
||||
|
||||
# set up temporary directory
|
||||
rm -rf "${FULL_PATH}"
|
||||
mkdir -p "${SRC_PATH}"
|
||||
|
||||
ln -s $(pwd) "${FULL_PATH}"
|
||||
export GOPATH="${TEMPORARY_PATH}"
|
||||
|
||||
pushd "${TEMPORARY_PATH}/src/govaluate"
|
||||
|
||||
# run the actual tests.
|
||||
export GOVALUATE_TORTURE_TEST="true"
|
||||
go test -bench=. -benchmem -coverprofile coverage.out
|
||||
status=$?
|
||||
|
||||
if [ "${status}" != 0 ];
|
||||
then
|
||||
exit $status
|
||||
fi
|
||||
|
||||
# coverage
|
||||
go tool cover -func=coverage.out
|
||||
|
||||
popd
|
||||
36
vendor/github.com/Knetic/govaluate/tokenStream.go
generated
vendored
36
vendor/github.com/Knetic/govaluate/tokenStream.go
generated
vendored
@@ -1,36 +0,0 @@
|
||||
package govaluate
|
||||
|
||||
type tokenStream struct {
|
||||
tokens []ExpressionToken
|
||||
index int
|
||||
tokenLength int
|
||||
}
|
||||
|
||||
func newTokenStream(tokens []ExpressionToken) *tokenStream {
|
||||
|
||||
var ret *tokenStream
|
||||
|
||||
ret = new(tokenStream)
|
||||
ret.tokens = tokens
|
||||
ret.tokenLength = len(tokens)
|
||||
return ret
|
||||
}
|
||||
|
||||
func (this *tokenStream) rewind() {
|
||||
this.index -= 1
|
||||
}
|
||||
|
||||
func (this *tokenStream) next() ExpressionToken {
|
||||
|
||||
var token ExpressionToken
|
||||
|
||||
token = this.tokens[this.index]
|
||||
|
||||
this.index += 1
|
||||
return token
|
||||
}
|
||||
|
||||
func (this tokenStream) hasNext() bool {
|
||||
|
||||
return this.index < this.tokenLength
|
||||
}
|
||||
22
vendor/github.com/beego/goyaml2/.gitignore
generated
vendored
22
vendor/github.com/beego/goyaml2/.gitignore
generated
vendored
@@ -1,22 +0,0 @@
|
||||
# Compiled Object files, Static and Dynamic libs (Shared Objects)
|
||||
*.o
|
||||
*.a
|
||||
*.so
|
||||
|
||||
# Folders
|
||||
_obj
|
||||
_test
|
||||
|
||||
# Architecture specific extensions/prefixes
|
||||
*.[568vq]
|
||||
[568vq].out
|
||||
|
||||
*.cgo1.go
|
||||
*.cgo2.c
|
||||
_cgo_defun.c
|
||||
_cgo_gotypes.go
|
||||
_cgo_export.*
|
||||
|
||||
_testmain.go
|
||||
|
||||
*.exe
|
||||
4
vendor/github.com/beego/goyaml2/README.md
generated
vendored
4
vendor/github.com/beego/goyaml2/README.md
generated
vendored
@@ -1,4 +0,0 @@
|
||||
goyaml2
|
||||
=======
|
||||
|
||||
YAML for Golang
|
||||
41
vendor/github.com/beego/goyaml2/conv.go
generated
vendored
41
vendor/github.com/beego/goyaml2/conv.go
generated
vendored
@@ -1,41 +0,0 @@
|
||||
package goyaml2
|
||||
|
||||
import (
|
||||
"regexp"
|
||||
"strconv"
|
||||
//"time"
|
||||
)
|
||||
|
||||
var (
|
||||
RE_INT, _ = regexp.Compile("^[0-9,]+$")
|
||||
RE_FLOAT, _ = regexp.Compile("^[0-9]+[.][0-9]+$")
|
||||
RE_DATE, _ = regexp.Compile("^[0-9]{4}-[0-9]{2}-[0-9]{2}$")
|
||||
RE_TIME, _ = regexp.Compile("^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}$")
|
||||
)
|
||||
|
||||
func string2Val(str string) interface{} {
|
||||
tmp := []byte(str)
|
||||
switch {
|
||||
case str == "false":
|
||||
return false
|
||||
case str == "true":
|
||||
return true
|
||||
case RE_INT.Match(tmp):
|
||||
// TODO check err
|
||||
_int, _ := strconv.ParseInt(str, 10, 64)
|
||||
return _int
|
||||
case RE_FLOAT.Match(tmp):
|
||||
_float, _ := strconv.ParseFloat(str, 64)
|
||||
return _float
|
||||
//TODO support time or Not?
|
||||
/*
|
||||
case RE_DATE.Match(tmp):
|
||||
_date, _ := time.Parse("2006-01-02", str)
|
||||
return _date
|
||||
case RE_TIME.Match(tmp):
|
||||
_time, _ := time.Parse("2006-01-02 03:04:05", str)
|
||||
return _time
|
||||
*/
|
||||
}
|
||||
return str
|
||||
}
|
||||
433
vendor/github.com/beego/goyaml2/reader.go
generated
vendored
433
vendor/github.com/beego/goyaml2/reader.go
generated
vendored
@@ -1,433 +0,0 @@
|
||||
package goyaml2
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"fmt"
|
||||
"github.com/wendal/errors"
|
||||
"io"
|
||||
"log"
|
||||
"strings"
|
||||
)
|
||||
|
||||
const (
|
||||
DEBUG = true
|
||||
MAP_KEY_ONLY = iota
|
||||
)
|
||||
|
||||
func Read(r io.Reader) (interface{}, error) {
|
||||
yr := &yamlReader{}
|
||||
yr.br = bufio.NewReader(r)
|
||||
obj, err := yr.ReadObject(0)
|
||||
if err == io.EOF {
|
||||
err = nil
|
||||
}
|
||||
if obj == nil {
|
||||
log.Println("Obj == nil")
|
||||
}
|
||||
return obj, err
|
||||
}
|
||||
|
||||
type yamlReader struct {
|
||||
br *bufio.Reader
|
||||
nodes []interface{}
|
||||
lineNum int
|
||||
lastLine string
|
||||
}
|
||||
|
||||
func (y *yamlReader) ReadObject(minIndent int) (interface{}, error) {
|
||||
line, err := y.NextLine()
|
||||
if err != nil {
|
||||
if err == io.EOF && line != "" {
|
||||
//log.Println("Read EOF , but still some data here")
|
||||
} else {
|
||||
//log.Println("ReadERR", err)
|
||||
return nil, err
|
||||
}
|
||||
}
|
||||
y.lastLine = line
|
||||
indent, str := getIndent(line)
|
||||
if indent < minIndent {
|
||||
//log.Println("Current Indent Unexpect : ", str, indent, minIndent)
|
||||
return nil, y.Error("Unexpect Indent", nil)
|
||||
}
|
||||
if indent > minIndent {
|
||||
//log.Println("Change minIndent from %d to %d", minIndent, indent)
|
||||
minIndent = indent
|
||||
}
|
||||
switch str[0] {
|
||||
case '-':
|
||||
return y.ReadList(minIndent)
|
||||
case '[':
|
||||
fallthrough
|
||||
case '{':
|
||||
y.lastLine = ""
|
||||
_, value, err := y.asMapKeyValue("tmp:" + str)
|
||||
if err != nil {
|
||||
return nil, y.Error("Err inline map/list", nil)
|
||||
}
|
||||
return value, nil
|
||||
}
|
||||
//log.Println("Read Objcet as Map", indent, str)
|
||||
|
||||
return y.ReadMap(minIndent)
|
||||
|
||||
}
|
||||
|
||||
func (y *yamlReader) ReadList(minIndent int) ([]interface{}, error) {
|
||||
list := []interface{}{}
|
||||
for {
|
||||
line, err := y.NextLine()
|
||||
if err != nil {
|
||||
return list, err
|
||||
}
|
||||
indent, str := getIndent(line)
|
||||
switch {
|
||||
case indent < minIndent:
|
||||
y.lastLine = line
|
||||
if len(list) == 0 {
|
||||
return nil, nil
|
||||
}
|
||||
return list, nil
|
||||
case indent == minIndent:
|
||||
if str[0] != '-' {
|
||||
y.lastLine = line
|
||||
return list, nil
|
||||
}
|
||||
if len(str) < 2 {
|
||||
return nil, y.Error("ListItem is Emtry", nil)
|
||||
}
|
||||
key, value, err := y.asMapKeyValue(str[1:])
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
switch value {
|
||||
case nil:
|
||||
list = append(list, key)
|
||||
case MAP_KEY_ONLY:
|
||||
return nil, y.Error("Not support List-Map yet", nil)
|
||||
default:
|
||||
_map := map[string]interface{}{key.(string): value}
|
||||
list = append(list, _map)
|
||||
|
||||
_line, _err := y.NextLine()
|
||||
if _err != nil && _err != io.EOF {
|
||||
return nil, err
|
||||
}
|
||||
if _line == "" {
|
||||
return list, nil
|
||||
}
|
||||
y.lastLine = _line
|
||||
_indent, _str := getIndent(line)
|
||||
if _indent >= minIndent+2 {
|
||||
switch _str[0] {
|
||||
case '-':
|
||||
return nil, y.Error("Unexpect", nil)
|
||||
case '[':
|
||||
return nil, y.Error("Unexpect", nil)
|
||||
case '{':
|
||||
return nil, y.Error("Unexpect", nil)
|
||||
}
|
||||
// look like a map
|
||||
_map2, _err := y.ReadMap(_indent)
|
||||
if _map2 != nil {
|
||||
_map2[key.(string)] = value
|
||||
}
|
||||
if err != nil {
|
||||
return list, _err
|
||||
}
|
||||
}
|
||||
}
|
||||
continue
|
||||
default:
|
||||
return nil, y.Error("Bad Indent\n"+line, nil)
|
||||
}
|
||||
}
|
||||
panic("ERROR")
|
||||
return nil, errors.New("Impossible")
|
||||
}
|
||||
|
||||
func (y *yamlReader) ReadMap(minIndent int) (map[string]interface{}, error) {
|
||||
_map := map[string]interface{}{}
|
||||
//log.Println("ReadMap", minIndent)
|
||||
OUT:
|
||||
for {
|
||||
line, err := y.NextLine()
|
||||
if err != nil {
|
||||
return _map, err
|
||||
}
|
||||
indent, str := getIndent(line)
|
||||
//log.Printf("Indent : %d, str = %s", indent, str)
|
||||
switch {
|
||||
case indent < minIndent:
|
||||
y.lastLine = line
|
||||
if len(_map) == 0 {
|
||||
return nil, nil
|
||||
}
|
||||
return _map, nil
|
||||
case indent == minIndent:
|
||||
key, value, err := y.asMapKeyValue(str)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
//log.Println("Key=", key, "value=", value)
|
||||
switch value {
|
||||
case nil:
|
||||
return nil, y.Error("Unexpect", nil)
|
||||
case MAP_KEY_ONLY:
|
||||
//log.Println("KeyOnly, read inner Map", key)
|
||||
|
||||
//--------------------------------------
|
||||
_line, err := y.NextLine()
|
||||
if err != nil {
|
||||
if err == io.EOF {
|
||||
if _line == "" {
|
||||
// Emtry map item?
|
||||
_map[key.(string)] = nil
|
||||
return _map, err
|
||||
}
|
||||
} else {
|
||||
return nil, y.Error("ERR?", err)
|
||||
}
|
||||
}
|
||||
y.lastLine = _line
|
||||
_indent, _str := getIndent(_line)
|
||||
if _indent < minIndent {
|
||||
return _map, nil
|
||||
}
|
||||
////log.Println("##>>", _indent, _str)
|
||||
if _indent == minIndent {
|
||||
if _str[0] == '-' {
|
||||
//log.Println("Read Same-Indent ListItem for Map")
|
||||
_list, err := y.ReadList(minIndent)
|
||||
if _list != nil {
|
||||
_map[key.(string)] = _list
|
||||
}
|
||||
if err != nil {
|
||||
return _map, nil
|
||||
}
|
||||
continue OUT
|
||||
} else {
|
||||
// Emtry map item?
|
||||
_map[key.(string)] = nil
|
||||
continue OUT
|
||||
}
|
||||
}
|
||||
//--------------------------------------
|
||||
//log.Println("Read Map Item", _indent, _str)
|
||||
|
||||
obj, err := y.ReadObject(_indent)
|
||||
if obj != nil {
|
||||
_map[key.(string)] = obj
|
||||
}
|
||||
if err != nil {
|
||||
return _map, err
|
||||
}
|
||||
default:
|
||||
_map[key.(string)] = value
|
||||
}
|
||||
default:
|
||||
//log.Println("Bad", indent, str)
|
||||
return nil, y.Error("Bad Indent\n"+line, nil)
|
||||
}
|
||||
}
|
||||
panic("ERROR")
|
||||
return nil, errors.New("Impossible")
|
||||
|
||||
}
|
||||
|
||||
func (y *yamlReader) NextLine() (line string, err error) {
|
||||
if y.lastLine != "" {
|
||||
line = y.lastLine
|
||||
y.lastLine = ""
|
||||
//log.Println("Return lastLine", line)
|
||||
return
|
||||
}
|
||||
for {
|
||||
line, err = y.br.ReadString('\n')
|
||||
y.lineNum++
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
if strings.HasPrefix(line, "---") || strings.HasPrefix(line, "#") {
|
||||
continue
|
||||
}
|
||||
|
||||
line = strings.TrimRight(line, "\n\t\r ")
|
||||
if line == "" {
|
||||
continue
|
||||
}
|
||||
//log.Println("Return Line", line)
|
||||
return
|
||||
}
|
||||
//log.Println("Impossbible : " + line)
|
||||
return // impossbile!
|
||||
}
|
||||
|
||||
func getIndent(str string) (int, string) {
|
||||
indent := 0
|
||||
for i, s := range str {
|
||||
switch s {
|
||||
case ' ':
|
||||
indent++
|
||||
case '\t':
|
||||
indent += 4
|
||||
default:
|
||||
return indent, str[i:]
|
||||
}
|
||||
}
|
||||
panic("Invalid indent : " + str)
|
||||
return -1, ""
|
||||
}
|
||||
|
||||
func (y *yamlReader) asMapKeyValue(str string) (key interface{}, val interface{}, err error) {
|
||||
tokens := splitToken(str)
|
||||
key = tokens[0]
|
||||
if len(tokens) == 1 {
|
||||
return key, nil, nil
|
||||
}
|
||||
if tokens[1] != ":" {
|
||||
return "", nil, y.Error("Unexpect "+str, nil)
|
||||
}
|
||||
|
||||
if len(tokens) == 2 {
|
||||
return key, MAP_KEY_ONLY, nil
|
||||
}
|
||||
if len(tokens) == 3 {
|
||||
return key, tokens[2], nil
|
||||
}
|
||||
switch tokens[2] {
|
||||
case "[":
|
||||
list := []interface{}{}
|
||||
for i := 3; i < len(tokens)-1; i++ {
|
||||
list = append(list, tokens[i])
|
||||
}
|
||||
return key, list, nil
|
||||
case "{":
|
||||
_map := map[string]interface{}{}
|
||||
for i := 3; i < len(tokens)-1; i += 4 {
|
||||
//log.Println(">>>", i, tokens[i])
|
||||
if i > len(tokens)-2 {
|
||||
return "", nil, y.Error("Unexpect "+str, nil)
|
||||
}
|
||||
if tokens[i+1] != ":" {
|
||||
return "", nil, y.Error("Unexpect "+str, nil)
|
||||
}
|
||||
_map[tokens[i].(string)] = tokens[i+2]
|
||||
if (i + 3) < (len(tokens) - 1) {
|
||||
if tokens[i+3] != "," {
|
||||
return "", "", y.Error("Unexpect "+str, nil)
|
||||
}
|
||||
} else {
|
||||
break
|
||||
}
|
||||
}
|
||||
return key, _map, nil
|
||||
}
|
||||
//log.Println(str, tokens)
|
||||
return "", nil, y.Error("Unexpect "+str, nil)
|
||||
}
|
||||
|
||||
func splitToken(str string) (tokens []interface{}) {
|
||||
str = strings.Trim(str, "\r\t\n ")
|
||||
if str == "" {
|
||||
panic("Impossbile")
|
||||
return
|
||||
}
|
||||
|
||||
tokens = []interface{}{}
|
||||
lastPos := 0
|
||||
for i := 0; i < len(str); i++ {
|
||||
switch str[i] {
|
||||
case ':':
|
||||
fallthrough
|
||||
case '{':
|
||||
fallthrough
|
||||
case '[':
|
||||
fallthrough
|
||||
case '}':
|
||||
fallthrough
|
||||
case ']':
|
||||
fallthrough
|
||||
case ',':
|
||||
if i > lastPos {
|
||||
tokens = append(tokens, str[lastPos:i])
|
||||
}
|
||||
tokens = append(tokens, str[i:i+1])
|
||||
lastPos = i + 1
|
||||
case ' ':
|
||||
if i > lastPos {
|
||||
tokens = append(tokens, str[lastPos:i])
|
||||
}
|
||||
lastPos = i + 1
|
||||
case '\'':
|
||||
//log.Println("Scan End of String")
|
||||
i++
|
||||
start := i
|
||||
for ; i < len(str); i++ {
|
||||
if str[i] == '\'' {
|
||||
//log.Println("Found End of String", start, i)
|
||||
break
|
||||
}
|
||||
}
|
||||
tokens = append(tokens, str[start:i])
|
||||
lastPos = i + 1
|
||||
case '"':
|
||||
i++
|
||||
start := i
|
||||
for ; i < len(str); i++ {
|
||||
if str[i] == '"' {
|
||||
break
|
||||
}
|
||||
}
|
||||
tokens = append(tokens, str[start:i])
|
||||
lastPos = i + 1
|
||||
}
|
||||
}
|
||||
////log.Println("last", lastPos)
|
||||
if lastPos < len(str) {
|
||||
tokens = append(tokens, str[lastPos:])
|
||||
}
|
||||
|
||||
if len(tokens) == 1 {
|
||||
tokens[0] = string2Val(tokens[0].(string))
|
||||
return
|
||||
}
|
||||
|
||||
if tokens[1] == ":" {
|
||||
if len(tokens) == 2 {
|
||||
return
|
||||
}
|
||||
if tokens[2] == "{" || tokens[2] == "[" {
|
||||
return
|
||||
}
|
||||
str = strings.Trim(strings.SplitN(str, ":", 2)[1], "\t ")
|
||||
if len(str) > 2 {
|
||||
if str[0] == '\'' && str[len(str)-1] == '\'' {
|
||||
str = str[1 : len(str)-1]
|
||||
} else if str[0] == '"' && str[len(str)-1] == '"' {
|
||||
str = str[1 : len(str)-1]
|
||||
}
|
||||
}
|
||||
val := string2Val(str)
|
||||
tokens = []interface{}{tokens[0], tokens[1], val}
|
||||
return
|
||||
}
|
||||
|
||||
if len(str) > 2 {
|
||||
if str[0] == '\'' && str[len(str)-1] == '\'' {
|
||||
str = str[1 : len(str)-1]
|
||||
} else if str[0] == '"' && str[len(str)-1] == '"' {
|
||||
str = str[1 : len(str)-1]
|
||||
}
|
||||
}
|
||||
val := string2Val(str)
|
||||
tokens = []interface{}{val}
|
||||
return
|
||||
}
|
||||
|
||||
func (y *yamlReader) Error(msg string, err error) error {
|
||||
if err != nil {
|
||||
return errors.New(fmt.Sprintf("line %d : %s : %v", y.lineNum, msg, err.Error()))
|
||||
}
|
||||
return errors.New(fmt.Sprintf("line %d >> %s", y.lineNum, msg))
|
||||
}
|
||||
29
vendor/github.com/beego/goyaml2/types.go
generated
vendored
29
vendor/github.com/beego/goyaml2/types.go
generated
vendored
@@ -1,29 +0,0 @@
|
||||
package goyaml2
|
||||
|
||||
const (
|
||||
N_Map = iota
|
||||
N_List
|
||||
N_String
|
||||
)
|
||||
|
||||
type Node interface {
|
||||
Type() int
|
||||
}
|
||||
|
||||
type MapNode map[string]interface{}
|
||||
|
||||
type ListNode []interface{}
|
||||
|
||||
type StringNode string
|
||||
|
||||
func (m *MapNode) Type() int {
|
||||
return N_Map
|
||||
}
|
||||
|
||||
func (l *ListNode) Type() int {
|
||||
return N_List
|
||||
}
|
||||
|
||||
func (s *StringNode) Type() int {
|
||||
return N_String
|
||||
}
|
||||
9
vendor/github.com/beego/goyaml2/writer.go
generated
vendored
9
vendor/github.com/beego/goyaml2/writer.go
generated
vendored
@@ -1,9 +0,0 @@
|
||||
package goyaml2
|
||||
|
||||
import (
|
||||
"io"
|
||||
)
|
||||
|
||||
func Write(w io.Writer, v interface{}) error {
|
||||
return nil
|
||||
}
|
||||
28
vendor/github.com/beego/x2j/LICENSE
generated
vendored
28
vendor/github.com/beego/x2j/LICENSE
generated
vendored
@@ -1,28 +0,0 @@
|
||||
Copyright (c) 2012-2013 Charles Banning <clbanning@gmail.com>.
|
||||
All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
modification, are permitted provided that the following conditions are
|
||||
met:
|
||||
|
||||
* Redistributions of source code must retain the above copyright
|
||||
notice, this list of conditions and the following disclaimer.
|
||||
* Redistributions in binary form must reproduce the above
|
||||
copyright notice, this list of conditions and the following disclaimer
|
||||
in the documentation and/or other materials provided with the
|
||||
distribution.
|
||||
* Neither the name of Google Inc. nor the names of its
|
||||
contributors may be used to endorse or promote products derived from
|
||||
this software without specific prior written permission.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
157
vendor/github.com/beego/x2j/README
generated
vendored
157
vendor/github.com/beego/x2j/README
generated
vendored
@@ -1,157 +0,0 @@
|
||||
x2j.go - Unmarshal dynamic / arbitrary XML docs and extract values (using wildcards, if necessary).
|
||||
|
||||
ANNOUNCEMENTS
|
||||
|
||||
20 December 2013:
|
||||
|
||||
Non-UTF8 character sets supported via the X2jCharsetReader variable.
|
||||
|
||||
12 December 2013:
|
||||
|
||||
For symmetry, the package j2x has functions that marshal JSON strings and
|
||||
map[string]interface{} values to XML encoded strings: http://godoc.org/github.com/clbanning/j2x.
|
||||
|
||||
Also, ToTree(), ToMap(), ToJson(), ToJsonIndent(), ReaderValuesFromTagPath() and ReaderValuesForTag() use io.Reader instead of string or []byte.
|
||||
|
||||
If you want to process a stream of XML messages check out XmlMsgsFromReader().
|
||||
|
||||
MOTIVATION
|
||||
|
||||
I make extensive use of JSON for messaging and typically unmarshal the messages into
|
||||
map[string]interface{} variables. This is easily done using json.Unmarshal from the
|
||||
standard Go libraries. Unfortunately, many legacy solutions use structured
|
||||
XML messages; in those environments the applications would have to be refitted to
|
||||
interoperate with my components.
|
||||
|
||||
The better solution is to just provide an alternative HTTP handler that receives
|
||||
XML doc messages and parses it into a map[string]interface{} variable and then reuse
|
||||
all the JSON-based code. The Go xml.Unmarshal() function does not provide the same
|
||||
option of unmarshaling XML messages into map[string]interface{} variables. So I wrote
|
||||
a couple of small functions to fill this gap.
|
||||
|
||||
Of course, once the XML doc was unmarshal'd into a map[string]interface{} variable it
|
||||
was just a matter of calling json.Marshal() to provide it as a JSON string. Hence 'x2j'
|
||||
rather than just 'x2m'.
|
||||
|
||||
USAGE
|
||||
|
||||
The package is fairly well self-documented. (http://godoc.org/github.com/clbanning/x2j)
|
||||
The one really useful function is:
|
||||
|
||||
- Unmarshal(doc []byte, v interface{}) error
|
||||
where v is a pointer to a variable of type 'map[string]interface{}', 'string', or
|
||||
any other type supported by xml.Unmarshal().
|
||||
|
||||
To retrieve a value for specific tag use:
|
||||
|
||||
- DocValue(doc, path string, attrs ...string) (interface{},error)
|
||||
- MapValue(m map[string]interface{}, path string, attr map[string]interface{}, recast ...bool) (interface{}, error)
|
||||
|
||||
The 'path' argument is a period-separated tag hierarchy - also known as dot-notation.
|
||||
It is the program's responsibility to cast the returned value to the proper type; possible
|
||||
types are the normal JSON unmarshaling types: string, float64, bool, []interface, map[string]interface{}.
|
||||
|
||||
To retrieve all values associated with a tag occurring anywhere in the XML document use:
|
||||
|
||||
- ValuesForTag(doc, tag string) ([]interface{}, error)
|
||||
- ValuesForKey(m map[string]interface{}, key string) []interface{}
|
||||
|
||||
Demos: http://play.golang.org/p/m8zP-cpk0O
|
||||
http://play.golang.org/p/cIteTS1iSg
|
||||
http://play.golang.org/p/vd8pMiI21b
|
||||
|
||||
Returned values should be one of map[string]interface, []interface{}, or string.
|
||||
|
||||
All the values assocated with a tag-path that may include one or more wildcard characters -
|
||||
'*' - can also be retrieved using:
|
||||
|
||||
- ValuesFromTagPath(doc, path string, getAttrs ...bool) ([]interface{}, error)
|
||||
- ValuesFromKeyPath(map[string]interface{}, path string, getAttrs ...bool) []interface{}
|
||||
|
||||
Demos: http://play.golang.org/p/kUQnZ8VuhS
|
||||
http://play.golang.org/p/l1aMHYtz7G
|
||||
|
||||
NOTE: care should be taken when using "*" at the end of a path - i.e., "books.book.*". See
|
||||
the x2jpath_test.go case on how the wildcard returns all key values and collapses list values;
|
||||
the same message structure can load a []interface{} or a map[string]interface{} (or an interface{})
|
||||
value for a tag.
|
||||
|
||||
See the test cases in "x2jpath_test.go" and programs in "example" subdirectory for more.
|
||||
|
||||
XML PARSING CONVENTIONS
|
||||
|
||||
- Attributes are parsed to map[string]interface{} values by prefixing a hyphen, '-',
|
||||
to the attribute label.
|
||||
- If the element is a simple element and has attributes, the element value
|
||||
is given the key '#text' for its map[string]interface{} representation. (See
|
||||
the 'atomFeedString.xml' test data, below.)
|
||||
|
||||
BULK PROCESSING OF MESSAGE FILES
|
||||
|
||||
Sometime messages may be logged into files for transmission via FTP (e.g.) and subsequent
|
||||
processing. You can use the bulk XML message processor to convert files of XML messages into
|
||||
map[string]interface{} values with custom processing and error handler functions. See
|
||||
the notes and test code for:
|
||||
|
||||
- XmlMsgsFromFile(fname string, phandler func(map[string]interface{}) bool, ehandler func(error) bool,recast ...bool) error
|
||||
|
||||
IMPLEMENTATION NOTES
|
||||
|
||||
Nothing fancy here, just brute force.
|
||||
|
||||
- Use xml.Decoder to parse the XML doc and build a tree.
|
||||
- Walk the tree and load values into a map[string]interface{} variable, 'm', as
|
||||
appropriate.
|
||||
- Use json.Marshaler to convert 'm' to JSON.
|
||||
|
||||
As for testing:
|
||||
|
||||
- Copy an XML doc into 'x2j_test.xml'.
|
||||
- Run "go test" and you'll get a full dump.
|
||||
("pathTestString.xml" and "atomFeedString.xml" are test data from "read_test.go"
|
||||
in the encoding/xml directory of the standard package library.)
|
||||
|
||||
USES
|
||||
|
||||
- putting a XML API on our message hub middleware (http://jsonhub.net)
|
||||
- loading XML data into NoSQL database, such as, mongoDB
|
||||
|
||||
PERFORMANCE IMPROVEMENTS WITH GO 1.1 and 1.2
|
||||
|
||||
Upgrading to Go 1.1 environment results in performance improvements for XML and JSON
|
||||
unmarshalling, in general. The x2j package gets an average performance boost of 40%.
|
||||
|
||||
----- Go 1.0.2 ----- ----------- Go 1.1 -----------
|
||||
iterations ns/op iterations ns/op % improved
|
||||
Benchmark_UseXml-4 100000 18776 200000 10377 45%
|
||||
Benchmark_UseX2j-4 50000 55323 50000 33958 39%
|
||||
Benchmark_UseJson-4 1000000 2257 1000000 1484 34%
|
||||
Benchmark_UseJsonToMap-4 1000000 2531 1000000 1566 38%
|
||||
BenchmarkBig_UseXml-4 100000 28918 100000 15876 45%
|
||||
BenchmarkBig_UseX2j-4 20000 86338 50000 52661 39%
|
||||
BenchmarkBig_UseJson-4 500000 4448 1000000 2664 40%
|
||||
BenchmarkBig_UseJsonToMap-4 200000 9076 500000 5753 37%
|
||||
BenchmarkBig3_UseXml-4 50000 42224 100000 24686 42%
|
||||
BenchmarkBig3_UseX2j-4 10000 147407 20000 84332 43%
|
||||
BenchmarkBig3_UseJson-4 500000 5921 500000 3930 34%
|
||||
BenchmarkBig3_UseJsonToMap-4 200000 13037 200000 8670 33%
|
||||
|
||||
The x2j package gets an additional 15-20% performance boost going to Go 1.2.
|
||||
|
||||
------ Go 1.1 ------ ----------- Go 1.2 -----------
|
||||
iterations ns/op iterations ns/op % improved
|
||||
Benchmark_UseXml-4 200000 10377 200000 11031 -6%
|
||||
Benchmark_UseX2j-4 50000 33958 100000 29188 14%
|
||||
Benchmark_UseJson-4 1000000 1484 1000000 1347 9%
|
||||
Benchmark_UseJsonToMap-4 1000000 1566 1000000 1434 8%
|
||||
BenchmarkBig_UseXml-4 100000 15876 100000 16585 -4%
|
||||
BenchmarkBig_UseX2j-4 50000 52661 50000 43452 17%
|
||||
BenchmarkBig_UseJson-4 1000000 2664 1000000 2523 5%
|
||||
BenchmarkBig_UseJsonToMap-4 500000 5753 500000 4992 13%
|
||||
BenchmarkBig3_UseXml-4 100000 24686 100000 24348 1%
|
||||
BenchmarkBig3_UseX2j-4 20000 84332 50000 66736 21%
|
||||
BenchmarkBig3_UseJson-4 500000 3930 500000 3733 5%
|
||||
BenchmarkBig3_UseJsonToMap-4 200000 8670 200000 7810 10%
|
||||
|
||||
|
||||
|
||||
54
vendor/github.com/beego/x2j/atomFeedString.xml
generated
vendored
54
vendor/github.com/beego/x2j/atomFeedString.xml
generated
vendored
@@ -1,54 +0,0 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<feed xmlns="http://www.w3.org/2005/Atom" xml:lang="en-us" updated="2009-10-04T01:35:58+00:00"><title>Code Review - My issues</title><link href="http://codereview.appspot.com/" rel="alternate"></link><link href="http://codereview.appspot.com/rss/mine/rsc" rel="self"></link><id>http://codereview.appspot.com/</id><author><name>rietveld<></name></author><entry><title>rietveld: an attempt at pubsubhubbub
|
||||
</title><link href="http://codereview.appspot.com/126085" rel="alternate"></link><updated>2009-10-04T01:35:58+00:00</updated><author><name>email-address-removed</name></author><id>urn:md5:134d9179c41f806be79b3a5f7877d19a</id><summary type="html">
|
||||
An attempt at adding pubsubhubbub support to Rietveld.
|
||||
http://code.google.com/p/pubsubhubbub
|
||||
http://code.google.com/p/rietveld/issues/detail?id=155
|
||||
|
||||
The server side of the protocol is trivial:
|
||||
1. add a &lt;link rel=&quot;hub&quot; href=&quot;hub-server&quot;&gt; tag to all
|
||||
feeds that will be pubsubhubbubbed.
|
||||
2. every time one of those feeds changes, tell the hub
|
||||
with a simple POST request.
|
||||
|
||||
I have tested this by adding debug prints to a local hub
|
||||
server and checking that the server got the right publish
|
||||
requests.
|
||||
|
||||
I can&#39;t quite get the server to work, but I think the bug
|
||||
is not in my code. I think that the server expects to be
|
||||
able to grab the feed and see the feed&#39;s actual URL in
|
||||
the link rel=&quot;self&quot;, but the default value for that drops
|
||||
the :port from the URL, and I cannot for the life of me
|
||||
figure out how to get the Atom generator deep inside
|
||||
django not to do that, or even where it is doing that,
|
||||
or even what code is running to generate the Atom feed.
|
||||
(I thought I knew but I added some assert False statements
|
||||
and it kept running!)
|
||||
|
||||
Ignoring that particular problem, I would appreciate
|
||||
feedback on the right way to get the two values at
|
||||
the top of feeds.py marked NOTE(rsc).
|
||||
|
||||
|
||||
</summary></entry><entry><title>rietveld: correct tab handling
|
||||
</title><link href="http://codereview.appspot.com/124106" rel="alternate"></link><updated>2009-10-03T23:02:17+00:00</updated><author><name>email-address-removed</name></author><id>urn:md5:0a2a4f19bb815101f0ba2904aed7c35a</id><summary type="html">
|
||||
This fixes the buggy tab rendering that can be seen at
|
||||
http://codereview.appspot.com/116075/diff/1/2
|
||||
|
||||
The fundamental problem was that the tab code was
|
||||
not being told what column the text began in, so it
|
||||
didn&#39;t know where to put the tab stops. Another problem
|
||||
was that some of the code assumed that string byte
|
||||
offsets were the same as column offsets, which is only
|
||||
true if there are no tabs.
|
||||
|
||||
In the process of fixing this, I cleaned up the arguments
|
||||
to Fold and ExpandTabs and renamed them Break and
|
||||
_ExpandTabs so that I could be sure that I found all the
|
||||
call sites. I also wanted to verify that ExpandTabs was
|
||||
not being used from outside intra_region_diff.py.
|
||||
|
||||
|
||||
</summary></entry></feed> `
|
||||
|
||||
20
vendor/github.com/beego/x2j/pathTestString.xml
generated
vendored
20
vendor/github.com/beego/x2j/pathTestString.xml
generated
vendored
@@ -1,20 +0,0 @@
|
||||
<Result>
|
||||
<Before>1</Before>
|
||||
<Items>
|
||||
<Item1>
|
||||
<Value>A</Value>
|
||||
</Item1>
|
||||
<Item2>
|
||||
<Value>B</Value>
|
||||
</Item2>
|
||||
<Item1>
|
||||
<Value>C</Value>
|
||||
<Value>D</Value>
|
||||
</Item1>
|
||||
<_>
|
||||
<Value>E</Value>
|
||||
</_>
|
||||
</Items>
|
||||
<After>2</After>
|
||||
</Result>
|
||||
|
||||
105
vendor/github.com/beego/x2j/reader2j.go
generated
vendored
105
vendor/github.com/beego/x2j/reader2j.go
generated
vendored
@@ -1,105 +0,0 @@
|
||||
// io.Reader --> map[string]interface{} or JSON string
|
||||
// nothing magic - just implements generic Go case
|
||||
|
||||
package x2j
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"encoding/xml"
|
||||
"io"
|
||||
)
|
||||
|
||||
// ToTree() - parse a XML io.Reader to a tree of Nodes
|
||||
func ToTree(rdr io.Reader) (*Node, error) {
|
||||
p := xml.NewDecoder(rdr)
|
||||
p.CharsetReader = X2jCharsetReader
|
||||
n, perr := xmlToTree("", nil, p)
|
||||
if perr != nil {
|
||||
return nil, perr
|
||||
}
|
||||
|
||||
return n, nil
|
||||
}
|
||||
|
||||
// ToMap() - parse a XML io.Reader to a map[string]interface{}
|
||||
func ToMap(rdr io.Reader, recast ...bool) (map[string]interface{}, error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
n, err := ToTree(rdr)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
m := make(map[string]interface{})
|
||||
m[n.key] = n.treeToMap(r)
|
||||
|
||||
return m, nil
|
||||
}
|
||||
|
||||
// ToJson() - parse a XML io.Reader to a JSON string
|
||||
func ToJson(rdr io.Reader, recast ...bool) (string, error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
m, merr := ToMap(rdr, r)
|
||||
if m == nil || merr != nil {
|
||||
return "", merr
|
||||
}
|
||||
|
||||
b, berr := json.Marshal(m)
|
||||
if berr != nil {
|
||||
return "", berr
|
||||
}
|
||||
|
||||
return string(b), nil
|
||||
}
|
||||
|
||||
// ToJsonIndent - the pretty form of ReaderToJson
|
||||
func ToJsonIndent(rdr io.Reader, recast ...bool) (string, error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
m, merr := ToMap(rdr, r)
|
||||
if m == nil || merr != nil {
|
||||
return "", merr
|
||||
}
|
||||
|
||||
b, berr := json.MarshalIndent(m, "", " ")
|
||||
if berr != nil {
|
||||
return "", berr
|
||||
}
|
||||
|
||||
// NOTE: don't have to worry about safe JSON marshaling with json.Marshal, since '<' and '>" are reservedin XML.
|
||||
return string(b), nil
|
||||
}
|
||||
|
||||
|
||||
// ReaderValuesFromTagPath - io.Reader version of ValuesFromTagPath()
|
||||
func ReaderValuesFromTagPath(rdr io.Reader, path string, getAttrs ...bool) ([]interface{}, error) {
|
||||
var a bool
|
||||
if len(getAttrs) == 1 {
|
||||
a = getAttrs[0]
|
||||
}
|
||||
m, err := ToMap(rdr)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return ValuesFromKeyPath(m, path, a), nil
|
||||
}
|
||||
|
||||
// ReaderValuesForTag - io.Reader version of ValuesForTag()
|
||||
func ReaderValuesForTag(rdr io.Reader, tag string) ([]interface{}, error) {
|
||||
m, err := ToMap(rdr)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return ValuesForKey(m, tag), nil
|
||||
}
|
||||
|
||||
|
||||
29
vendor/github.com/beego/x2j/songTextString.xml
generated
vendored
29
vendor/github.com/beego/x2j/songTextString.xml
generated
vendored
@@ -1,29 +0,0 @@
|
||||
<msg mtype="alert" mpriority="1">
|
||||
<text>help me!</text>
|
||||
<song title="A Long Time" author="Mayer Hawthorne">
|
||||
<verses>
|
||||
<verse name="verse 1" no="1">
|
||||
<line no="1">Henry was a renegade</line>
|
||||
<line no="2">Didn't like to play it safe</line>
|
||||
<line no="3">One component at a time</line>
|
||||
<line no="4">There's got to be a better way</line>
|
||||
<line no="5">Oh, people came from miles around</line>
|
||||
<line no="6">Searching for a steady job</line>
|
||||
<line no="7">Welcome to the Motor Town</line>
|
||||
<line no="8">Booming like an atom bomb</line>
|
||||
</verse>
|
||||
<verse name="verse 2" no="2">
|
||||
<line no="1">Oh, Henry was the end of the story</line>
|
||||
<line no="2">Then everything went wrong</line>
|
||||
<line no="3">And we'll return it to its former glory</line>
|
||||
<line no="4">But it just takes so long</line>
|
||||
</verse>
|
||||
</verses>
|
||||
<chorus>
|
||||
<line no="1">It's going to take a long time</line>
|
||||
<line no="2">It's going to take it, but we'll make it one day</line>
|
||||
<line no="3">It's going to take a long time</line>
|
||||
<line no="4">It's going to take it, but we'll make it one day</line>
|
||||
</chorus>
|
||||
</song>
|
||||
</msg>
|
||||
656
vendor/github.com/beego/x2j/x2j.go
generated
vendored
656
vendor/github.com/beego/x2j/x2j.go
generated
vendored
@@ -1,656 +0,0 @@
|
||||
// Unmarshal dynamic / arbitrary XML docs and extract values (using wildcards, if necessary).
|
||||
// Copyright 2012-2013 Charles Banning. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file
|
||||
/*
|
||||
Unmarshal dynamic / arbitrary XML docs and extract values (using wildcards, if necessary).
|
||||
|
||||
One useful function is:
|
||||
|
||||
- Unmarshal(doc []byte, v interface{}) error
|
||||
where v is a pointer to a variable of type 'map[string]interface{}', 'string', or
|
||||
any other type supported by xml.Unmarshal().
|
||||
|
||||
To retrieve a value for specific tag use:
|
||||
|
||||
- DocValue(doc, path string, attrs ...string) (interface{},error)
|
||||
- MapValue(m map[string]interface{}, path string, attr map[string]interface{}, recast ...bool) (interface{}, error)
|
||||
|
||||
The 'path' argument is a period-separated tag hierarchy - also known as dot-notation.
|
||||
It is the program's responsibility to cast the returned value to the proper type; possible
|
||||
types are the normal JSON unmarshaling types: string, float64, bool, []interface, map[string]interface{}.
|
||||
|
||||
To retrieve all values associated with a tag occurring anywhere in the XML document use:
|
||||
|
||||
- ValuesForTag(doc, tag string) ([]interface{}, error)
|
||||
- ValuesForKey(m map[string]interface{}, key string) []interface{}
|
||||
|
||||
Demos: http://play.golang.org/p/m8zP-cpk0O
|
||||
http://play.golang.org/p/cIteTS1iSg
|
||||
http://play.golang.org/p/vd8pMiI21b
|
||||
|
||||
Returned values should be one of map[string]interface, []interface{}, or string.
|
||||
|
||||
All the values assocated with a tag-path that may include one or more wildcard characters -
|
||||
'*' - can also be retrieved using:
|
||||
|
||||
- ValuesFromTagPath(doc, path string, getAttrs ...bool) ([]interface{}, error)
|
||||
- ValuesFromKeyPath(map[string]interface{}, path string, getAttrs ...bool) []interface{}
|
||||
|
||||
Demos: http://play.golang.org/p/kUQnZ8VuhS
|
||||
http://play.golang.org/p/l1aMHYtz7G
|
||||
|
||||
NOTE: care should be taken when using "*" at the end of a path - i.e., "books.book.*". See
|
||||
the x2jpath_test.go case on how the wildcard returns all key values and collapses list values;
|
||||
the same message structure can load a []interface{} or a map[string]interface{} (or an interface{})
|
||||
value for a tag.
|
||||
|
||||
See the test cases in "x2jpath_test.go" and programs in "example" subdirectory for more.
|
||||
|
||||
XML PARSING CONVENTIONS
|
||||
|
||||
- Attributes are parsed to map[string]interface{} values by prefixing a hyphen, '-',
|
||||
to the attribute label.
|
||||
- If the element is a simple element and has attributes, the element value
|
||||
is given the key '#text' for its map[string]interface{} representation. (See
|
||||
the 'atomFeedString.xml' test data, below.)
|
||||
|
||||
io.Reader HANDLING
|
||||
|
||||
ToTree(), ToMap(), ToJson(), and ToJsonIndent() provide parsing of messages from an io.Reader.
|
||||
If you want to handle a message stream, look at XmlMsgsFromReader().
|
||||
|
||||
NON-UTF8 CHARACTER SETS
|
||||
|
||||
Use the X2jCharsetReader variable to assign io.Reader for alternative character sets.
|
||||
*/
|
||||
package x2j
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"encoding/json"
|
||||
"encoding/xml"
|
||||
"errors"
|
||||
"fmt"
|
||||
"io"
|
||||
"regexp"
|
||||
"strconv"
|
||||
"strings"
|
||||
)
|
||||
|
||||
// If X2jCharsetReader != nil, it will be used to decode the doc or stream if required
|
||||
// import charset "code.google.com/p/go-charset/charset"
|
||||
// ...
|
||||
// x2j.X2jCharsetReader = charset.NewReader
|
||||
// s, err := x2j.DocToJson(doc)
|
||||
var X2jCharsetReader func(charset string, input io.Reader)(io.Reader, error)
|
||||
|
||||
type Node struct {
|
||||
dup bool // is member of a list
|
||||
attr bool // is an attribute
|
||||
key string // XML tag
|
||||
val string // element value
|
||||
nodes []*Node
|
||||
}
|
||||
|
||||
// DocToJson - return an XML doc as a JSON string.
|
||||
// If the optional argument 'recast' is 'true', then values will be converted to boolean or float64 if possible.
|
||||
func DocToJson(doc string, recast ...bool) (string, error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
m, merr := DocToMap(doc, r)
|
||||
if m == nil || merr != nil {
|
||||
return "", merr
|
||||
}
|
||||
|
||||
b, berr := json.Marshal(m)
|
||||
if berr != nil {
|
||||
return "", berr
|
||||
}
|
||||
|
||||
// NOTE: don't have to worry about safe JSON marshaling with json.Marshal, since '<' and '>" are reservedin XML.
|
||||
return string(b), nil
|
||||
}
|
||||
|
||||
// DocToJsonIndent - return an XML doc as a prettified JSON string.
|
||||
// If the optional argument 'recast' is 'true', then values will be converted to boolean or float64 if possible.
|
||||
// Note: recasting is only applied to element values, not attribute values.
|
||||
func DocToJsonIndent(doc string, recast ...bool) (string, error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
m, merr := DocToMap(doc, r)
|
||||
if m == nil || merr != nil {
|
||||
return "", merr
|
||||
}
|
||||
|
||||
b, berr := json.MarshalIndent(m, "", " ")
|
||||
if berr != nil {
|
||||
return "", berr
|
||||
}
|
||||
|
||||
// NOTE: don't have to worry about safe JSON marshaling with json.Marshal, since '<' and '>" are reservedin XML.
|
||||
return string(b), nil
|
||||
}
|
||||
|
||||
// DocToMap - convert an XML doc into a map[string]interface{}.
|
||||
// (This is analogous to unmarshalling a JSON string to map[string]interface{} using json.Unmarshal().)
|
||||
// If the optional argument 'recast' is 'true', then values will be converted to boolean or float64 if possible.
|
||||
// Note: recasting is only applied to element values, not attribute values.
|
||||
func DocToMap(doc string, recast ...bool) (map[string]interface{}, error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
n, err := DocToTree(doc)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
m := make(map[string]interface{})
|
||||
m[n.key] = n.treeToMap(r)
|
||||
|
||||
return m, nil
|
||||
}
|
||||
|
||||
// DocToTree - convert an XML doc into a tree of nodes.
|
||||
func DocToTree(doc string) (*Node, error) {
|
||||
// xml.Decoder doesn't properly handle whitespace in some doc
|
||||
// see songTextString.xml test case ...
|
||||
reg, _ := regexp.Compile("[ \t\n\r]*<")
|
||||
doc = reg.ReplaceAllString(doc, "<")
|
||||
|
||||
b := bytes.NewBufferString(doc)
|
||||
p := xml.NewDecoder(b)
|
||||
p.CharsetReader = X2jCharsetReader
|
||||
n, berr := xmlToTree("", nil, p)
|
||||
if berr != nil {
|
||||
return nil, berr
|
||||
}
|
||||
|
||||
return n, nil
|
||||
}
|
||||
|
||||
// (*Node)WriteTree - convert a tree of nodes into a printable string.
|
||||
// 'padding' is the starting indentation; typically: n.WriteTree().
|
||||
func (n *Node) WriteTree(padding ...int) string {
|
||||
var indent int
|
||||
if len(padding) == 1 {
|
||||
indent = padding[0]
|
||||
}
|
||||
|
||||
var s string
|
||||
if n.val != "" {
|
||||
for i := 0; i < indent; i++ {
|
||||
s += " "
|
||||
}
|
||||
s += n.key + " : " + n.val + "\n"
|
||||
} else {
|
||||
for i := 0; i < indent; i++ {
|
||||
s += " "
|
||||
}
|
||||
s += n.key + " :" + "\n"
|
||||
for _, nn := range n.nodes {
|
||||
s += nn.WriteTree(indent + 1)
|
||||
}
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
// xmlToTree - load a 'clean' XML doc into a tree of *Node.
|
||||
func xmlToTree(skey string, a []xml.Attr, p *xml.Decoder) (*Node, error) {
|
||||
n := new(Node)
|
||||
n.nodes = make([]*Node, 0)
|
||||
|
||||
if skey != "" {
|
||||
n.key = skey
|
||||
if len(a) > 0 {
|
||||
for _, v := range a {
|
||||
na := new(Node)
|
||||
na.attr = true
|
||||
na.key = `-` + v.Name.Local
|
||||
na.val = v.Value
|
||||
n.nodes = append(n.nodes, na)
|
||||
}
|
||||
}
|
||||
}
|
||||
for {
|
||||
t, err := p.Token()
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
switch t.(type) {
|
||||
case xml.StartElement:
|
||||
tt := t.(xml.StartElement)
|
||||
// handle root
|
||||
if n.key == "" {
|
||||
n.key = tt.Name.Local
|
||||
if len(tt.Attr) > 0 {
|
||||
for _, v := range tt.Attr {
|
||||
na := new(Node)
|
||||
na.attr = true
|
||||
na.key = `-` + v.Name.Local
|
||||
na.val = v.Value
|
||||
n.nodes = append(n.nodes, na)
|
||||
}
|
||||
}
|
||||
} else {
|
||||
nn, nnerr := xmlToTree(tt.Name.Local, tt.Attr, p)
|
||||
if nnerr != nil {
|
||||
return nil, nnerr
|
||||
}
|
||||
n.nodes = append(n.nodes, nn)
|
||||
}
|
||||
case xml.EndElement:
|
||||
// scan n.nodes for duplicate n.key values
|
||||
n.markDuplicateKeys()
|
||||
return n, nil
|
||||
case xml.CharData:
|
||||
tt := string(t.(xml.CharData))
|
||||
if len(n.nodes) > 0 {
|
||||
nn := new(Node)
|
||||
nn.key = "#text"
|
||||
nn.val = tt
|
||||
n.nodes = append(n.nodes, nn)
|
||||
} else {
|
||||
n.val = tt
|
||||
}
|
||||
default:
|
||||
// noop
|
||||
}
|
||||
}
|
||||
// Logically we can't get here, but provide an error message anyway.
|
||||
return nil, errors.New("Unknown parse error in xmlToTree() for: " + n.key)
|
||||
}
|
||||
|
||||
// (*Node)markDuplicateKeys - set node.dup flag for loading map[string]interface{}.
|
||||
func (n *Node) markDuplicateKeys() {
|
||||
l := len(n.nodes)
|
||||
for i := 0; i < l; i++ {
|
||||
if n.nodes[i].dup {
|
||||
continue
|
||||
}
|
||||
for j := i + 1; j < l; j++ {
|
||||
if n.nodes[i].key == n.nodes[j].key {
|
||||
n.nodes[i].dup = true
|
||||
n.nodes[j].dup = true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// (*Node)treeToMap - convert a tree of nodes into a map[string]interface{}.
|
||||
// (Parses to map that is structurally the same as from json.Unmarshal().)
|
||||
// Note: root is not instantiated; call with: "m[n.key] = n.treeToMap(recast)".
|
||||
func (n *Node) treeToMap(r bool) interface{} {
|
||||
if len(n.nodes) == 0 {
|
||||
return recast(n.val, r)
|
||||
}
|
||||
|
||||
m := make(map[string]interface{}, 0)
|
||||
for _, v := range n.nodes {
|
||||
// just a value
|
||||
if !v.dup && len(v.nodes) == 0 {
|
||||
m[v.key] = recast(v.val, r)
|
||||
continue
|
||||
}
|
||||
|
||||
// a list of values
|
||||
if v.dup {
|
||||
var a []interface{}
|
||||
if vv, ok := m[v.key]; ok {
|
||||
a = vv.([]interface{})
|
||||
} else {
|
||||
a = make([]interface{}, 0)
|
||||
}
|
||||
a = append(a, v.treeToMap(r))
|
||||
m[v.key] = interface{}(a)
|
||||
continue
|
||||
}
|
||||
|
||||
// it's a unique key
|
||||
m[v.key] = v.treeToMap(r)
|
||||
}
|
||||
|
||||
return interface{}(m)
|
||||
}
|
||||
|
||||
// recast - try to cast string values to bool or float64
|
||||
func recast(s string, r bool) interface{} {
|
||||
if r {
|
||||
// handle numeric strings ahead of boolean
|
||||
if f, err := strconv.ParseFloat(s, 64); err == nil {
|
||||
return interface{}(f)
|
||||
}
|
||||
// ParseBool treats "1"==true & "0"==false
|
||||
if b, err := strconv.ParseBool(s); err == nil {
|
||||
return interface{}(b)
|
||||
}
|
||||
}
|
||||
return interface{}(s)
|
||||
}
|
||||
|
||||
// WriteMap - dumps the map[string]interface{} for examination.
|
||||
// 'offset' is initial indentation count; typically: WriteMap(m).
|
||||
// NOTE: with XML all element types are 'string'.
|
||||
// But code written as generic for use with maps[string]interface{} values from json.Unmarshal().
|
||||
// Or it can handle a DocToMap(doc,true) result where values have been recast'd.
|
||||
func WriteMap(m interface{}, offset ...int) string {
|
||||
var indent int
|
||||
if len(offset) == 1 {
|
||||
indent = offset[0]
|
||||
}
|
||||
|
||||
var s string
|
||||
switch m.(type) {
|
||||
case nil:
|
||||
return "[nil] nil"
|
||||
case string:
|
||||
return "[string] " + m.(string)
|
||||
case float64:
|
||||
return "[float64] " + strconv.FormatFloat(m.(float64), 'e', 2, 64)
|
||||
case bool:
|
||||
return "[bool] " + strconv.FormatBool(m.(bool))
|
||||
case []interface{}:
|
||||
s += "[[]interface{}]"
|
||||
for i, v := range m.([]interface{}) {
|
||||
s += "\n"
|
||||
for i := 0; i < indent; i++ {
|
||||
s += " "
|
||||
}
|
||||
s += "[item: " + strconv.FormatInt(int64(i), 10) + "]"
|
||||
switch v.(type) {
|
||||
case string, float64, bool:
|
||||
s += "\n"
|
||||
default:
|
||||
// noop
|
||||
}
|
||||
for i := 0; i < indent; i++ {
|
||||
s += " "
|
||||
}
|
||||
s += WriteMap(v, indent+1)
|
||||
}
|
||||
case map[string]interface{}:
|
||||
for k, v := range m.(map[string]interface{}) {
|
||||
s += "\n"
|
||||
for i := 0; i < indent; i++ {
|
||||
s += " "
|
||||
}
|
||||
// s += "[map[string]interface{}] "+k+" :"+WriteMap(v,indent+1)
|
||||
s += k + " :" + WriteMap(v, indent+1)
|
||||
}
|
||||
default:
|
||||
// shouldn't ever be here ...
|
||||
s += fmt.Sprintf("unknown type for: %v", m)
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
// ------------------------ value extraction from XML doc --------------------------
|
||||
|
||||
// DocValue - return a value for a specific tag
|
||||
// 'doc' is a valid XML message.
|
||||
// 'path' is a hierarchy of XML tags, e.g., "doc.name".
|
||||
// 'attrs' is an OPTIONAL list of "name:value" pairs for attributes.
|
||||
// Note: 'recast' is not enabled here. Use DocToMap(), NewAttributeMap(), and MapValue() calls for that.
|
||||
func DocValue(doc, path string, attrs ...string) (interface{}, error) {
|
||||
n, err := DocToTree(doc)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
m := make(map[string]interface{})
|
||||
m[n.key] = n.treeToMap(false)
|
||||
|
||||
a, aerr := NewAttributeMap(attrs...)
|
||||
if aerr != nil {
|
||||
return nil, aerr
|
||||
}
|
||||
v, verr := MapValue(m, path, a)
|
||||
if verr != nil {
|
||||
return nil, verr
|
||||
}
|
||||
return v, nil
|
||||
}
|
||||
|
||||
// MapValue - retrieves value based on walking the map, 'm'.
|
||||
// 'm' is the map value of interest.
|
||||
// 'path' is a period-separated hierarchy of keys in the map.
|
||||
// 'attr' is a map of attribute "name:value" pairs from NewAttributeMap(). May be 'nil'.
|
||||
// If the path can't be traversed, an error is returned.
|
||||
// Note: the optional argument 'r' can be used to coerce attribute values, 'attr', if done so for 'm'.
|
||||
func MapValue(m map[string]interface{}, path string, attr map[string]interface{}, r ...bool) (interface{}, error) {
|
||||
// attribute values may have been recasted during map construction; default is 'false'.
|
||||
if len(r) == 1 && r[0] == true {
|
||||
for k, v := range attr {
|
||||
attr[k] = recast(v.(string), true)
|
||||
}
|
||||
}
|
||||
|
||||
// parse the path
|
||||
keys := strings.Split(path, ".")
|
||||
|
||||
// initialize return value to 'm' so a path of "" will work correctly
|
||||
var v interface{} = m
|
||||
var ok bool
|
||||
var okey string
|
||||
var isMap bool = true
|
||||
if keys[0] == "" && len(attr) == 0 {
|
||||
return v, nil
|
||||
}
|
||||
for _, key := range keys {
|
||||
if !isMap {
|
||||
return nil, errors.New("no keys beyond: " + okey)
|
||||
}
|
||||
if v, ok = m[key]; !ok {
|
||||
return nil, errors.New("no key in map: " + key)
|
||||
} else {
|
||||
switch v.(type) {
|
||||
case map[string]interface{}:
|
||||
m = v.(map[string]interface{})
|
||||
isMap = true
|
||||
default:
|
||||
isMap = false
|
||||
}
|
||||
}
|
||||
// save 'key' for error reporting
|
||||
okey = key
|
||||
}
|
||||
|
||||
// match attributes; value is "#text" or nil
|
||||
if attr == nil {
|
||||
return v, nil
|
||||
}
|
||||
return hasAttributes(v, attr)
|
||||
}
|
||||
|
||||
// hasAttributes() - interface{} equality works for string, float64, bool
|
||||
func hasAttributes(v interface{}, a map[string]interface{}) (interface{}, error) {
|
||||
switch v.(type) {
|
||||
case []interface{}:
|
||||
// run through all entries looking one with matching attributes
|
||||
for _, vv := range v.([]interface{}) {
|
||||
if vvv, vvverr := hasAttributes(vv, a); vvverr == nil {
|
||||
return vvv, nil
|
||||
}
|
||||
}
|
||||
return nil, errors.New("no list member with matching attributes")
|
||||
case map[string]interface{}:
|
||||
// do all attribute name:value pairs match?
|
||||
nv := v.(map[string]interface{})
|
||||
for key, val := range a {
|
||||
if vv, ok := nv[key]; !ok {
|
||||
return nil, errors.New("no attribute with name: " + key[1:])
|
||||
} else if val != vv {
|
||||
return nil, errors.New("no attribute key:value pair: " + fmt.Sprintf("%s:%v", key[1:], val))
|
||||
}
|
||||
}
|
||||
// they all match; so return value associated with "#text" key.
|
||||
if vv, ok := nv["#text"]; ok {
|
||||
return vv, nil
|
||||
} else {
|
||||
// this happens when another element is value of tag rather than just a string value
|
||||
return nv, nil
|
||||
}
|
||||
}
|
||||
return nil, errors.New("no match for attributes")
|
||||
}
|
||||
|
||||
// NewAttributeMap() - generate map of attributes=value entries as map["-"+string]string.
|
||||
// 'kv' arguments are "name:value" pairs that appear as attributes, name="value".
|
||||
// If len(kv) == 0, the return is (nil, nil).
|
||||
func NewAttributeMap(kv ...string) (map[string]interface{}, error) {
|
||||
if len(kv) == 0 {
|
||||
return nil, nil
|
||||
}
|
||||
m := make(map[string]interface{}, 0)
|
||||
for _, v := range kv {
|
||||
vv := strings.Split(v, ":")
|
||||
if len(vv) != 2 {
|
||||
return nil, errors.New("attribute not \"name:value\" pair: " + v)
|
||||
}
|
||||
// attributes are stored as keys prepended with hyphen
|
||||
m["-"+vv[0]] = interface{}(vv[1])
|
||||
}
|
||||
return m, nil
|
||||
}
|
||||
|
||||
//------------------------- get values for key ----------------------------
|
||||
|
||||
// ValuesForTag - return all values in doc associated with 'tag'.
|
||||
// Returns nil if the 'tag' does not occur in the doc.
|
||||
// If there is an error encounted while parsing doc, that is returned.
|
||||
// If you want values 'recast' use DocToMap() and ValuesForKey().
|
||||
func ValuesForTag(doc, tag string) ([]interface{}, error) {
|
||||
m, err := DocToMap(doc)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return ValuesForKey(m, tag), nil
|
||||
}
|
||||
|
||||
// ValuesForKey - return all values in map associated with 'key'
|
||||
// Returns nil if the 'key' does not occur in the map
|
||||
func ValuesForKey(m map[string]interface{}, key string) []interface{} {
|
||||
ret := make([]interface{}, 0)
|
||||
|
||||
hasKey(m, key, &ret)
|
||||
if len(ret) > 0 {
|
||||
return ret
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// hasKey - if the map 'key' exists append it to array
|
||||
// if it doesn't do nothing except scan array and map values
|
||||
func hasKey(iv interface{}, key string, ret *[]interface{}) {
|
||||
switch iv.(type) {
|
||||
case map[string]interface{}:
|
||||
vv := iv.(map[string]interface{})
|
||||
if v, ok := vv[key]; ok {
|
||||
*ret = append(*ret, v)
|
||||
}
|
||||
for _, v := range iv.(map[string]interface{}) {
|
||||
hasKey(v, key, ret)
|
||||
}
|
||||
case []interface{}:
|
||||
for _, v := range iv.([]interface{}) {
|
||||
hasKey(v, key, ret)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// ======== 2013.07.01 - x2j.Unmarshal, wraps xml.Unmarshal ==============
|
||||
|
||||
// Unmarshal - wraps xml.Unmarshal with handling of map[string]interface{}
|
||||
// and string type variables.
|
||||
// Usage: x2j.Unmarshal(doc,&m) where m of type map[string]interface{}
|
||||
// x2j.Unmarshal(doc,&s) where s of type string (Overrides xml.Unmarshal().)
|
||||
// x2j.Unmarshal(doc,&struct) - passed to xml.Unmarshal()
|
||||
// x2j.Unmarshal(doc,&slice) - passed to xml.Unmarshal()
|
||||
func Unmarshal(doc []byte, v interface{}) error {
|
||||
switch v.(type) {
|
||||
case *map[string]interface{}:
|
||||
m, err := ByteDocToMap(doc)
|
||||
vv := *v.(*map[string]interface{})
|
||||
for k, v := range m {
|
||||
vv[k] = v
|
||||
}
|
||||
return err
|
||||
case *string:
|
||||
s, err := ByteDocToJson(doc)
|
||||
*(v.(*string)) = s
|
||||
return err
|
||||
default:
|
||||
b := bytes.NewBuffer(doc)
|
||||
p := xml.NewDecoder(b)
|
||||
p.CharsetReader = X2jCharsetReader
|
||||
return p.Decode(v)
|
||||
// return xml.Unmarshal(doc, v)
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// ByteDocToJson - return an XML doc as a JSON string.
|
||||
// If the optional argument 'recast' is 'true', then values will be converted to boolean or float64 if possible.
|
||||
func ByteDocToJson(doc []byte, recast ...bool) (string, error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
m, merr := ByteDocToMap(doc, r)
|
||||
if m == nil || merr != nil {
|
||||
return "", merr
|
||||
}
|
||||
|
||||
b, berr := json.Marshal(m)
|
||||
if berr != nil {
|
||||
return "", berr
|
||||
}
|
||||
|
||||
// NOTE: don't have to worry about safe JSON marshaling with json.Marshal, since '<' and '>" are reservedin XML.
|
||||
return string(b), nil
|
||||
}
|
||||
|
||||
// ByteDocToMap - convert an XML doc into a map[string]interface{}.
|
||||
// (This is analogous to unmarshalling a JSON string to map[string]interface{} using json.Unmarshal().)
|
||||
// If the optional argument 'recast' is 'true', then values will be converted to boolean or float64 if possible.
|
||||
// Note: recasting is only applied to element values, not attribute values.
|
||||
func ByteDocToMap(doc []byte, recast ...bool) (map[string]interface{}, error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
n, err := ByteDocToTree(doc)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
m := make(map[string]interface{})
|
||||
m[n.key] = n.treeToMap(r)
|
||||
|
||||
return m, nil
|
||||
}
|
||||
|
||||
// ByteDocToTree - convert an XML doc into a tree of nodes.
|
||||
func ByteDocToTree(doc []byte) (*Node, error) {
|
||||
// xml.Decoder doesn't properly handle whitespace in some doc
|
||||
// see songTextString.xml test case ...
|
||||
reg, _ := regexp.Compile("[ \t\n\r]*<")
|
||||
doc = reg.ReplaceAll(doc, []byte("<"))
|
||||
|
||||
b := bytes.NewBuffer(doc)
|
||||
p := xml.NewDecoder(b)
|
||||
p.CharsetReader = X2jCharsetReader
|
||||
n, berr := xmlToTree("", nil, p)
|
||||
if berr != nil {
|
||||
return nil, berr
|
||||
}
|
||||
|
||||
return n, nil
|
||||
}
|
||||
|
||||
127
vendor/github.com/beego/x2j/x2j_bulk.go
generated
vendored
127
vendor/github.com/beego/x2j/x2j_bulk.go
generated
vendored
@@ -1,127 +0,0 @@
|
||||
// Copyright 2012-2013 Charles Banning. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file
|
||||
|
||||
// x2j_bulk.go: Process files with multiple XML messages.
|
||||
// Extends x2m_bulk.go to work with JSON strings rather than map[string]interface{}.
|
||||
|
||||
package x2j
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"encoding/json"
|
||||
"io"
|
||||
"os"
|
||||
"regexp"
|
||||
)
|
||||
|
||||
// XmlMsgsFromFileAsJson()
|
||||
// 'fname' is name of file
|
||||
// 'phandler' is the JSON string processing handler. Return of 'false' stops further processing.
|
||||
// 'ehandler' is the parsing error handler. Return of 'false' stops further processing and returns error.
|
||||
// Note: phandler() and ehandler() calls are blocking, so reading and processing of messages is serialized.
|
||||
// This means that you can stop reading the file on error or after processing a particular message.
|
||||
// To have reading and handling run concurrently, pass arguments to a go routine in handler and return true.
|
||||
func XmlMsgsFromFileAsJson(fname string, phandler func(string)(bool), ehandler func(error)(bool), recast ...bool) error {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
fi, fierr := os.Stat(fname)
|
||||
if fierr != nil {
|
||||
return fierr
|
||||
}
|
||||
fh, fherr := os.Open(fname)
|
||||
if fherr != nil {
|
||||
return fherr
|
||||
}
|
||||
defer fh.Close()
|
||||
buf := make([]byte,fi.Size())
|
||||
_, rerr := fh.Read(buf)
|
||||
if rerr != nil {
|
||||
return rerr
|
||||
}
|
||||
doc := string(buf)
|
||||
|
||||
// xml.Decoder doesn't properly handle whitespace in some doc
|
||||
// see songTextString.xml test case ...
|
||||
reg,_ := regexp.Compile("[ \t\n\r]*<")
|
||||
doc = reg.ReplaceAllString(doc,"<")
|
||||
b := bytes.NewBufferString(doc)
|
||||
|
||||
for {
|
||||
s, serr := XmlBufferToJson(b,r)
|
||||
if serr != nil && serr != io.EOF {
|
||||
if ok := ehandler(serr); !ok {
|
||||
// caused reader termination
|
||||
return serr
|
||||
}
|
||||
}
|
||||
if s != "" {
|
||||
if ok := phandler(s); !ok {
|
||||
break
|
||||
}
|
||||
}
|
||||
if serr == io.EOF {
|
||||
break
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// XmlBufferToJson - process XML message from a bytes.Buffer
|
||||
// 'b' is the buffer
|
||||
// Optional argument 'recast' coerces values to float64 or bool where possible.
|
||||
func XmlBufferToJson(b *bytes.Buffer,recast ...bool) (string,error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
|
||||
n,err := XmlBufferToTree(b)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
m := make(map[string]interface{})
|
||||
m[n.key] = n.treeToMap(r)
|
||||
|
||||
j, jerr := json.Marshal(m)
|
||||
return string(j), jerr
|
||||
}
|
||||
|
||||
// ============================= io.Reader version for stream processing ======================
|
||||
|
||||
// XmlMsgsFromReaderAsJson() - io.Reader version of XmlMsgsFromFileAsJson
|
||||
// 'rdr' is an io.Reader for an XML message (stream)
|
||||
// 'phandler' is the JSON string processing handler. Return of 'false' stops further processing.
|
||||
// 'ehandler' is the parsing error handler. Return of 'false' stops further processing and returns error.
|
||||
// Note: phandler() and ehandler() calls are blocking, so reading and processing of messages is serialized.
|
||||
// This means that you can stop reading the file on error or after processing a particular message.
|
||||
// To have reading and handling run concurrently, pass arguments to a go routine in handler and return true.
|
||||
func XmlMsgsFromReaderAsJson(rdr io.Reader, phandler func(string)(bool), ehandler func(error)(bool), recast ...bool) error {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
|
||||
for {
|
||||
s, serr := ToJson(rdr,r)
|
||||
if serr != nil && serr != io.EOF {
|
||||
if ok := ehandler(serr); !ok {
|
||||
// caused reader termination
|
||||
return serr
|
||||
}
|
||||
}
|
||||
if s != "" {
|
||||
if ok := phandler(s); !ok {
|
||||
break
|
||||
}
|
||||
}
|
||||
if serr == io.EOF {
|
||||
break
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
29
vendor/github.com/beego/x2j/x2j_test.xml
generated
vendored
29
vendor/github.com/beego/x2j/x2j_test.xml
generated
vendored
@@ -1,29 +0,0 @@
|
||||
<msg mtype="alert" mpriority="1">
|
||||
<text>help me!</text>
|
||||
<song title="A Long Time" author="Mayer Hawthorne">
|
||||
<verses>
|
||||
<verse name="verse 1" no="1">
|
||||
<line no="1">Henry was a renegade</line>
|
||||
<line no="2">Didn't like to play it safe</line>
|
||||
<line no="3">One component at a time</line>
|
||||
<line no="4">There's got to be a better way</line>
|
||||
<line no="5">Oh, people came from miles around</line>
|
||||
<line no="6">Searching for a steady job</line>
|
||||
<line no="7">Welcome to the Motor Town</line>
|
||||
<line no="8">Booming like an atom bomb</line>
|
||||
</verse>
|
||||
<verse name="verse 2" no="2">
|
||||
<line no="1">Oh, Henry was the end of the story</line>
|
||||
<line no="2">Then everything went wrong</line>
|
||||
<line no="3">And we'll return it to its former glory</line>
|
||||
<line no="4">But it just takes so long</line>
|
||||
</verse>
|
||||
</verses>
|
||||
<chorus>
|
||||
<line no="1">It's going to take a long time</line>
|
||||
<line no="2">It's going to take it, but we'll make it one day</line>
|
||||
<line no="3">It's going to take a long time</line>
|
||||
<line no="4">It's going to take it, but we'll make it one day</line>
|
||||
</chorus>
|
||||
</song>
|
||||
</msg>
|
||||
125
vendor/github.com/beego/x2j/x2j_valuesFrom.go
generated
vendored
125
vendor/github.com/beego/x2j/x2j_valuesFrom.go
generated
vendored
@@ -1,125 +0,0 @@
|
||||
// Copyright 2012-2013 Charles Banning. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file
|
||||
|
||||
// x2j_valuesFrom.go: Extract values from an arbitrary XML doc. Tag path can include wildcard characters.
|
||||
|
||||
package x2j
|
||||
|
||||
import (
|
||||
"strings"
|
||||
)
|
||||
|
||||
// ------------------- sweep up everything for some point in the node tree ---------------------
|
||||
|
||||
// ValuesFromTagPath - deliver all values for a path node from a XML doc
|
||||
// If there are no values for the path 'nil' is returned.
|
||||
// A return value of (nil, nil) means that there were no values and no errors parsing the doc.
|
||||
// 'doc' is the XML document
|
||||
// 'path' is a dot-separated path of tag nodes
|
||||
// 'getAttrs' can be set 'true' to return attribute values for "*"-terminated path
|
||||
// If a node is '*', then everything beyond is scanned for values.
|
||||
// E.g., "doc.books' might return a single value 'book' of type []interface{}, but
|
||||
// "doc.books.*" could return all the 'book' entries as []map[string]interface{}.
|
||||
// "doc.books.*.author" might return all the 'author' tag values as []string - or
|
||||
// "doc.books.*.author.lastname" might be required, depending on he schema.
|
||||
func ValuesFromTagPath(doc, path string, getAttrs ...bool) ([]interface{}, error) {
|
||||
var a bool
|
||||
if len(getAttrs) == 1 {
|
||||
a = getAttrs[0]
|
||||
}
|
||||
m, err := DocToMap(doc)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
v := ValuesFromKeyPath(m, path, a)
|
||||
return v, nil
|
||||
}
|
||||
|
||||
// ValuesFromKeyPath - deliver all values for a path node from a map[string]interface{}
|
||||
// If there are no values for the path 'nil' is returned.
|
||||
// 'm' is the map to be walked
|
||||
// 'path' is a dot-separated path of key values
|
||||
// 'getAttrs' can be set 'true' to return attribute values for "*"-terminated path
|
||||
// If a node is '*', then everything beyond is walked.
|
||||
// E.g., see ValuesFromTagPath documentation.
|
||||
func ValuesFromKeyPath(m map[string]interface{}, path string, getAttrs ...bool) []interface{} {
|
||||
var a bool
|
||||
if len(getAttrs) == 1 {
|
||||
a = getAttrs[0]
|
||||
}
|
||||
keys := strings.Split(path, ".")
|
||||
ret := make([]interface{}, 0)
|
||||
valuesFromKeyPath(&ret, m, keys, a)
|
||||
if len(ret) == 0 {
|
||||
return nil
|
||||
}
|
||||
return ret
|
||||
}
|
||||
|
||||
func valuesFromKeyPath(ret *[]interface{}, m interface{}, keys []string, getAttrs bool) {
|
||||
lenKeys := len(keys)
|
||||
|
||||
// load 'm' values into 'ret'
|
||||
// expand any lists
|
||||
if lenKeys == 0 {
|
||||
switch m.(type) {
|
||||
case map[string]interface{}:
|
||||
*ret = append(*ret, m)
|
||||
case []interface{}:
|
||||
for _, v := range m.([]interface{}) {
|
||||
*ret = append(*ret, v)
|
||||
}
|
||||
default:
|
||||
*ret = append(*ret, m)
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
// key of interest
|
||||
key := keys[0]
|
||||
switch key {
|
||||
case "*": // wildcard - scan all values
|
||||
switch m.(type) {
|
||||
case map[string]interface{}:
|
||||
for k, v := range m.(map[string]interface{}) {
|
||||
if string(k[:1]) == "-" && !getAttrs { // skip attributes?
|
||||
continue
|
||||
}
|
||||
valuesFromKeyPath(ret, v, keys[1:], getAttrs)
|
||||
}
|
||||
case []interface{}:
|
||||
for _, v := range m.([]interface{}) {
|
||||
switch v.(type) {
|
||||
// flatten out a list of maps - keys are processed
|
||||
case map[string]interface{}:
|
||||
for kk, vv := range v.(map[string]interface{}) {
|
||||
if string(kk[:1]) == "-" && !getAttrs { // skip attributes?
|
||||
continue
|
||||
}
|
||||
valuesFromKeyPath(ret, vv, keys[1:], getAttrs)
|
||||
}
|
||||
default:
|
||||
valuesFromKeyPath(ret, v, keys[1:], getAttrs)
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // key - must be map[string]interface{}
|
||||
switch m.(type) {
|
||||
case map[string]interface{}:
|
||||
if v, ok := m.(map[string]interface{})[key]; ok {
|
||||
valuesFromKeyPath(ret, v, keys[1:], getAttrs)
|
||||
}
|
||||
case []interface{}: // may be buried in list
|
||||
for _, v := range m.([]interface{}) {
|
||||
switch v.(type) {
|
||||
case map[string]interface{}:
|
||||
if vv, ok := v.(map[string]interface{})[key]; ok {
|
||||
valuesFromKeyPath(ret, vv, keys[1:], getAttrs)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
201
vendor/github.com/beego/x2j/x2m_bulk.go
generated
vendored
201
vendor/github.com/beego/x2j/x2m_bulk.go
generated
vendored
@@ -1,201 +0,0 @@
|
||||
// Copyright 2012-2013 Charles Banning. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file
|
||||
|
||||
// x2m_bulk.go: Process files with multiple XML messages.
|
||||
|
||||
package x2j
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"encoding/xml"
|
||||
"errors"
|
||||
"io"
|
||||
"os"
|
||||
"regexp"
|
||||
"sync"
|
||||
)
|
||||
|
||||
// XmlMsgsFromFile()
|
||||
// 'fname' is name of file
|
||||
// 'phandler' is the map processing handler. Return of 'false' stops further processing.
|
||||
// 'ehandler' is the parsing error handler. Return of 'false' stops further processing and returns error.
|
||||
// Note: phandler() and ehandler() calls are blocking, so reading and processing of messages is serialized.
|
||||
// This means that you can stop reading the file on error or after processing a particular message.
|
||||
// To have reading and handling run concurrently, pass arguments to a go routine in handler and return true.
|
||||
func XmlMsgsFromFile(fname string, phandler func(map[string]interface{})(bool), ehandler func(error)(bool), recast ...bool) error {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
fi, fierr := os.Stat(fname)
|
||||
if fierr != nil {
|
||||
return fierr
|
||||
}
|
||||
fh, fherr := os.Open(fname)
|
||||
if fherr != nil {
|
||||
return fherr
|
||||
}
|
||||
defer fh.Close()
|
||||
buf := make([]byte,fi.Size())
|
||||
_, rerr := fh.Read(buf)
|
||||
if rerr != nil {
|
||||
return rerr
|
||||
}
|
||||
doc := string(buf)
|
||||
|
||||
// xml.Decoder doesn't properly handle whitespace in some doc
|
||||
// see songTextString.xml test case ...
|
||||
reg,_ := regexp.Compile("[ \t\n\r]*<")
|
||||
doc = reg.ReplaceAllString(doc,"<")
|
||||
b := bytes.NewBufferString(doc)
|
||||
|
||||
for {
|
||||
m, merr := XmlBufferToMap(b,r)
|
||||
if merr != nil && merr != io.EOF {
|
||||
if ok := ehandler(merr); !ok {
|
||||
// caused reader termination
|
||||
return merr
|
||||
}
|
||||
}
|
||||
if m != nil {
|
||||
if ok := phandler(m); !ok {
|
||||
break
|
||||
}
|
||||
}
|
||||
if merr == io.EOF {
|
||||
break
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// XmlBufferToMap - process XML message from a bytes.Buffer
|
||||
// 'b' is the buffer
|
||||
// Optional argument 'recast' coerces map values to float64 or bool where possible.
|
||||
func XmlBufferToMap(b *bytes.Buffer,recast ...bool) (map[string]interface{},error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
|
||||
n,err := XmlBufferToTree(b)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
m := make(map[string]interface{})
|
||||
m[n.key] = n.treeToMap(r)
|
||||
|
||||
return m,nil
|
||||
}
|
||||
|
||||
// BufferToTree - derived from DocToTree()
|
||||
func XmlBufferToTree(b *bytes.Buffer) (*Node, error) {
|
||||
p := xml.NewDecoder(b)
|
||||
p.CharsetReader = X2jCharsetReader
|
||||
n, berr := xmlToTree("",nil,p)
|
||||
if berr != nil {
|
||||
return nil, berr
|
||||
}
|
||||
|
||||
return n,nil
|
||||
}
|
||||
|
||||
// XmlBuffer - create XML decoder buffer for a string from anywhere, not necessarily a file.
|
||||
type XmlBuffer struct {
|
||||
cnt uint64
|
||||
str *string
|
||||
buf *bytes.Buffer
|
||||
}
|
||||
var mtx sync.Mutex
|
||||
var cnt uint64
|
||||
var activeXmlBufs = make(map[uint64]*XmlBuffer)
|
||||
|
||||
// NewXmlBuffer() - creates a bytes.Buffer from a string with multiple messages
|
||||
// Use Close() function to release the buffer for garbage collection.
|
||||
func NewXmlBuffer(s string) *XmlBuffer {
|
||||
// xml.Decoder doesn't properly handle whitespace in some doc
|
||||
// see songTextString.xml test case ...
|
||||
reg,_ := regexp.Compile("[ \t\n\r]*<")
|
||||
s = reg.ReplaceAllString(s,"<")
|
||||
b := bytes.NewBufferString(s)
|
||||
buf := new(XmlBuffer)
|
||||
buf.str = &s
|
||||
buf.buf = b
|
||||
mtx.Lock()
|
||||
defer mtx.Unlock()
|
||||
buf.cnt = cnt ; cnt++
|
||||
activeXmlBufs[buf.cnt] = buf
|
||||
return buf
|
||||
}
|
||||
|
||||
// BytesNewXmlBuffer() - creates a bytes.Buffer from b with possibly multiple messages
|
||||
// Use Close() function to release the buffer for garbage collection.
|
||||
func BytesNewXmlBuffer(b []byte) *XmlBuffer {
|
||||
bb := bytes.NewBuffer(b)
|
||||
buf := new(XmlBuffer)
|
||||
buf.buf = bb
|
||||
mtx.Lock()
|
||||
defer mtx.Unlock()
|
||||
buf.cnt = cnt ; cnt++
|
||||
activeXmlBufs[buf.cnt] = buf
|
||||
return buf
|
||||
}
|
||||
|
||||
// Close() - release the buffer address for garbage collection
|
||||
func (buf *XmlBuffer)Close() {
|
||||
mtx.Lock()
|
||||
defer mtx.Unlock()
|
||||
delete(activeXmlBufs,buf.cnt)
|
||||
}
|
||||
|
||||
// NextMap() - retrieve next XML message in buffer as a map[string]interface{} value.
|
||||
// The optional argument 'recast' will try and coerce values to float64 or bool as appropriate.
|
||||
func (buf *XmlBuffer)NextMap(recast ...bool) (map[string]interface{}, error) {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
if _, ok := activeXmlBufs[buf.cnt]; !ok {
|
||||
return nil, errors.New("Buffer is not active.")
|
||||
}
|
||||
return XmlBufferToMap(buf.buf,r)
|
||||
}
|
||||
|
||||
|
||||
// ============================= io.Reader version for stream processing ======================
|
||||
|
||||
// XmlMsgsFromReader() - io.Reader version of XmlMsgsFromFile
|
||||
// 'rdr' is an io.Reader for an XML message (stream)
|
||||
// 'phandler' is the map processing handler. Return of 'false' stops further processing.
|
||||
// 'ehandler' is the parsing error handler. Return of 'false' stops further processing and returns error.
|
||||
// Note: phandler() and ehandler() calls are blocking, so reading and processing of messages is serialized.
|
||||
// This means that you can stop reading the file on error or after processing a particular message.
|
||||
// To have reading and handling run concurrently, pass arguments to a go routine in handler and return true.
|
||||
func XmlMsgsFromReader(rdr io.Reader, phandler func(map[string]interface{})(bool), ehandler func(error)(bool), recast ...bool) error {
|
||||
var r bool
|
||||
if len(recast) == 1 {
|
||||
r = recast[0]
|
||||
}
|
||||
|
||||
for {
|
||||
m, merr := ToMap(rdr,r)
|
||||
if merr != nil && merr != io.EOF {
|
||||
if ok := ehandler(merr); !ok {
|
||||
// caused reader termination
|
||||
return merr
|
||||
}
|
||||
}
|
||||
if m != nil {
|
||||
if ok := phandler(m); !ok {
|
||||
break
|
||||
}
|
||||
}
|
||||
if merr == io.EOF {
|
||||
break
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
67
vendor/github.com/beego/x2j/x2m_bulk.xml
generated
vendored
67
vendor/github.com/beego/x2j/x2m_bulk.xml
generated
vendored
@@ -1,67 +0,0 @@
|
||||
<msg mtype="alert" mpriority="1">
|
||||
<text>help me!</text>
|
||||
<song title="A Long Time" author="Mayer Hawthorne">
|
||||
<verses>
|
||||
<verse name="verse 1" no="1">
|
||||
<line no="1">Henry was a renegade</line>
|
||||
<line no="2">Didn't like to play it safe</line>
|
||||
<line no="3">One component at a time</line>
|
||||
<line no="4">There's got to be a better way</line>
|
||||
<line no="5">Oh, people came from miles around</line>
|
||||
<line no="6">Searching for a steady job</line>
|
||||
<line no="7">Welcome to the Motor Town</line>
|
||||
<line no="8">Booming like an atom bomb</line>
|
||||
</verse>
|
||||
<verse name="verse 2" no="2">
|
||||
<line no="1">Oh, Henry was the end of the story</line>
|
||||
<line no="2">Then everything went wrong</line>
|
||||
<line no="3">And we'll return it to its former glory</line>
|
||||
<line no="4">But it just takes so long</line>
|
||||
</verse>
|
||||
</verses>
|
||||
<chorus>
|
||||
<line no="1">It's going to take a long time</line>
|
||||
<line no="2">It's going to take it, but we'll make it one day</line>
|
||||
<line no="3">It's going to take a long time</line>
|
||||
<line no="4">It's going to take it, but we'll make it one day</line>
|
||||
</chorus>
|
||||
</song>
|
||||
</msg>
|
||||
<msg mtype="alert" mpriority="1">
|
||||
<text>help me!</text>
|
||||
<song title="A Long Time" author="Mayer Hawthorne">
|
||||
<verses>
|
||||
<verse name="verse 1" no="1">
|
||||
<line no="1">Henry was a renegade</line>
|
||||
<line no="2">Didn't like to play it safe</line>
|
||||
<line no="3">One component at a time</line>
|
||||
<line no="4">There's got to be a better way</line>
|
||||
<line no="5">Oh, people came from miles around</line>
|
||||
<line no="6">Searching for a steady job</line>
|
||||
<line no="7">Welcome to the Motor Town</line>
|
||||
<line no="8">Booming like an atom bomb</line>
|
||||
</verse>
|
||||
</verses>
|
||||
</song>
|
||||
</msg>
|
||||
<msg mtype="alert" mpriority="1">
|
||||
<text>help me!</text>
|
||||
<song title="A Long Time" author="Mayer Hawthorne">
|
||||
<chorus>
|
||||
<line no="1">It's going to take a long time</line>
|
||||
<line no="2">It's going to take it, but we'll make it one day</line>
|
||||
<line no="3">It's going to take a long time</line>
|
||||
<line no="4">It's going to take it, but we'll make it one day</line>
|
||||
</chorus>
|
||||
</song>
|
||||
</msg>
|
||||
<msg mtype="alert" mpriority="1">
|
||||
<text>help me!</text>
|
||||
<song title="A Long Time" author="Mayer Hawthorne">
|
||||
<chorus>
|
||||
<line no="1">It's going to take a long time</line>
|
||||
<line no="2">It's going to take it, but we'll make it one day</line>
|
||||
<line no="3">It's going to take a long time</line>
|
||||
<line no="4">It's going to take it, but we'll make it one day</line>
|
||||
</song>
|
||||
</msg>
|
||||
2
vendor/github.com/belogik/goes/.gitignore
generated
vendored
2
vendor/github.com/belogik/goes/.gitignore
generated
vendored
@@ -1,2 +0,0 @@
|
||||
*.test
|
||||
*.swp
|
||||
35
vendor/github.com/belogik/goes/.travis.yml
generated
vendored
35
vendor/github.com/belogik/goes/.travis.yml
generated
vendored
@@ -1,35 +0,0 @@
|
||||
language: go
|
||||
|
||||
go:
|
||||
- 1.1
|
||||
- 1.2
|
||||
- 1.3
|
||||
- 1.4.2
|
||||
- 1.4.3
|
||||
- 1.5
|
||||
- 1.5.1
|
||||
|
||||
env:
|
||||
matrix:
|
||||
- ES_VERSION=1.0.3 GROOVY_VER=2.0.0
|
||||
- ES_VERSION=1.1.2 GROOVY_VER=2.0.0
|
||||
- ES_VERSION=1.2.1 GROOVY_VER=2.2.0
|
||||
- ES_VERSION=1.3.4
|
||||
- ES_VERSION=1.4.4
|
||||
- ES_VERSION=1.5.2
|
||||
- ES_VERSION=1.6.0
|
||||
- ES_VERSION=1.7.0
|
||||
|
||||
before_script:
|
||||
- mkdir ${HOME}/elasticsearch
|
||||
- wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-${ES_VERSION}.tar.gz
|
||||
- tar -xzf elasticsearch-${ES_VERSION}.tar.gz -C ${HOME}/elasticsearch
|
||||
- "echo 'script.groovy.sandbox.enabled: true' >> ${HOME}/elasticsearch/elasticsearch-${ES_VERSION}/config/elasticsearch.yml"
|
||||
- 'if [[ "${ES_VERSION}" < "1.3" ]]; then ${HOME}/elasticsearch/elasticsearch-${ES_VERSION}/bin/plugin --install elasticsearch/elasticsearch-lang-groovy/${GROOVY_VER}; fi'
|
||||
- ${HOME}/elasticsearch/elasticsearch-${ES_VERSION}/bin/elasticsearch >/dev/null &
|
||||
|
||||
install:
|
||||
- go get gopkg.in/check.v1
|
||||
|
||||
script:
|
||||
- make test
|
||||
27
vendor/github.com/belogik/goes/LICENSE
generated
vendored
27
vendor/github.com/belogik/goes/LICENSE
generated
vendored
@@ -1,27 +0,0 @@
|
||||
Copyright (c) 2013 Belogik. All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
modification, are permitted provided that the following conditions are
|
||||
met:
|
||||
|
||||
* Redistributions of source code must retain the above copyright
|
||||
notice, this list of conditions and the following disclaimer.
|
||||
* Redistributions in binary form must reproduce the above
|
||||
copyright notice, this list of conditions and the following disclaimer
|
||||
in the documentation and/or other materials provided with the
|
||||
distribution.
|
||||
* Neither the name of Belogik nor the names of its
|
||||
contributors may be used to endorse or promote products derived from
|
||||
this software without specific prior written permission.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
10
vendor/github.com/belogik/goes/Makefile
generated
vendored
10
vendor/github.com/belogik/goes/Makefile
generated
vendored
@@ -1,10 +0,0 @@
|
||||
help:
|
||||
@echo "Available targets:"
|
||||
@echo "- test: run tests"
|
||||
@echo "- installdependencies: installs dependencies declared in dependencies.txt"
|
||||
|
||||
installdependencies:
|
||||
cat dependencies.txt | xargs go get
|
||||
|
||||
test: installdependencies
|
||||
go test -i && go test
|
||||
7
vendor/github.com/belogik/goes/README
generated
vendored
7
vendor/github.com/belogik/goes/README
generated
vendored
@@ -1,7 +0,0 @@
|
||||
There is a new maintener for this library.
|
||||
|
||||
Please go here : https://github.com/OwnLocal/goes
|
||||
|
||||
!!!!! By using this repo you are running on thin ice !!!!!!
|
||||
|
||||
https://github.com/belogik/goes/issues/40 might be of interest for you.
|
||||
1
vendor/github.com/belogik/goes/TODO
generated
vendored
1
vendor/github.com/belogik/goes/TODO
generated
vendored
@@ -1 +0,0 @@
|
||||
- Add Gzip support to bulk data to save bandwith
|
||||
1
vendor/github.com/belogik/goes/dependencies.txt
generated
vendored
1
vendor/github.com/belogik/goes/dependencies.txt
generated
vendored
@@ -1 +0,0 @@
|
||||
launchpad.net/gocheck
|
||||
603
vendor/github.com/belogik/goes/goes.go
generated
vendored
603
vendor/github.com/belogik/goes/goes.go
generated
vendored
@@ -1,603 +0,0 @@
|
||||
// Copyright 2013 Belogik. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
// Package goes provides an API to access Elasticsearch.
|
||||
package goes
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"encoding/json"
|
||||
"errors"
|
||||
"fmt"
|
||||
"io/ioutil"
|
||||
"net/http"
|
||||
"net/url"
|
||||
"reflect"
|
||||
"strconv"
|
||||
"strings"
|
||||
)
|
||||
|
||||
const (
|
||||
BULK_COMMAND_INDEX = "index"
|
||||
BULK_COMMAND_DELETE = "delete"
|
||||
)
|
||||
|
||||
func (err *SearchError) Error() string {
|
||||
return fmt.Sprintf("[%d] %s", err.StatusCode, err.Msg)
|
||||
}
|
||||
|
||||
// NewConnection initiates a new Connection to an elasticsearch server
|
||||
//
|
||||
// This function is pretty useless for now but might be useful in a near future
|
||||
// if wee need more features like connection pooling or load balancing.
|
||||
func NewConnection(host string, port string) *Connection {
|
||||
return &Connection{host, port, http.DefaultClient}
|
||||
}
|
||||
|
||||
func (c *Connection) WithClient(cl *http.Client) *Connection {
|
||||
c.Client = cl
|
||||
return c
|
||||
}
|
||||
|
||||
// CreateIndex creates a new index represented by a name and a mapping
|
||||
func (c *Connection) CreateIndex(name string, mapping interface{}) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: mapping,
|
||||
IndexList: []string{name},
|
||||
method: "PUT",
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// DeleteIndex deletes an index represented by a name
|
||||
func (c *Connection) DeleteIndex(name string) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: []string{name},
|
||||
method: "DELETE",
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// RefreshIndex refreshes an index represented by a name
|
||||
func (c *Connection) RefreshIndex(name string) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: []string{name},
|
||||
method: "POST",
|
||||
api: "_refresh",
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// UpdateIndexSettings updates settings for existing index represented by a name and a settings
|
||||
// as described here: https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-update-settings.html
|
||||
func (c *Connection) UpdateIndexSettings(name string, settings interface{}) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: settings,
|
||||
IndexList: []string{name},
|
||||
method: "PUT",
|
||||
api: "_settings",
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Optimize an index represented by a name, extra args are also allowed please check:
|
||||
// http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/indices-optimize.html#indices-optimize
|
||||
func (c *Connection) Optimize(indexList []string, extraArgs url.Values) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: indexList,
|
||||
ExtraArgs: extraArgs,
|
||||
method: "POST",
|
||||
api: "_optimize",
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Stats fetches statistics (_stats) for the current elasticsearch server
|
||||
func (c *Connection) Stats(indexList []string, extraArgs url.Values) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: indexList,
|
||||
ExtraArgs: extraArgs,
|
||||
method: "GET",
|
||||
api: "_stats",
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// IndexStatus fetches the status (_status) for the indices defined in
|
||||
// indexList. Use _all in indexList to get stats for all indices
|
||||
func (c *Connection) IndexStatus(indexList []string) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: indexList,
|
||||
method: "GET",
|
||||
api: "_status",
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Bulk adds multiple documents in bulk mode
|
||||
func (c *Connection) BulkSend(documents []Document) (*Response, error) {
|
||||
// We do not generate a traditional JSON here (often a one liner)
|
||||
// Elasticsearch expects one line of JSON per line (EOL = \n)
|
||||
// plus an extra \n at the very end of the document
|
||||
//
|
||||
// More informations about the Bulk JSON format for Elasticsearch:
|
||||
//
|
||||
// - http://www.elasticsearch.org/guide/reference/api/bulk.html
|
||||
//
|
||||
// This is quite annoying for us as we can not use the simple JSON
|
||||
// Marshaler available in Run().
|
||||
//
|
||||
// We have to generate this special JSON by ourselves which leads to
|
||||
// the code below.
|
||||
//
|
||||
// I know it is unreadable I must find an elegant way to fix this.
|
||||
|
||||
// len(documents) * 2 : action + optional_sources
|
||||
// + 1 : room for the trailing \n
|
||||
bulkData := make([][]byte, len(documents)*2+1)
|
||||
i := 0
|
||||
|
||||
for _, doc := range documents {
|
||||
action, err := json.Marshal(map[string]interface{}{
|
||||
doc.BulkCommand: map[string]interface{}{
|
||||
"_index": doc.Index,
|
||||
"_type": doc.Type,
|
||||
"_id": doc.Id,
|
||||
},
|
||||
})
|
||||
|
||||
if err != nil {
|
||||
return &Response{}, err
|
||||
}
|
||||
|
||||
bulkData[i] = action
|
||||
i++
|
||||
|
||||
if doc.Fields != nil {
|
||||
if docFields, ok := doc.Fields.(map[string]interface{}); ok {
|
||||
if len(docFields) == 0 {
|
||||
continue
|
||||
}
|
||||
} else {
|
||||
typeOfFields := reflect.TypeOf(doc.Fields)
|
||||
if typeOfFields.Kind() == reflect.Ptr {
|
||||
typeOfFields = typeOfFields.Elem()
|
||||
}
|
||||
if typeOfFields.Kind() != reflect.Struct {
|
||||
return &Response{}, fmt.Errorf("Document fields not in struct or map[string]interface{} format")
|
||||
}
|
||||
if typeOfFields.NumField() == 0 {
|
||||
continue
|
||||
}
|
||||
}
|
||||
|
||||
sources, err := json.Marshal(doc.Fields)
|
||||
if err != nil {
|
||||
return &Response{}, err
|
||||
}
|
||||
|
||||
bulkData[i] = sources
|
||||
i++
|
||||
}
|
||||
}
|
||||
|
||||
// forces an extra trailing \n absolutely necessary for elasticsearch
|
||||
bulkData[len(bulkData)-1] = []byte(nil)
|
||||
|
||||
r := Request{
|
||||
Conn: c,
|
||||
method: "POST",
|
||||
api: "_bulk",
|
||||
bulkData: bytes.Join(bulkData, []byte("\n")),
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Search executes a search query against an index
|
||||
func (c *Connection) Search(query interface{}, indexList []string, typeList []string, extraArgs url.Values) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: query,
|
||||
IndexList: indexList,
|
||||
TypeList: typeList,
|
||||
method: "POST",
|
||||
api: "_search",
|
||||
ExtraArgs: extraArgs,
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Count executes a count query against an index, use the Count field in the response for the result
|
||||
func (c *Connection) Count(query interface{}, indexList []string, typeList []string, extraArgs url.Values) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: query,
|
||||
IndexList: indexList,
|
||||
TypeList: typeList,
|
||||
method: "POST",
|
||||
api: "_count",
|
||||
ExtraArgs: extraArgs,
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
//Query runs a query against an index using the provided http method.
|
||||
//This method can be used to execute a delete by query, just pass in "DELETE"
|
||||
//for the HTTP method.
|
||||
func (c *Connection) Query(query interface{}, indexList []string, typeList []string, httpMethod string, extraArgs url.Values) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: query,
|
||||
IndexList: indexList,
|
||||
TypeList: typeList,
|
||||
method: httpMethod,
|
||||
api: "_query",
|
||||
ExtraArgs: extraArgs,
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Scan starts scroll over an index
|
||||
func (c *Connection) Scan(query interface{}, indexList []string, typeList []string, timeout string, size int) (*Response, error) {
|
||||
v := url.Values{}
|
||||
v.Add("search_type", "scan")
|
||||
v.Add("scroll", timeout)
|
||||
v.Add("size", strconv.Itoa(size))
|
||||
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: query,
|
||||
IndexList: indexList,
|
||||
TypeList: typeList,
|
||||
method: "POST",
|
||||
api: "_search",
|
||||
ExtraArgs: v,
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Scroll fetches data by scroll id
|
||||
func (c *Connection) Scroll(scrollId string, timeout string) (*Response, error) {
|
||||
v := url.Values{}
|
||||
v.Add("scroll", timeout)
|
||||
|
||||
r := Request{
|
||||
Conn: c,
|
||||
method: "POST",
|
||||
api: "_search/scroll",
|
||||
ExtraArgs: v,
|
||||
Body: []byte(scrollId),
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Get a typed document by its id
|
||||
func (c *Connection) Get(index string, documentType string, id string, extraArgs url.Values) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: []string{index},
|
||||
method: "GET",
|
||||
api: documentType + "/" + id,
|
||||
ExtraArgs: extraArgs,
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Index indexes a Document
|
||||
// The extraArgs is a list of url.Values that you can send to elasticsearch as
|
||||
// URL arguments, for example, to control routing, ttl, version, op_type, etc.
|
||||
func (c *Connection) Index(d Document, extraArgs url.Values) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: d.Fields,
|
||||
IndexList: []string{d.Index.(string)},
|
||||
TypeList: []string{d.Type},
|
||||
ExtraArgs: extraArgs,
|
||||
method: "POST",
|
||||
}
|
||||
|
||||
if d.Id != nil {
|
||||
r.method = "PUT"
|
||||
r.id = d.Id.(string)
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Delete deletes a Document d
|
||||
// The extraArgs is a list of url.Values that you can send to elasticsearch as
|
||||
// URL arguments, for example, to control routing.
|
||||
func (c *Connection) Delete(d Document, extraArgs url.Values) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: []string{d.Index.(string)},
|
||||
TypeList: []string{d.Type},
|
||||
ExtraArgs: extraArgs,
|
||||
method: "DELETE",
|
||||
id: d.Id.(string),
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// Run executes an elasticsearch Request. It converts data to Json, sends the
|
||||
// request and returns the Response obtained
|
||||
func (req *Request) Run() (*Response, error) {
|
||||
body, statusCode, err := req.run()
|
||||
esResp := &Response{Status: statusCode}
|
||||
|
||||
if err != nil {
|
||||
return esResp, err
|
||||
}
|
||||
|
||||
if req.method != "HEAD" {
|
||||
err = json.Unmarshal(body, &esResp)
|
||||
if err != nil {
|
||||
return esResp, err
|
||||
}
|
||||
err = json.Unmarshal(body, &esResp.Raw)
|
||||
if err != nil {
|
||||
return esResp, err
|
||||
}
|
||||
}
|
||||
|
||||
if req.api == "_bulk" && esResp.Errors {
|
||||
for _, item := range esResp.Items {
|
||||
for _, i := range item {
|
||||
if i.Error != "" {
|
||||
return esResp, &SearchError{i.Error, i.Status}
|
||||
}
|
||||
}
|
||||
}
|
||||
return esResp, &SearchError{Msg: "Unknown error while bulk indexing"}
|
||||
}
|
||||
|
||||
if esResp.Error != "" {
|
||||
return esResp, &SearchError{esResp.Error, esResp.Status}
|
||||
}
|
||||
|
||||
return esResp, nil
|
||||
}
|
||||
|
||||
func (req *Request) run() ([]byte, uint64, error) {
|
||||
postData := []byte{}
|
||||
|
||||
// XXX : refactor this
|
||||
if len(req.Body) > 0 {
|
||||
postData = req.Body
|
||||
} else if req.api == "_bulk" {
|
||||
postData = req.bulkData
|
||||
} else {
|
||||
b, err := json.Marshal(req.Query)
|
||||
if err != nil {
|
||||
return nil, 0, err
|
||||
}
|
||||
postData = b
|
||||
}
|
||||
|
||||
reader := bytes.NewReader(postData)
|
||||
|
||||
newReq, err := http.NewRequest(req.method, req.Url(), reader)
|
||||
if err != nil {
|
||||
return nil, 0, err
|
||||
}
|
||||
|
||||
if req.method == "POST" || req.method == "PUT" {
|
||||
newReq.Header.Set("Content-Type", "application/json")
|
||||
}
|
||||
|
||||
resp, err := req.Conn.Client.Do(newReq)
|
||||
if err != nil {
|
||||
return nil, 0, err
|
||||
}
|
||||
|
||||
defer resp.Body.Close()
|
||||
|
||||
body, err := ioutil.ReadAll(resp.Body)
|
||||
if err != nil {
|
||||
return nil, uint64(resp.StatusCode), err
|
||||
}
|
||||
|
||||
if resp.StatusCode > 201 && resp.StatusCode < 400 {
|
||||
return nil, uint64(resp.StatusCode), errors.New(string(body))
|
||||
}
|
||||
|
||||
return body, uint64(resp.StatusCode), nil
|
||||
}
|
||||
|
||||
// Url builds a Request for a URL
|
||||
func (r *Request) Url() string {
|
||||
path := "/" + strings.Join(r.IndexList, ",")
|
||||
|
||||
if len(r.TypeList) > 0 {
|
||||
path += "/" + strings.Join(r.TypeList, ",")
|
||||
}
|
||||
|
||||
// XXX : for indexing documents using the normal (non bulk) API
|
||||
if len(r.id) > 0 {
|
||||
path += "/" + r.id
|
||||
}
|
||||
|
||||
path += "/" + r.api
|
||||
|
||||
u := url.URL{
|
||||
Scheme: "http",
|
||||
Host: fmt.Sprintf("%s:%s", r.Conn.Host, r.Conn.Port),
|
||||
Path: path,
|
||||
RawQuery: r.ExtraArgs.Encode(),
|
||||
}
|
||||
|
||||
return u.String()
|
||||
}
|
||||
|
||||
// Buckets returns list of buckets in aggregation
|
||||
func (a Aggregation) Buckets() []Bucket {
|
||||
result := []Bucket{}
|
||||
if buckets, ok := a["buckets"]; ok {
|
||||
for _, bucket := range buckets.([]interface{}) {
|
||||
result = append(result, bucket.(map[string]interface{}))
|
||||
}
|
||||
}
|
||||
|
||||
return result
|
||||
}
|
||||
|
||||
// Key returns key for aggregation bucket
|
||||
func (b Bucket) Key() interface{} {
|
||||
return b["key"]
|
||||
}
|
||||
|
||||
// DocCount returns count of documents in this bucket
|
||||
func (b Bucket) DocCount() uint64 {
|
||||
return uint64(b["doc_count"].(float64))
|
||||
}
|
||||
|
||||
// Aggregation returns aggregation by name from bucket
|
||||
func (b Bucket) Aggregation(name string) Aggregation {
|
||||
if agg, ok := b[name]; ok {
|
||||
return agg.(map[string]interface{})
|
||||
} else {
|
||||
return Aggregation{}
|
||||
}
|
||||
}
|
||||
|
||||
// PutMapping registers a specific mapping for one or more types in one or more indexes
|
||||
func (c *Connection) PutMapping(typeName string, mapping interface{}, indexes []string) (*Response, error) {
|
||||
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: mapping,
|
||||
IndexList: indexes,
|
||||
method: "PUT",
|
||||
api: "_mappings/" + typeName,
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
func (c *Connection) GetMapping(types []string, indexes []string) (*Response, error) {
|
||||
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: indexes,
|
||||
method: "GET",
|
||||
api: "_mapping/" + strings.Join(types, ","),
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// IndicesExist checks whether index (or indices) exist on the server
|
||||
func (c *Connection) IndicesExist(indexes []string) (bool, error) {
|
||||
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: indexes,
|
||||
method: "HEAD",
|
||||
}
|
||||
|
||||
resp, err := r.Run()
|
||||
|
||||
return resp.Status == 200, err
|
||||
}
|
||||
|
||||
func (c *Connection) Update(d Document, query interface{}, extraArgs url.Values) (*Response, error) {
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: query,
|
||||
IndexList: []string{d.Index.(string)},
|
||||
TypeList: []string{d.Type},
|
||||
ExtraArgs: extraArgs,
|
||||
method: "POST",
|
||||
api: "_update",
|
||||
}
|
||||
|
||||
if d.Id != nil {
|
||||
r.id = d.Id.(string)
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// DeleteMapping deletes a mapping along with all data in the type
|
||||
func (c *Connection) DeleteMapping(typeName string, indexes []string) (*Response, error) {
|
||||
|
||||
r := Request{
|
||||
Conn: c,
|
||||
IndexList: indexes,
|
||||
method: "DELETE",
|
||||
api: "_mappings/" + typeName,
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
func (c *Connection) modifyAlias(action string, alias string, indexes []string) (*Response, error) {
|
||||
command := map[string]interface{}{
|
||||
"actions": make([]map[string]interface{}, 1),
|
||||
}
|
||||
|
||||
for _, index := range indexes {
|
||||
command["actions"] = append(command["actions"].([]map[string]interface{}), map[string]interface{}{
|
||||
action: map[string]interface{}{
|
||||
"index": index,
|
||||
"alias": alias,
|
||||
},
|
||||
})
|
||||
}
|
||||
|
||||
r := Request{
|
||||
Conn: c,
|
||||
Query: command,
|
||||
method: "POST",
|
||||
api: "_aliases",
|
||||
}
|
||||
|
||||
return r.Run()
|
||||
}
|
||||
|
||||
// AddAlias creates an alias to one or more indexes
|
||||
func (c *Connection) AddAlias(alias string, indexes []string) (*Response, error) {
|
||||
return c.modifyAlias("add", alias, indexes)
|
||||
}
|
||||
|
||||
// RemoveAlias removes an alias to one or more indexes
|
||||
func (c *Connection) RemoveAlias(alias string, indexes []string) (*Response, error) {
|
||||
return c.modifyAlias("remove", alias, indexes)
|
||||
}
|
||||
|
||||
// AliasExists checks whether alias is defined on the server
|
||||
func (c *Connection) AliasExists(alias string) (bool, error) {
|
||||
|
||||
r := Request{
|
||||
Conn: c,
|
||||
method: "HEAD",
|
||||
api: "_alias/" + alias,
|
||||
}
|
||||
|
||||
resp, err := r.Run()
|
||||
|
||||
return resp.Status == 200, err
|
||||
}
|
||||
184
vendor/github.com/belogik/goes/structs.go
generated
vendored
184
vendor/github.com/belogik/goes/structs.go
generated
vendored
@@ -1,184 +0,0 @@
|
||||
// Copyright 2013 Belogik. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package goes
|
||||
|
||||
import (
|
||||
"net/http"
|
||||
"net/url"
|
||||
)
|
||||
|
||||
// Represents a Connection object to elasticsearch
|
||||
type Connection struct {
|
||||
// The host to connect to
|
||||
Host string
|
||||
|
||||
// The port to use
|
||||
Port string
|
||||
|
||||
// Client is the http client used to make requests, allowing settings things
|
||||
// such as timeouts etc
|
||||
Client *http.Client
|
||||
}
|
||||
|
||||
// Represents a Request to elasticsearch
|
||||
type Request struct {
|
||||
// Which connection will be used
|
||||
Conn *Connection
|
||||
|
||||
// A search query
|
||||
Query interface{}
|
||||
|
||||
// Which index to search into
|
||||
IndexList []string
|
||||
|
||||
// Which type to search into
|
||||
TypeList []string
|
||||
|
||||
// HTTP Method to user (GET, POST ...)
|
||||
method string
|
||||
|
||||
// Which api keyword (_search, _bulk, etc) to use
|
||||
api string
|
||||
|
||||
// Bulk data
|
||||
bulkData []byte
|
||||
|
||||
// Request body
|
||||
Body []byte
|
||||
|
||||
// A list of extra URL arguments
|
||||
ExtraArgs url.Values
|
||||
|
||||
// Used for the id field when indexing a document
|
||||
id string
|
||||
}
|
||||
|
||||
// Represents a Response from elasticsearch
|
||||
type Response struct {
|
||||
Acknowledged bool
|
||||
Error string
|
||||
Errors bool
|
||||
Status uint64
|
||||
Took uint64
|
||||
TimedOut bool `json:"timed_out"`
|
||||
Shards Shard `json:"_shards"`
|
||||
Hits Hits
|
||||
Index string `json:"_index"`
|
||||
Id string `json:"_id"`
|
||||
Type string `json:"_type"`
|
||||
Version int `json:"_version"`
|
||||
Found bool
|
||||
Count int
|
||||
|
||||
// Used by the _stats API
|
||||
All All `json:"_all"`
|
||||
|
||||
// Used by the _bulk API
|
||||
Items []map[string]Item `json:"items,omitempty"`
|
||||
|
||||
// Used by the GET API
|
||||
Source map[string]interface{} `json:"_source"`
|
||||
Fields map[string]interface{} `json:"fields"`
|
||||
|
||||
// Used by the _status API
|
||||
Indices map[string]IndexStatus
|
||||
|
||||
// Scroll id for iteration
|
||||
ScrollId string `json:"_scroll_id"`
|
||||
|
||||
Aggregations map[string]Aggregation `json:"aggregations,omitempty"`
|
||||
|
||||
Raw map[string]interface{}
|
||||
}
|
||||
|
||||
// Represents an aggregation from response
|
||||
type Aggregation map[string]interface{}
|
||||
|
||||
// Represents a bucket for aggregation
|
||||
type Bucket map[string]interface{}
|
||||
|
||||
// Represents a document to send to elasticsearch
|
||||
type Document struct {
|
||||
// XXX : interface as we can support nil values
|
||||
Index interface{}
|
||||
Type string
|
||||
Id interface{}
|
||||
BulkCommand string
|
||||
Fields interface{}
|
||||
}
|
||||
|
||||
// Represents the "items" field in a _bulk response
|
||||
type Item struct {
|
||||
Type string `json:"_type"`
|
||||
Id string `json:"_id"`
|
||||
Index string `json:"_index"`
|
||||
Version int `json:"_version"`
|
||||
Error string `json:"error"`
|
||||
Status uint64 `json:"status"`
|
||||
}
|
||||
|
||||
// Represents the "_all" field when calling the _stats API
|
||||
// This is minimal but this is what I only need
|
||||
type All struct {
|
||||
Indices map[string]StatIndex `json:"indices"`
|
||||
Primaries map[string]StatPrimary `json:"primaries"`
|
||||
}
|
||||
|
||||
type StatIndex struct {
|
||||
Primaries map[string]StatPrimary `json:"primaries"`
|
||||
}
|
||||
|
||||
type StatPrimary struct {
|
||||
// primary/docs:
|
||||
Count int
|
||||
Deleted int
|
||||
}
|
||||
|
||||
// Represents the "shard" struct as returned by elasticsearch
|
||||
type Shard struct {
|
||||
Total uint64
|
||||
Successful uint64
|
||||
Failed uint64
|
||||
}
|
||||
|
||||
// Represent a hit returned by a search
|
||||
type Hit struct {
|
||||
Index string `json:"_index"`
|
||||
Type string `json:"_type"`
|
||||
Id string `json:"_id"`
|
||||
Score float64 `json:"_score"`
|
||||
Source map[string]interface{} `json:"_source"`
|
||||
Highlight map[string]interface{} `json:"highlight"`
|
||||
Fields map[string]interface{} `json:"fields"`
|
||||
}
|
||||
|
||||
// Represent the hits structure as returned by elasticsearch
|
||||
type Hits struct {
|
||||
Total uint64
|
||||
// max_score may contain the "null" value
|
||||
MaxScore interface{} `json:"max_score"`
|
||||
Hits []Hit
|
||||
}
|
||||
|
||||
type SearchError struct {
|
||||
Msg string
|
||||
StatusCode uint64
|
||||
}
|
||||
|
||||
// Represent the status for a given index for the _status command
|
||||
type IndexStatus struct {
|
||||
// XXX : problem, int will be marshaled to a float64 which seems logical
|
||||
// XXX : is it better to use strings even for int values or to keep
|
||||
// XXX : interfaces and deal with float64 ?
|
||||
Index map[string]interface{}
|
||||
|
||||
Translog map[string]uint64
|
||||
Docs map[string]uint64
|
||||
Merges map[string]interface{}
|
||||
Refresh map[string]interface{}
|
||||
Flush map[string]interface{}
|
||||
|
||||
// TODO: add shards support later, we do not need it for the moment
|
||||
}
|
||||
202
vendor/github.com/bradfitz/gomemcache/LICENSE
generated
vendored
202
vendor/github.com/bradfitz/gomemcache/LICENSE
generated
vendored
@@ -1,202 +0,0 @@
|
||||
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
687
vendor/github.com/bradfitz/gomemcache/memcache/memcache.go
generated
vendored
687
vendor/github.com/bradfitz/gomemcache/memcache/memcache.go
generated
vendored
@@ -1,687 +0,0 @@
|
||||
/*
|
||||
Copyright 2011 Google Inc.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
*/
|
||||
|
||||
// Package memcache provides a client for the memcached cache server.
|
||||
package memcache
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"bytes"
|
||||
"errors"
|
||||
"fmt"
|
||||
"io"
|
||||
"net"
|
||||
|
||||
"strconv"
|
||||
"strings"
|
||||
"sync"
|
||||
"time"
|
||||
)
|
||||
|
||||
// Similar to:
|
||||
// https://godoc.org/google.golang.org/appengine/memcache
|
||||
|
||||
var (
|
||||
// ErrCacheMiss means that a Get failed because the item wasn't present.
|
||||
ErrCacheMiss = errors.New("memcache: cache miss")
|
||||
|
||||
// ErrCASConflict means that a CompareAndSwap call failed due to the
|
||||
// cached value being modified between the Get and the CompareAndSwap.
|
||||
// If the cached value was simply evicted rather than replaced,
|
||||
// ErrNotStored will be returned instead.
|
||||
ErrCASConflict = errors.New("memcache: compare-and-swap conflict")
|
||||
|
||||
// ErrNotStored means that a conditional write operation (i.e. Add or
|
||||
// CompareAndSwap) failed because the condition was not satisfied.
|
||||
ErrNotStored = errors.New("memcache: item not stored")
|
||||
|
||||
// ErrServer means that a server error occurred.
|
||||
ErrServerError = errors.New("memcache: server error")
|
||||
|
||||
// ErrNoStats means that no statistics were available.
|
||||
ErrNoStats = errors.New("memcache: no statistics available")
|
||||
|
||||
// ErrMalformedKey is returned when an invalid key is used.
|
||||
// Keys must be at maximum 250 bytes long and not
|
||||
// contain whitespace or control characters.
|
||||
ErrMalformedKey = errors.New("malformed: key is too long or contains invalid characters")
|
||||
|
||||
// ErrNoServers is returned when no servers are configured or available.
|
||||
ErrNoServers = errors.New("memcache: no servers configured or available")
|
||||
)
|
||||
|
||||
const (
|
||||
// DefaultTimeout is the default socket read/write timeout.
|
||||
DefaultTimeout = 100 * time.Millisecond
|
||||
|
||||
// DefaultMaxIdleConns is the default maximum number of idle connections
|
||||
// kept for any single address.
|
||||
DefaultMaxIdleConns = 2
|
||||
)
|
||||
|
||||
const buffered = 8 // arbitrary buffered channel size, for readability
|
||||
|
||||
// resumableError returns true if err is only a protocol-level cache error.
|
||||
// This is used to determine whether or not a server connection should
|
||||
// be re-used or not. If an error occurs, by default we don't reuse the
|
||||
// connection, unless it was just a cache error.
|
||||
func resumableError(err error) bool {
|
||||
switch err {
|
||||
case ErrCacheMiss, ErrCASConflict, ErrNotStored, ErrMalformedKey:
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func legalKey(key string) bool {
|
||||
if len(key) > 250 {
|
||||
return false
|
||||
}
|
||||
for i := 0; i < len(key); i++ {
|
||||
if key[i] <= ' ' || key[i] == 0x7f {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
var (
|
||||
crlf = []byte("\r\n")
|
||||
space = []byte(" ")
|
||||
resultOK = []byte("OK\r\n")
|
||||
resultStored = []byte("STORED\r\n")
|
||||
resultNotStored = []byte("NOT_STORED\r\n")
|
||||
resultExists = []byte("EXISTS\r\n")
|
||||
resultNotFound = []byte("NOT_FOUND\r\n")
|
||||
resultDeleted = []byte("DELETED\r\n")
|
||||
resultEnd = []byte("END\r\n")
|
||||
resultOk = []byte("OK\r\n")
|
||||
resultTouched = []byte("TOUCHED\r\n")
|
||||
|
||||
resultClientErrorPrefix = []byte("CLIENT_ERROR ")
|
||||
)
|
||||
|
||||
// New returns a memcache client using the provided server(s)
|
||||
// with equal weight. If a server is listed multiple times,
|
||||
// it gets a proportional amount of weight.
|
||||
func New(server ...string) *Client {
|
||||
ss := new(ServerList)
|
||||
ss.SetServers(server...)
|
||||
return NewFromSelector(ss)
|
||||
}
|
||||
|
||||
// NewFromSelector returns a new Client using the provided ServerSelector.
|
||||
func NewFromSelector(ss ServerSelector) *Client {
|
||||
return &Client{selector: ss}
|
||||
}
|
||||
|
||||
// Client is a memcache client.
|
||||
// It is safe for unlocked use by multiple concurrent goroutines.
|
||||
type Client struct {
|
||||
// Timeout specifies the socket read/write timeout.
|
||||
// If zero, DefaultTimeout is used.
|
||||
Timeout time.Duration
|
||||
|
||||
// MaxIdleConns specifies the maximum number of idle connections that will
|
||||
// be maintained per address. If less than one, DefaultMaxIdleConns will be
|
||||
// used.
|
||||
//
|
||||
// Consider your expected traffic rates and latency carefully. This should
|
||||
// be set to a number higher than your peak parallel requests.
|
||||
MaxIdleConns int
|
||||
|
||||
selector ServerSelector
|
||||
|
||||
lk sync.Mutex
|
||||
freeconn map[string][]*conn
|
||||
}
|
||||
|
||||
// Item is an item to be got or stored in a memcached server.
|
||||
type Item struct {
|
||||
// Key is the Item's key (250 bytes maximum).
|
||||
Key string
|
||||
|
||||
// Value is the Item's value.
|
||||
Value []byte
|
||||
|
||||
// Flags are server-opaque flags whose semantics are entirely
|
||||
// up to the app.
|
||||
Flags uint32
|
||||
|
||||
// Expiration is the cache expiration time, in seconds: either a relative
|
||||
// time from now (up to 1 month), or an absolute Unix epoch time.
|
||||
// Zero means the Item has no expiration time.
|
||||
Expiration int32
|
||||
|
||||
// Compare and swap ID.
|
||||
casid uint64
|
||||
}
|
||||
|
||||
// conn is a connection to a server.
|
||||
type conn struct {
|
||||
nc net.Conn
|
||||
rw *bufio.ReadWriter
|
||||
addr net.Addr
|
||||
c *Client
|
||||
}
|
||||
|
||||
// release returns this connection back to the client's free pool
|
||||
func (cn *conn) release() {
|
||||
cn.c.putFreeConn(cn.addr, cn)
|
||||
}
|
||||
|
||||
func (cn *conn) extendDeadline() {
|
||||
cn.nc.SetDeadline(time.Now().Add(cn.c.netTimeout()))
|
||||
}
|
||||
|
||||
// condRelease releases this connection if the error pointed to by err
|
||||
// is nil (not an error) or is only a protocol level error (e.g. a
|
||||
// cache miss). The purpose is to not recycle TCP connections that
|
||||
// are bad.
|
||||
func (cn *conn) condRelease(err *error) {
|
||||
if *err == nil || resumableError(*err) {
|
||||
cn.release()
|
||||
} else {
|
||||
cn.nc.Close()
|
||||
}
|
||||
}
|
||||
|
||||
func (c *Client) putFreeConn(addr net.Addr, cn *conn) {
|
||||
c.lk.Lock()
|
||||
defer c.lk.Unlock()
|
||||
if c.freeconn == nil {
|
||||
c.freeconn = make(map[string][]*conn)
|
||||
}
|
||||
freelist := c.freeconn[addr.String()]
|
||||
if len(freelist) >= c.maxIdleConns() {
|
||||
cn.nc.Close()
|
||||
return
|
||||
}
|
||||
c.freeconn[addr.String()] = append(freelist, cn)
|
||||
}
|
||||
|
||||
func (c *Client) getFreeConn(addr net.Addr) (cn *conn, ok bool) {
|
||||
c.lk.Lock()
|
||||
defer c.lk.Unlock()
|
||||
if c.freeconn == nil {
|
||||
return nil, false
|
||||
}
|
||||
freelist, ok := c.freeconn[addr.String()]
|
||||
if !ok || len(freelist) == 0 {
|
||||
return nil, false
|
||||
}
|
||||
cn = freelist[len(freelist)-1]
|
||||
c.freeconn[addr.String()] = freelist[:len(freelist)-1]
|
||||
return cn, true
|
||||
}
|
||||
|
||||
func (c *Client) netTimeout() time.Duration {
|
||||
if c.Timeout != 0 {
|
||||
return c.Timeout
|
||||
}
|
||||
return DefaultTimeout
|
||||
}
|
||||
|
||||
func (c *Client) maxIdleConns() int {
|
||||
if c.MaxIdleConns > 0 {
|
||||
return c.MaxIdleConns
|
||||
}
|
||||
return DefaultMaxIdleConns
|
||||
}
|
||||
|
||||
// ConnectTimeoutError is the error type used when it takes
|
||||
// too long to connect to the desired host. This level of
|
||||
// detail can generally be ignored.
|
||||
type ConnectTimeoutError struct {
|
||||
Addr net.Addr
|
||||
}
|
||||
|
||||
func (cte *ConnectTimeoutError) Error() string {
|
||||
return "memcache: connect timeout to " + cte.Addr.String()
|
||||
}
|
||||
|
||||
func (c *Client) dial(addr net.Addr) (net.Conn, error) {
|
||||
type connError struct {
|
||||
cn net.Conn
|
||||
err error
|
||||
}
|
||||
|
||||
nc, err := net.DialTimeout(addr.Network(), addr.String(), c.netTimeout())
|
||||
if err == nil {
|
||||
return nc, nil
|
||||
}
|
||||
|
||||
if ne, ok := err.(net.Error); ok && ne.Timeout() {
|
||||
return nil, &ConnectTimeoutError{addr}
|
||||
}
|
||||
|
||||
return nil, err
|
||||
}
|
||||
|
||||
func (c *Client) getConn(addr net.Addr) (*conn, error) {
|
||||
cn, ok := c.getFreeConn(addr)
|
||||
if ok {
|
||||
cn.extendDeadline()
|
||||
return cn, nil
|
||||
}
|
||||
nc, err := c.dial(addr)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
cn = &conn{
|
||||
nc: nc,
|
||||
addr: addr,
|
||||
rw: bufio.NewReadWriter(bufio.NewReader(nc), bufio.NewWriter(nc)),
|
||||
c: c,
|
||||
}
|
||||
cn.extendDeadline()
|
||||
return cn, nil
|
||||
}
|
||||
|
||||
func (c *Client) onItem(item *Item, fn func(*Client, *bufio.ReadWriter, *Item) error) error {
|
||||
addr, err := c.selector.PickServer(item.Key)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
cn, err := c.getConn(addr)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer cn.condRelease(&err)
|
||||
if err = fn(c, cn.rw, item); err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (c *Client) FlushAll() error {
|
||||
return c.selector.Each(c.flushAllFromAddr)
|
||||
}
|
||||
|
||||
// Get gets the item for the given key. ErrCacheMiss is returned for a
|
||||
// memcache cache miss. The key must be at most 250 bytes in length.
|
||||
func (c *Client) Get(key string) (item *Item, err error) {
|
||||
err = c.withKeyAddr(key, func(addr net.Addr) error {
|
||||
return c.getFromAddr(addr, []string{key}, func(it *Item) { item = it })
|
||||
})
|
||||
if err == nil && item == nil {
|
||||
err = ErrCacheMiss
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
// Touch updates the expiry for the given key. The seconds parameter is either
|
||||
// a Unix timestamp or, if seconds is less than 1 month, the number of seconds
|
||||
// into the future at which time the item will expire. Zero means the item has
|
||||
// no expiration time. ErrCacheMiss is returned if the key is not in the cache.
|
||||
// The key must be at most 250 bytes in length.
|
||||
func (c *Client) Touch(key string, seconds int32) (err error) {
|
||||
return c.withKeyAddr(key, func(addr net.Addr) error {
|
||||
return c.touchFromAddr(addr, []string{key}, seconds)
|
||||
})
|
||||
}
|
||||
|
||||
func (c *Client) withKeyAddr(key string, fn func(net.Addr) error) (err error) {
|
||||
if !legalKey(key) {
|
||||
return ErrMalformedKey
|
||||
}
|
||||
addr, err := c.selector.PickServer(key)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return fn(addr)
|
||||
}
|
||||
|
||||
func (c *Client) withAddrRw(addr net.Addr, fn func(*bufio.ReadWriter) error) (err error) {
|
||||
cn, err := c.getConn(addr)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer cn.condRelease(&err)
|
||||
return fn(cn.rw)
|
||||
}
|
||||
|
||||
func (c *Client) withKeyRw(key string, fn func(*bufio.ReadWriter) error) error {
|
||||
return c.withKeyAddr(key, func(addr net.Addr) error {
|
||||
return c.withAddrRw(addr, fn)
|
||||
})
|
||||
}
|
||||
|
||||
func (c *Client) getFromAddr(addr net.Addr, keys []string, cb func(*Item)) error {
|
||||
return c.withAddrRw(addr, func(rw *bufio.ReadWriter) error {
|
||||
if _, err := fmt.Fprintf(rw, "gets %s\r\n", strings.Join(keys, " ")); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := rw.Flush(); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := parseGetResponse(rw.Reader, cb); err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
})
|
||||
}
|
||||
|
||||
// flushAllFromAddr send the flush_all command to the given addr
|
||||
func (c *Client) flushAllFromAddr(addr net.Addr) error {
|
||||
return c.withAddrRw(addr, func(rw *bufio.ReadWriter) error {
|
||||
if _, err := fmt.Fprintf(rw, "flush_all\r\n"); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := rw.Flush(); err != nil {
|
||||
return err
|
||||
}
|
||||
line, err := rw.ReadSlice('\n')
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
switch {
|
||||
case bytes.Equal(line, resultOk):
|
||||
break
|
||||
default:
|
||||
return fmt.Errorf("memcache: unexpected response line from flush_all: %q", string(line))
|
||||
}
|
||||
return nil
|
||||
})
|
||||
}
|
||||
|
||||
func (c *Client) touchFromAddr(addr net.Addr, keys []string, expiration int32) error {
|
||||
return c.withAddrRw(addr, func(rw *bufio.ReadWriter) error {
|
||||
for _, key := range keys {
|
||||
if _, err := fmt.Fprintf(rw, "touch %s %d\r\n", key, expiration); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := rw.Flush(); err != nil {
|
||||
return err
|
||||
}
|
||||
line, err := rw.ReadSlice('\n')
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
switch {
|
||||
case bytes.Equal(line, resultTouched):
|
||||
break
|
||||
case bytes.Equal(line, resultNotFound):
|
||||
return ErrCacheMiss
|
||||
default:
|
||||
return fmt.Errorf("memcache: unexpected response line from touch: %q", string(line))
|
||||
}
|
||||
}
|
||||
return nil
|
||||
})
|
||||
}
|
||||
|
||||
// GetMulti is a batch version of Get. The returned map from keys to
|
||||
// items may have fewer elements than the input slice, due to memcache
|
||||
// cache misses. Each key must be at most 250 bytes in length.
|
||||
// If no error is returned, the returned map will also be non-nil.
|
||||
func (c *Client) GetMulti(keys []string) (map[string]*Item, error) {
|
||||
var lk sync.Mutex
|
||||
m := make(map[string]*Item)
|
||||
addItemToMap := func(it *Item) {
|
||||
lk.Lock()
|
||||
defer lk.Unlock()
|
||||
m[it.Key] = it
|
||||
}
|
||||
|
||||
keyMap := make(map[net.Addr][]string)
|
||||
for _, key := range keys {
|
||||
if !legalKey(key) {
|
||||
return nil, ErrMalformedKey
|
||||
}
|
||||
addr, err := c.selector.PickServer(key)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
keyMap[addr] = append(keyMap[addr], key)
|
||||
}
|
||||
|
||||
ch := make(chan error, buffered)
|
||||
for addr, keys := range keyMap {
|
||||
go func(addr net.Addr, keys []string) {
|
||||
ch <- c.getFromAddr(addr, keys, addItemToMap)
|
||||
}(addr, keys)
|
||||
}
|
||||
|
||||
var err error
|
||||
for _ = range keyMap {
|
||||
if ge := <-ch; ge != nil {
|
||||
err = ge
|
||||
}
|
||||
}
|
||||
return m, err
|
||||
}
|
||||
|
||||
// parseGetResponse reads a GET response from r and calls cb for each
|
||||
// read and allocated Item
|
||||
func parseGetResponse(r *bufio.Reader, cb func(*Item)) error {
|
||||
for {
|
||||
line, err := r.ReadSlice('\n')
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if bytes.Equal(line, resultEnd) {
|
||||
return nil
|
||||
}
|
||||
it := new(Item)
|
||||
size, err := scanGetResponseLine(line, it)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
it.Value = make([]byte, size+2)
|
||||
_, err = io.ReadFull(r, it.Value)
|
||||
if err != nil {
|
||||
it.Value = nil
|
||||
return err
|
||||
}
|
||||
if !bytes.HasSuffix(it.Value, crlf) {
|
||||
it.Value = nil
|
||||
return fmt.Errorf("memcache: corrupt get result read")
|
||||
}
|
||||
it.Value = it.Value[:size]
|
||||
cb(it)
|
||||
}
|
||||
}
|
||||
|
||||
// scanGetResponseLine populates it and returns the declared size of the item.
|
||||
// It does not read the bytes of the item.
|
||||
func scanGetResponseLine(line []byte, it *Item) (size int, err error) {
|
||||
pattern := "VALUE %s %d %d %d\r\n"
|
||||
dest := []interface{}{&it.Key, &it.Flags, &size, &it.casid}
|
||||
if bytes.Count(line, space) == 3 {
|
||||
pattern = "VALUE %s %d %d\r\n"
|
||||
dest = dest[:3]
|
||||
}
|
||||
n, err := fmt.Sscanf(string(line), pattern, dest...)
|
||||
if err != nil || n != len(dest) {
|
||||
return -1, fmt.Errorf("memcache: unexpected line in get response: %q", line)
|
||||
}
|
||||
return size, nil
|
||||
}
|
||||
|
||||
// Set writes the given item, unconditionally.
|
||||
func (c *Client) Set(item *Item) error {
|
||||
return c.onItem(item, (*Client).set)
|
||||
}
|
||||
|
||||
func (c *Client) set(rw *bufio.ReadWriter, item *Item) error {
|
||||
return c.populateOne(rw, "set", item)
|
||||
}
|
||||
|
||||
// Add writes the given item, if no value already exists for its
|
||||
// key. ErrNotStored is returned if that condition is not met.
|
||||
func (c *Client) Add(item *Item) error {
|
||||
return c.onItem(item, (*Client).add)
|
||||
}
|
||||
|
||||
func (c *Client) add(rw *bufio.ReadWriter, item *Item) error {
|
||||
return c.populateOne(rw, "add", item)
|
||||
}
|
||||
|
||||
// Replace writes the given item, but only if the server *does*
|
||||
// already hold data for this key
|
||||
func (c *Client) Replace(item *Item) error {
|
||||
return c.onItem(item, (*Client).replace)
|
||||
}
|
||||
|
||||
func (c *Client) replace(rw *bufio.ReadWriter, item *Item) error {
|
||||
return c.populateOne(rw, "replace", item)
|
||||
}
|
||||
|
||||
// CompareAndSwap writes the given item that was previously returned
|
||||
// by Get, if the value was neither modified or evicted between the
|
||||
// Get and the CompareAndSwap calls. The item's Key should not change
|
||||
// between calls but all other item fields may differ. ErrCASConflict
|
||||
// is returned if the value was modified in between the
|
||||
// calls. ErrNotStored is returned if the value was evicted in between
|
||||
// the calls.
|
||||
func (c *Client) CompareAndSwap(item *Item) error {
|
||||
return c.onItem(item, (*Client).cas)
|
||||
}
|
||||
|
||||
func (c *Client) cas(rw *bufio.ReadWriter, item *Item) error {
|
||||
return c.populateOne(rw, "cas", item)
|
||||
}
|
||||
|
||||
func (c *Client) populateOne(rw *bufio.ReadWriter, verb string, item *Item) error {
|
||||
if !legalKey(item.Key) {
|
||||
return ErrMalformedKey
|
||||
}
|
||||
var err error
|
||||
if verb == "cas" {
|
||||
_, err = fmt.Fprintf(rw, "%s %s %d %d %d %d\r\n",
|
||||
verb, item.Key, item.Flags, item.Expiration, len(item.Value), item.casid)
|
||||
} else {
|
||||
_, err = fmt.Fprintf(rw, "%s %s %d %d %d\r\n",
|
||||
verb, item.Key, item.Flags, item.Expiration, len(item.Value))
|
||||
}
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if _, err = rw.Write(item.Value); err != nil {
|
||||
return err
|
||||
}
|
||||
if _, err := rw.Write(crlf); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := rw.Flush(); err != nil {
|
||||
return err
|
||||
}
|
||||
line, err := rw.ReadSlice('\n')
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
switch {
|
||||
case bytes.Equal(line, resultStored):
|
||||
return nil
|
||||
case bytes.Equal(line, resultNotStored):
|
||||
return ErrNotStored
|
||||
case bytes.Equal(line, resultExists):
|
||||
return ErrCASConflict
|
||||
case bytes.Equal(line, resultNotFound):
|
||||
return ErrCacheMiss
|
||||
}
|
||||
return fmt.Errorf("memcache: unexpected response line from %q: %q", verb, string(line))
|
||||
}
|
||||
|
||||
func writeReadLine(rw *bufio.ReadWriter, format string, args ...interface{}) ([]byte, error) {
|
||||
_, err := fmt.Fprintf(rw, format, args...)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
if err := rw.Flush(); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
line, err := rw.ReadSlice('\n')
|
||||
return line, err
|
||||
}
|
||||
|
||||
func writeExpectf(rw *bufio.ReadWriter, expect []byte, format string, args ...interface{}) error {
|
||||
line, err := writeReadLine(rw, format, args...)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
switch {
|
||||
case bytes.Equal(line, resultOK):
|
||||
return nil
|
||||
case bytes.Equal(line, expect):
|
||||
return nil
|
||||
case bytes.Equal(line, resultNotStored):
|
||||
return ErrNotStored
|
||||
case bytes.Equal(line, resultExists):
|
||||
return ErrCASConflict
|
||||
case bytes.Equal(line, resultNotFound):
|
||||
return ErrCacheMiss
|
||||
}
|
||||
return fmt.Errorf("memcache: unexpected response line: %q", string(line))
|
||||
}
|
||||
|
||||
// Delete deletes the item with the provided key. The error ErrCacheMiss is
|
||||
// returned if the item didn't already exist in the cache.
|
||||
func (c *Client) Delete(key string) error {
|
||||
return c.withKeyRw(key, func(rw *bufio.ReadWriter) error {
|
||||
return writeExpectf(rw, resultDeleted, "delete %s\r\n", key)
|
||||
})
|
||||
}
|
||||
|
||||
// DeleteAll deletes all items in the cache.
|
||||
func (c *Client) DeleteAll() error {
|
||||
return c.withKeyRw("", func(rw *bufio.ReadWriter) error {
|
||||
return writeExpectf(rw, resultDeleted, "flush_all\r\n")
|
||||
})
|
||||
}
|
||||
|
||||
// Increment atomically increments key by delta. The return value is
|
||||
// the new value after being incremented or an error. If the value
|
||||
// didn't exist in memcached the error is ErrCacheMiss. The value in
|
||||
// memcached must be an decimal number, or an error will be returned.
|
||||
// On 64-bit overflow, the new value wraps around.
|
||||
func (c *Client) Increment(key string, delta uint64) (newValue uint64, err error) {
|
||||
return c.incrDecr("incr", key, delta)
|
||||
}
|
||||
|
||||
// Decrement atomically decrements key by delta. The return value is
|
||||
// the new value after being decremented or an error. If the value
|
||||
// didn't exist in memcached the error is ErrCacheMiss. The value in
|
||||
// memcached must be an decimal number, or an error will be returned.
|
||||
// On underflow, the new value is capped at zero and does not wrap
|
||||
// around.
|
||||
func (c *Client) Decrement(key string, delta uint64) (newValue uint64, err error) {
|
||||
return c.incrDecr("decr", key, delta)
|
||||
}
|
||||
|
||||
func (c *Client) incrDecr(verb, key string, delta uint64) (uint64, error) {
|
||||
var val uint64
|
||||
err := c.withKeyRw(key, func(rw *bufio.ReadWriter) error {
|
||||
line, err := writeReadLine(rw, "%s %s %d\r\n", verb, key, delta)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
switch {
|
||||
case bytes.Equal(line, resultNotFound):
|
||||
return ErrCacheMiss
|
||||
case bytes.HasPrefix(line, resultClientErrorPrefix):
|
||||
errMsg := line[len(resultClientErrorPrefix) : len(line)-2]
|
||||
return errors.New("memcache: client error: " + string(errMsg))
|
||||
}
|
||||
val, err = strconv.ParseUint(string(line[:len(line)-2]), 10, 64)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
})
|
||||
return val, err
|
||||
}
|
||||
129
vendor/github.com/bradfitz/gomemcache/memcache/selector.go
generated
vendored
129
vendor/github.com/bradfitz/gomemcache/memcache/selector.go
generated
vendored
@@ -1,129 +0,0 @@
|
||||
/*
|
||||
Copyright 2011 Google Inc.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
*/
|
||||
|
||||
package memcache
|
||||
|
||||
import (
|
||||
"hash/crc32"
|
||||
"net"
|
||||
"strings"
|
||||
"sync"
|
||||
)
|
||||
|
||||
// ServerSelector is the interface that selects a memcache server
|
||||
// as a function of the item's key.
|
||||
//
|
||||
// All ServerSelector implementations must be safe for concurrent use
|
||||
// by multiple goroutines.
|
||||
type ServerSelector interface {
|
||||
// PickServer returns the server address that a given item
|
||||
// should be shared onto.
|
||||
PickServer(key string) (net.Addr, error)
|
||||
Each(func(net.Addr) error) error
|
||||
}
|
||||
|
||||
// ServerList is a simple ServerSelector. Its zero value is usable.
|
||||
type ServerList struct {
|
||||
mu sync.RWMutex
|
||||
addrs []net.Addr
|
||||
}
|
||||
|
||||
// staticAddr caches the Network() and String() values from any net.Addr.
|
||||
type staticAddr struct {
|
||||
ntw, str string
|
||||
}
|
||||
|
||||
func newStaticAddr(a net.Addr) net.Addr {
|
||||
return &staticAddr{
|
||||
ntw: a.Network(),
|
||||
str: a.String(),
|
||||
}
|
||||
}
|
||||
|
||||
func (s *staticAddr) Network() string { return s.ntw }
|
||||
func (s *staticAddr) String() string { return s.str }
|
||||
|
||||
// SetServers changes a ServerList's set of servers at runtime and is
|
||||
// safe for concurrent use by multiple goroutines.
|
||||
//
|
||||
// Each server is given equal weight. A server is given more weight
|
||||
// if it's listed multiple times.
|
||||
//
|
||||
// SetServers returns an error if any of the server names fail to
|
||||
// resolve. No attempt is made to connect to the server. If any error
|
||||
// is returned, no changes are made to the ServerList.
|
||||
func (ss *ServerList) SetServers(servers ...string) error {
|
||||
naddr := make([]net.Addr, len(servers))
|
||||
for i, server := range servers {
|
||||
if strings.Contains(server, "/") {
|
||||
addr, err := net.ResolveUnixAddr("unix", server)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
naddr[i] = newStaticAddr(addr)
|
||||
} else {
|
||||
tcpaddr, err := net.ResolveTCPAddr("tcp", server)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
naddr[i] = newStaticAddr(tcpaddr)
|
||||
}
|
||||
}
|
||||
|
||||
ss.mu.Lock()
|
||||
defer ss.mu.Unlock()
|
||||
ss.addrs = naddr
|
||||
return nil
|
||||
}
|
||||
|
||||
// Each iterates over each server calling the given function
|
||||
func (ss *ServerList) Each(f func(net.Addr) error) error {
|
||||
ss.mu.RLock()
|
||||
defer ss.mu.RUnlock()
|
||||
for _, a := range ss.addrs {
|
||||
if err := f(a); nil != err {
|
||||
return err
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// keyBufPool returns []byte buffers for use by PickServer's call to
|
||||
// crc32.ChecksumIEEE to avoid allocations. (but doesn't avoid the
|
||||
// copies, which at least are bounded in size and small)
|
||||
var keyBufPool = sync.Pool{
|
||||
New: func() interface{} {
|
||||
b := make([]byte, 256)
|
||||
return &b
|
||||
},
|
||||
}
|
||||
|
||||
func (ss *ServerList) PickServer(key string) (net.Addr, error) {
|
||||
ss.mu.RLock()
|
||||
defer ss.mu.RUnlock()
|
||||
if len(ss.addrs) == 0 {
|
||||
return nil, ErrNoServers
|
||||
}
|
||||
if len(ss.addrs) == 1 {
|
||||
return ss.addrs[0], nil
|
||||
}
|
||||
bufp := keyBufPool.Get().(*[]byte)
|
||||
n := copy(*bufp, key)
|
||||
cs := crc32.ChecksumIEEE((*bufp)[:n])
|
||||
keyBufPool.Put(bufp)
|
||||
|
||||
return ss.addrs[cs%uint32(len(ss.addrs))], nil
|
||||
}
|
||||
27
vendor/github.com/casbin/casbin/.gitignore
generated
vendored
27
vendor/github.com/casbin/casbin/.gitignore
generated
vendored
@@ -1,27 +0,0 @@
|
||||
# Compiled Object files, Static and Dynamic libs (Shared Objects)
|
||||
*.o
|
||||
*.a
|
||||
*.so
|
||||
|
||||
# Folders
|
||||
_obj
|
||||
_test
|
||||
|
||||
# Architecture specific extensions/prefixes
|
||||
*.[568vq]
|
||||
[568vq].out
|
||||
|
||||
*.cgo1.go
|
||||
*.cgo2.c
|
||||
_cgo_defun.c
|
||||
_cgo_gotypes.go
|
||||
_cgo_export.*
|
||||
|
||||
_testmain.go
|
||||
|
||||
*.exe
|
||||
*.test
|
||||
*.prof
|
||||
|
||||
.idea/
|
||||
*.iml
|
||||
12
vendor/github.com/casbin/casbin/.travis.yml
generated
vendored
12
vendor/github.com/casbin/casbin/.travis.yml
generated
vendored
@@ -1,12 +0,0 @@
|
||||
language: go
|
||||
|
||||
sudo: false
|
||||
|
||||
go:
|
||||
- tip
|
||||
|
||||
before_install:
|
||||
- go get github.com/mattn/goveralls
|
||||
|
||||
script:
|
||||
- $HOME/gopath/bin/goveralls -service=travis-ci
|
||||
201
vendor/github.com/casbin/casbin/LICENSE
generated
vendored
201
vendor/github.com/casbin/casbin/LICENSE
generated
vendored
@@ -1,201 +0,0 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "{}"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright {yyyy} {name of copyright owner}
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
366
vendor/github.com/casbin/casbin/README.md
generated
vendored
366
vendor/github.com/casbin/casbin/README.md
generated
vendored
@@ -1,366 +0,0 @@
|
||||
Casbin
|
||||
====
|
||||
|
||||
[](https://goreportcard.com/report/github.com/casbin/casbin)
|
||||
[](https://travis-ci.org/casbin/casbin)
|
||||
[](https://coveralls.io/github/casbin/casbin?branch=master)
|
||||
[](https://godoc.org/github.com/casbin/casbin)
|
||||
[](https://github.com/casbin/casbin/releases/latest)
|
||||
[](https://gitter.im/casbin/lobby)
|
||||
[](http://www.patreon.com/yangluo)
|
||||
[](https://sourcegraph.com/github.com/casbin/casbin?badge)
|
||||
|
||||
**News**: still worry about how to write the correct Casbin policy? ``Casbin online editor`` is coming to help! Try it at: http://casbin.org/editor/
|
||||
|
||||

|
||||
|
||||
Casbin is a powerful and efficient open-source access control library for Golang projects. It provides support for enforcing authorization based on various [access control models](https://en.wikipedia.org/wiki/Computer_security_model).
|
||||
|
||||
## All the languages supported by Casbin:
|
||||
|
||||
- Golang: [Casbin](https://github.com/casbin/casbin) (production-ready)
|
||||
- Java: [jCasbin](https://github.com/casbin/jcasbin) (production-ready)
|
||||
- PHP: [PHP-Casbin](https://github.com/sstutz/php-casbin) (experimental)
|
||||
- Node.js: [node-casbin](https://github.com/casbin/node-casbin) (WIP)
|
||||
- C++: xCasbin (WIP)
|
||||
|
||||
## Table of contents
|
||||
|
||||
- [Supported models](#supported-models)
|
||||
- [How it works?](#how-it-works)
|
||||
- [Features](#features)
|
||||
- [Installation](#installation)
|
||||
- [Documentation](#documentation)
|
||||
- [Online editor](#online-editor)
|
||||
- [Tutorials](#tutorials)
|
||||
- [Get started](#get-started)
|
||||
- [Policy management](#policy-management)
|
||||
- [Policy persistence](#policy-persistence)
|
||||
- [Policy consistence between multiple nodes](#policy-consistence-between-multiple-nodes)
|
||||
- [Role manager](#role-manager)
|
||||
- [Multi-threading](#multi-threading)
|
||||
- [Benchmarks](#benchmarks)
|
||||
- [Examples](#examples)
|
||||
- [How to use Casbin as a service?](#how-to-use-casbin-as-a-service)
|
||||
- [Our adopters](#our-adopters)
|
||||
|
||||
## Supported models
|
||||
|
||||
1. [**ACL (Access Control List)**](https://en.wikipedia.org/wiki/Access_control_list)
|
||||
2. **ACL with [superuser](https://en.wikipedia.org/wiki/Superuser)**
|
||||
3. **ACL without users**: especially useful for systems that don't have authentication or user log-ins.
|
||||
3. **ACL without resources**: some scenarios may target for a type of resources instead of an individual resource by using permissions like ``write-article``, ``read-log``. It doesn't control the access to a specific article or log.
|
||||
4. **[RBAC (Role-Based Access Control)](https://en.wikipedia.org/wiki/Role-based_access_control)**
|
||||
5. **RBAC with resource roles**: both users and resources can have roles (or groups) at the same time.
|
||||
6. **RBAC with domains/tenants**: users can have different role sets for different domains/tenants.
|
||||
7. **[ABAC (Attribute-Based Access Control)](https://en.wikipedia.org/wiki/Attribute-Based_Access_Control)**: syntax sugar like ``resource.Owner`` can be used to get the attribute for a resource.
|
||||
8. **[RESTful](https://en.wikipedia.org/wiki/Representational_state_transfer)**: supports paths like ``/res/*``, ``/res/:id`` and HTTP methods like ``GET``, ``POST``, ``PUT``, ``DELETE``.
|
||||
9. **Deny-override**: both allow and deny authorizations are supported, deny overrides the allow.
|
||||
10. **Priority**: the policy rules can be prioritized like firewall rules.
|
||||
|
||||
## How it works?
|
||||
|
||||
In Casbin, an access control model is abstracted into a CONF file based on the **PERM metamodel (Policy, Effect, Request, Matchers)**. So switching or upgrading the authorization mechanism for a project is just as simple as modifying a configuration. You can customize your own access control model by combining the available models. For example, you can get RBAC roles and ABAC attributes together inside one model and share one set of policy rules.
|
||||
|
||||
The most basic and simplest model in Casbin is ACL. ACL's model CONF is:
|
||||
|
||||
```ini
|
||||
# Request definition
|
||||
[request_definition]
|
||||
r = sub, obj, act
|
||||
|
||||
# Policy definition
|
||||
[policy_definition]
|
||||
p = sub, obj, act
|
||||
|
||||
# Policy effect
|
||||
[policy_effect]
|
||||
e = some(where (p.eft == allow))
|
||||
|
||||
# Matchers
|
||||
[matchers]
|
||||
m = r.sub == p.sub && r.obj == p.obj && r.act == p.act
|
||||
|
||||
# We also support multi-line mode by appending '\' in the end:
|
||||
# m = r.sub == p.sub && r.obj == p.obj \
|
||||
# && r.act == p.act
|
||||
```
|
||||
|
||||
An example policy for ACL model is like:
|
||||
|
||||
```
|
||||
p, alice, data1, read
|
||||
p, bob, data2, write
|
||||
```
|
||||
|
||||
It means:
|
||||
|
||||
- alice can read data1
|
||||
- bob can write data2
|
||||
|
||||
## Features
|
||||
|
||||
What Casbin does:
|
||||
|
||||
1. enforce the policy in the classic ``{subject, object, action}`` form or a customized form as you defined, both allow and deny authorizations are supported.
|
||||
2. handle the storage of the access control model and its policy.
|
||||
3. manage the role-user mappings and role-role mappings (aka role hierarchy in RBAC).
|
||||
4. support built-in superuser like ``root`` or ``administrator``. A superuser can do anything without explict permissions.
|
||||
5. multiple built-in operators to support the rule matching. For example, ``keyMatch`` can map a resource key ``/foo/bar`` to the pattern ``/foo*``.
|
||||
|
||||
What Casbin does NOT do:
|
||||
|
||||
1. authentication (aka verify ``username`` and ``password`` when a user logs in)
|
||||
2. manage the list of users or roles. I believe it's more convenient for the project itself to manage these entities. Users usually have their passwords, and Casbin is not designed as a password container. However, Casbin stores the user-role mapping for the RBAC scenario.
|
||||
|
||||
## Installation
|
||||
|
||||
```
|
||||
go get github.com/casbin/casbin
|
||||
```
|
||||
|
||||
## Documentation
|
||||
|
||||
For documentation, please see: [Our Wiki](https://github.com/casbin/casbin/wiki)
|
||||
|
||||
## Online editor
|
||||
|
||||
You can also use the online editor (http://casbin.org/editor/) to write your Casbin model and policy in your web browser. It provides functionality such as ``syntax highlighting`` and ``code completion``, just like an IDE for a programming language.
|
||||
|
||||
## Tutorials
|
||||
|
||||
- [Basic Role-Based HTTP Authorization in Go with Casbin](https://zupzup.org/casbin-http-role-auth) (or [Chinese translation](https://studygolang.com/articles/12323))
|
||||
- [Policy enforcements on Kubernetes with Banzai Cloud's Pipeline and Casbin](https://banzaicloud.com/blog/policy-enforcement-k8s/)
|
||||
- [Using Casbin with Beego: 1. Get started and test (in Chinese)](https://blog.csdn.net/hotqin888/article/details/78460385)
|
||||
- [Using Casbin with Beego: 2. Policy storage (in Chinese)](https://blog.csdn.net/hotqin888/article/details/78571240)
|
||||
- [Using Casbin with Beego: 3. Policy query (in Chinese)](https://blog.csdn.net/hotqin888/article/details/78992250)
|
||||
- [Using Casbin with Beego: 4. Policy update (in Chinese)](https://blog.csdn.net/hotqin888/article/details/80032538)
|
||||
|
||||
## Get started
|
||||
|
||||
1. New a Casbin enforcer with a model file and a policy file:
|
||||
|
||||
```go
|
||||
e := casbin.NewEnforcer("path/to/model.conf", "path/to/policy.csv")
|
||||
```
|
||||
|
||||
Note: you can also initialize an enforcer with policy in DB instead of file, see [Persistence](#persistence) section for details.
|
||||
|
||||
2. Add an enforcement hook into your code right before the access happens:
|
||||
|
||||
```go
|
||||
sub := "alice" // the user that wants to access a resource.
|
||||
obj := "data1" // the resource that is going to be accessed.
|
||||
act := "read" // the operation that the user performs on the resource.
|
||||
|
||||
if e.Enforce(sub, obj, act) == true {
|
||||
// permit alice to read data1
|
||||
} else {
|
||||
// deny the request, show an error
|
||||
}
|
||||
```
|
||||
|
||||
3. Besides the static policy file, Casbin also provides API for permission management at run-time. For example, You can get all the roles assigned to a user as below:
|
||||
|
||||
```go
|
||||
roles := e.GetRoles("alice")
|
||||
```
|
||||
|
||||
See [Policy management APIs](#policy-management) for more usage.
|
||||
|
||||
4. Please refer to the ``_test.go`` files for more usage.
|
||||
|
||||
## Policy management
|
||||
|
||||
Casbin provides two sets of APIs to manage permissions:
|
||||
|
||||
- [Management API](https://github.com/casbin/casbin/blob/master/management_api.go): the primitive API that provides full support for Casbin policy management. See [here](https://github.com/casbin/casbin/blob/master/management_api_test.go) for examples.
|
||||
- [RBAC API](https://github.com/casbin/casbin/blob/master/rbac_api.go): a more friendly API for RBAC. This API is a subset of Management API. The RBAC users could use this API to simplify the code. See [here](https://github.com/casbin/casbin/blob/master/rbac_api_test.go) for examples.
|
||||
|
||||
We also provide a web-based UI for model management and policy management:
|
||||
|
||||
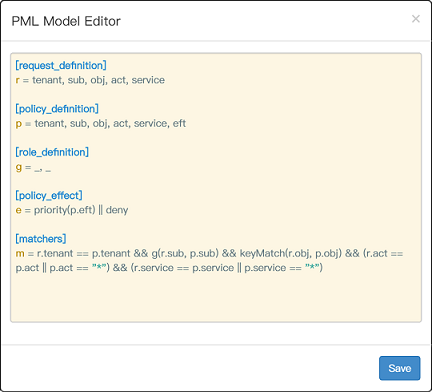
|
||||
|
||||
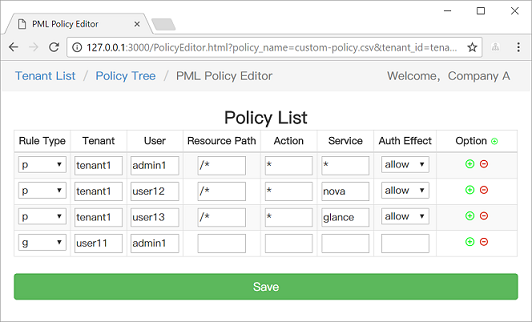
|
||||
|
||||
## Policy persistence
|
||||
|
||||
In Casbin, the policy storage is implemented as an adapter (aka middleware for Casbin). To keep light-weight, we don't put adapter code in the main library (except the default file adapter). A complete list of Casbin adapters is provided as below. Any 3rd-party contribution on a new adapter is welcomed, please inform us and I will put it in this list:)
|
||||
|
||||
Adapter | Type | Author | Description
|
||||
----|------|----|----
|
||||
[File Adapter (built-in)](https://github.com/casbin/casbin/wiki/Policy-persistence#file-adapter) | File | Casbin | Persistence for [.CSV (Comma-Separated Values)](https://en.wikipedia.org/wiki/Comma-separated_values) files
|
||||
[Filtered File Adapter (built-in)](https://github.com/casbin/casbin#policy-enforcement-at-scale) | File | [@faceless-saint](https://github.com/faceless-saint) | Persistence for [.CSV (Comma-Separated Values)](https://en.wikipedia.org/wiki/Comma-separated_values) files with policy subset loading support
|
||||
[Xorm Adapter](https://github.com/casbin/xorm-adapter) | ORM | Casbin | MySQL, PostgreSQL, TiDB, SQLite, SQL Server, Oracle are supported by [Xorm](https://github.com/go-xorm/xorm/)
|
||||
[Gorm Adapter](https://github.com/casbin/gorm-adapter) | ORM | Casbin | MySQL, PostgreSQL, Sqlite3, SQL Server are supported by [Gorm](https://github.com/jinzhu/gorm/)
|
||||
[Beego ORM Adapter](https://github.com/casbin/beego-orm-adapter) | ORM | Casbin | MySQL, PostgreSQL, Sqlite3 are supported by [Beego ORM](https://beego.me/docs/mvc/model/overview.md)
|
||||
[MongoDB Adapter](https://github.com/casbin/mongodb-adapter) | NoSQL | Casbin | Persistence for [MongoDB](https://www.mongodb.com)
|
||||
[Cassandra Adapter](https://github.com/casbin/cassandra-adapter) | NoSQL | Casbin | Persistence for [Apache Cassandra DB](http://cassandra.apache.org)
|
||||
[Consul Adapter](https://github.com/ankitm123/consul-adapter) | KV store | [@ankitm123](https://github.com/ankitm123) | Persistence for [HashiCorp Consul](https://www.consul.io/)
|
||||
[Redis Adapter](https://github.com/casbin/redis-adapter) | KV store | Casbin | Persistence for [Redis](https://redis.io/)
|
||||
[Protobuf Adapter](https://github.com/casbin/protobuf-adapter) | Stream | Casbin | Persistence for [Google Protocol Buffers](https://developers.google.com/protocol-buffers/)
|
||||
[JSON Adapter](https://github.com/casbin/json-adapter) | String | Casbin | Persistence for [JSON](https://www.json.org/)
|
||||
[String Adapter](https://github.com/qiangmzsx/string-adapter) | String | [@qiangmzsx](https://github.com/qiangmzsx) | Persistence for String
|
||||
[RQLite Adapter](https://github.com/edomosystems/rqlite-adapter) | SQL | [EDOMO Systems](https://github.com/edomosystems) | Persistence for [RQLite](https://github.com/rqlite/rqlite/)
|
||||
[PostgreSQL Adapter](https://github.com/going/casbin-postgres-adapter) | SQL | [Going](https://github.com/going) | Persistence for [PostgreSQL](https://www.postgresql.org/)
|
||||
[RethinkDB Adapter](https://github.com/adityapandey9/rethinkdb-adapter) | NoSQL | [@adityapandey9](https://github.com/adityapandey9) | Persistence for [RethinkDB](https://rethinkdb.com/)
|
||||
[DynamoDB Adapter](https://github.com/HOOQTV/dynacasbin) | NoSQL | [HOOQ](https://github.com/HOOQTV) | Persistence for [Amazon DynamoDB](https://aws.amazon.com/dynamodb/)
|
||||
[Minio/AWS S3 Adapter](https://github.com/Soluto/casbin-minio-adapter) | Object storage | [Soluto](https://github.com/Soluto) | Persistence for [Minio](https://github.com/minio/minio) and [Amazon S3](https://aws.amazon.com/s3/)
|
||||
[Bolt Adapter](https://github.com/wirepair/bolt-adapter) | KV store | [@wirepair](https://github.com/wirepair) | Persistence for [Bolt](https://github.com/boltdb/bolt)
|
||||
|
||||
For details of adapters, please refer to the documentation: https://github.com/casbin/casbin/wiki/Policy-persistence
|
||||
|
||||
## Policy enforcement at scale
|
||||
|
||||
Some adapters support filtered policy management. This means that the policy loaded by Casbin is a subset of the policy in storage based on a given filter. This allows for efficient policy enforcement in large, multi-tenant environments when parsing the entire policy becomes a performance bottleneck.
|
||||
|
||||
To use filtered policies with a supported adapter, simply call the `LoadFilteredPolicy` method. The valid format for the filter parameter depends on the adapter used. To prevent accidental data loss, the `SavePolicy` method is disabled when a filtered policy is loaded.
|
||||
|
||||
For example, the following code snippet uses the built-in filtered file adapter and the RBAC model with domains. In this case, the filter limits the policy to a single domain. Any policy lines for domains other than `"domain1"` are omitted from the loaded policy:
|
||||
|
||||
```go
|
||||
import (
|
||||
"github.com/casbin/casbin"
|
||||
)
|
||||
|
||||
enforcer := casbin.NewEnforcer()
|
||||
|
||||
adapter := fileadapter.NewFilteredAdapter("examples/rbac_with_domains_policy.csv")
|
||||
enforcer.InitWithAdapter("examples/rbac_with_domains_model.conf", adapter)
|
||||
|
||||
filter := &fileadapter.Filter{
|
||||
P: []string{"", "domain1"},
|
||||
G: []string{"", "", "domain1"},
|
||||
}
|
||||
enforcer.LoadFilteredPolicy(filter)
|
||||
|
||||
// The loaded policy now only contains the entries pertaining to "domain1".
|
||||
```
|
||||
|
||||
## Policy consistence between multiple nodes
|
||||
|
||||
We support to use distributed messaging systems like [etcd](https://github.com/coreos/etcd) to keep consistence between multiple Casbin enforcer instances. So our users can concurrently use multiple Casbin enforcers to handle large number of permission checking requests.
|
||||
|
||||
Similar to policy storage adapters, we don't put watcher code in the main library. Any support for a new messaging system should be implemented as a watcher. A complete list of Casbin watchers is provided as below. Any 3rd-party contribution on a new watcher is welcomed, please inform us and I will put it in this list:)
|
||||
|
||||
Watcher | Type | Author | Description
|
||||
----|------|----|----
|
||||
[Etcd Watcher](https://github.com/casbin/etcd-watcher) | KV store | Casbin | Watcher for [etcd](https://github.com/coreos/etcd)
|
||||
[NATS Watcher](https://github.com/Soluto/casbin-nats-watcher) | Messaging system | [Soluto](https://github.com/Soluto) | Watcher for [NATS](https://nats.io/)
|
||||
[ZooKeeper Watcher](https://github.com/grepsr/casbin-zk-watcher) | KV store | [Grepsr](https://github.com/grepsr) | Watcher for [Apache ZooKeeper](https://zookeeper.apache.org/)
|
||||
[Redis Watcher](https://github.com/billcobbler/casbin-redis-watcher) | KV store | [@billcobbler](https://github.com/billcobbler) | Watcher for [Redis](http://redis.io/)
|
||||
|
||||
## Role manager
|
||||
|
||||
The role manager is used to manage the RBAC role hierarchy (user-role mapping) in Casbin. A role manager can retrieve the role data from Casbin policy rules or external sources such as LDAP, Okta, Auth0, Azure AD, etc. We support different implementations of a role manager. To keep light-weight, we don't put role manager code in the main library (except the default role manager). A complete list of Casbin role managers is provided as below. Any 3rd-party contribution on a new role manager is welcomed, please inform us and I will put it in this list:)
|
||||
|
||||
Role manager | Author | Description
|
||||
----|----|----
|
||||
[Default Role Manager (built-in)](https://github.com/casbin/casbin/blob/master/rbac/default-role-manager/role_manager.go) | Casbin | Supports role hierarchy stored in Casbin policy
|
||||
[Session Role Manager](https://github.com/casbin/session-role-manager) | [EDOMO Systems](https://github.com/edomosystems) | Supports role hierarchy stored in Casbin policy, with time-range-based sessions
|
||||
[Okta Role Manager](https://github.com/casbin/okta-role-manager) | Casbin | Supports role hierarchy stored in [Okta](https://www.okta.com/)
|
||||
[Auth0 Role Manager](https://github.com/casbin/auth0-role-manager) | Casbin | Supports role hierarchy stored in [Auth0](https://auth0.com/)'s [Authorization Extension](https://auth0.com/docs/extensions/authorization-extension/v2)
|
||||
|
||||
For developers: all role managers must implement the [RoleManager](https://github.com/casbin/casbin/blob/master/rbac/role_manager.go) interface. [Session Role Manager](https://github.com/casbin/session-role-manager) can be used as a reference implementation.
|
||||
|
||||
## Multi-threading
|
||||
|
||||
If you use Casbin in a multi-threading manner, you can use the synchronized wrapper of the Casbin enforcer: https://github.com/casbin/casbin/blob/master/enforcer_synced.go.
|
||||
|
||||
It also supports the ``AutoLoad`` feature, which means the Casbin enforcer will automatically load the latest policy rules from DB if it has changed. Call ``StartAutoLoadPolicy()`` to start automatically loading policy periodically and call ``StopAutoLoadPolicy()`` to stop it.
|
||||
|
||||
## Benchmarks
|
||||
|
||||
The overhead of policy enforcement is benchmarked in [model_b_test.go](https://github.com/casbin/casbin/blob/master/model_b_test.go). The testbed is:
|
||||
|
||||
```
|
||||
Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz, 2601 Mhz, 4 Core(s), 8 Logical Processor(s)
|
||||
```
|
||||
|
||||
The benchmarking result of ``go test -bench=. -benchmem`` is as follows (op = an ``Enforce()`` call, ms = millisecond, KB = kilo bytes):
|
||||
|
||||
Test case | Size | Time overhead | Memory overhead
|
||||
----|------|------|----
|
||||
ACL | 2 rules (2 users) | 0.015493 ms/op | 5.649 KB
|
||||
RBAC | 5 rules (2 users, 1 role) | 0.021738 ms/op | 7.522 KB
|
||||
RBAC (small) | 1100 rules (1000 users, 100 roles) | 0.164309 ms/op | 80.620 KB
|
||||
RBAC (medium) | 11000 rules (10000 users, 1000 roles) | 2.258262 ms/op | 765.152 KB
|
||||
RBAC (large) | 110000 rules (100000 users, 10000 roles) | 23.916776 ms/op | 7.606 MB
|
||||
RBAC with resource roles | 6 rules (2 users, 2 roles) | 0.021146 ms/op | 7.906 KB
|
||||
RBAC with domains/tenants | 6 rules (2 users, 1 role, 2 domains) | 0.032696 ms/op | 10.755 KB
|
||||
ABAC | 0 rule (0 user) | 0.007510 ms/op | 2.328 KB
|
||||
RESTful | 5 rules (3 users) | 0.045398 ms/op | 91.774 KB
|
||||
Deny-override | 6 rules (2 users, 1 role) | 0.023281 ms/op | 8.370 KB
|
||||
Priority | 9 rules (2 users, 2 roles) | 0.016389 ms/op | 5.313 KB
|
||||
|
||||
## Examples
|
||||
|
||||
Model | Model file | Policy file
|
||||
----|------|----
|
||||
ACL | [basic_model.conf](https://github.com/casbin/casbin/blob/master/examples/basic_model.conf) | [basic_policy.csv](https://github.com/casbin/casbin/blob/master/examples/basic_policy.csv)
|
||||
ACL with superuser | [basic_model_with_root.conf](https://github.com/casbin/casbin/blob/master/examples/basic_with_root_model.conf) | [basic_policy.csv](https://github.com/casbin/casbin/blob/master/examples/basic_policy.csv)
|
||||
ACL without users | [basic_model_without_users.conf](https://github.com/casbin/casbin/blob/master/examples/basic_without_users_model.conf) | [basic_policy_without_users.csv](https://github.com/casbin/casbin/blob/master/examples/basic_without_users_policy.csv)
|
||||
ACL without resources | [basic_model_without_resources.conf](https://github.com/casbin/casbin/blob/master/examples/basic_without_resources_model.conf) | [basic_policy_without_resources.csv](https://github.com/casbin/casbin/blob/master/examples/basic_without_resources_policy.csv)
|
||||
RBAC | [rbac_model.conf](https://github.com/casbin/casbin/blob/master/examples/rbac_model.conf) | [rbac_policy.csv](https://github.com/casbin/casbin/blob/master/examples/rbac_policy.csv)
|
||||
RBAC with resource roles | [rbac_model_with_resource_roles.conf](https://github.com/casbin/casbin/blob/master/examples/rbac_with_resource_roles_model.conf) | [rbac_policy_with_resource_roles.csv](https://github.com/casbin/casbin/blob/master/examples/rbac_with_resource_roles_policy.csv)
|
||||
RBAC with domains/tenants | [rbac_model_with_domains.conf](https://github.com/casbin/casbin/blob/master/examples/rbac_with_domains_model.conf) | [rbac_policy_with_domains.csv](https://github.com/casbin/casbin/blob/master/examples/rbac_with_domains_policy.csv)
|
||||
ABAC | [abac_model.conf](https://github.com/casbin/casbin/blob/master/examples/abac_model.conf) | N/A
|
||||
RESTful | [keymatch_model.conf](https://github.com/casbin/casbin/blob/master/examples/keymatch_model.conf) | [keymatch_policy.csv](https://github.com/casbin/casbin/blob/master/examples/keymatch_policy.csv)
|
||||
Deny-override | [rbac_model_with_deny.conf](https://github.com/casbin/casbin/blob/master/examples/rbac_with_deny_model.conf) | [rbac_policy_with_deny.csv](https://github.com/casbin/casbin/blob/master/examples/rbac_with_deny_policy.csv)
|
||||
Priority | [priority_model.conf](https://github.com/casbin/casbin/blob/master/examples/priority_model.conf) | [priority_policy.csv](https://github.com/casbin/casbin/blob/master/examples/priority_policy.csv)
|
||||
|
||||
## How to use Casbin as a service?
|
||||
|
||||
- [Go-Simple-API-Gateway](https://github.com/Soontao/go-simple-api-gateway): A simple API gateway written by golang, supports for authentication and authorization
|
||||
- [Casbin Server](https://github.com/casbin/casbin-server): Casbin as a Service via RESTful, only exposed permission checking API
|
||||
- [middleware-acl](https://github.com/luk4z7/middleware-acl): RESTful access control middleware based on Casbin
|
||||
|
||||
## Our adopters
|
||||
|
||||
### Web frameworks
|
||||
|
||||
- [Beego](https://github.com/astaxie/beego): An open-source, high-performance web framework for Go, via built-in plugin: [plugins/authz](https://github.com/astaxie/beego/blob/master/plugins/authz)
|
||||
- [Caddy](https://github.com/mholt/caddy): Fast, cross-platform HTTP/2 web server with automatic HTTPS, via plugin: [caddy-authz](https://github.com/casbin/caddy-authz)
|
||||
- [Gin](https://github.com/gin-gonic/gin): A HTTP web framework featuring a Martini-like API with much better performance, via plugin: [authz](https://github.com/gin-contrib/authz)
|
||||
- [Revel](https://github.com/revel/revel): A high productivity, full-stack web framework for the Go language, via plugin: [auth/casbin](https://github.com/revel/modules/tree/master/auth/casbin)
|
||||
- [Echo](https://github.com/labstack/echo): High performance, minimalist Go web framework, via plugin: [echo-authz](https://github.com/labstack/echo-contrib/tree/master/casbin) (thanks to [@xqbumu](https://github.com/xqbumu))
|
||||
- [Iris](https://github.com/kataras/iris): The fastest web framework for Go in (THIS) Earth. HTTP/2 Ready-To-GO, via plugin: [casbin](https://github.com/iris-contrib/middleware/tree/master/casbin) (thanks to [@hiveminded](https://github.com/hiveminded))
|
||||
- [Negroni](https://github.com/urfave/negroni): Idiomatic HTTP Middleware for Golang, via plugin: [negroni-authz](https://github.com/casbin/negroni-authz)
|
||||
- [Tango](https://github.com/lunny/tango): Micro & pluggable web framework for Go, via plugin: [authz](https://github.com/tango-contrib/authz)
|
||||
- [Chi](https://github.com/pressly/chi): A lightweight, idiomatic and composable router for building HTTP services, via plugin: [chi-authz](https://github.com/casbin/chi-authz)
|
||||
- [Macaron](https://github.com/go-macaron/macaron): A high productive and modular web framework in Go, via plugin: [authz](https://github.com/go-macaron/authz)
|
||||
- [DotWeb](https://github.com/devfeel/dotweb): Simple and easy go web micro framework, via plugin: [authz](https://github.com/devfeel/middleware/tree/master/authz)
|
||||
- [Baa](https://github.com/go-baa/baa): An express Go web framework with routing, middleware, dependency injection and http context, via plugin: [authz](https://github.com/baa-middleware/authz)
|
||||
|
||||
### Others
|
||||
|
||||
- [Intel RMD](https://github.com/intel/rmd): Intel's resource management daemon, via direct integration, see: [model](https://github.com/intel/rmd/blob/master/etc/rmd/acl/url/model.conf), [policy rules](https://github.com/intel/rmd/blob/master/etc/rmd/acl/url/policy.csv)
|
||||
- [VMware Dispatch](https://github.com/vmware/dispatch): A framework for deploying and managing serverless style applications, via direct integration, see: [model (in code)](https://github.com/vmware/dispatch/blob/master/pkg/identity-manager/handlers.go#L46-L55), [policy rules (in code)](https://github.com/vmware/dispatch/blob/master/pkg/identity-manager/handlers_test.go#L35-L45)
|
||||
- [Banzai Pipeline](https://github.com/banzaicloud/pipeline): [Banzai Cloud](https://github.com/banzaicloud)'s RESTful API to provision or reuse managed Kubernetes clusters in the cloud, via direct integration, see: [model (in code)](https://github.com/banzaicloud/pipeline/blob/master/auth/authz.go#L15-L30), [policy rules (in code)](https://github.com/banzaicloud/pipeline/blob/master/auth/authz.go#L84-L93)
|
||||
- [Docker](https://github.com/docker/docker): The world's leading software container platform, via plugin: [casbin-authz-plugin](https://github.com/casbin/casbin-authz-plugin) ([recommended by Docker](https://docs.docker.com/engine/extend/legacy_plugins/#authorization-plugins))
|
||||
- [Gobis](https://github.com/orange-cloudfoundry/gobis): [Orange](https://github.com/orange-cloudfoundry)'s lightweight API Gateway written in go, via plugin: [casbin](https://github.com/orange-cloudfoundry/gobis-middlewares/tree/master/casbin), see [model (in code)](https://github.com/orange-cloudfoundry/gobis-middlewares/blob/master/casbin/model.go#L52-L65), [policy rules (from request)](https://github.com/orange-cloudfoundry/gobis-middlewares/blob/master/casbin/adapter.go#L46-L64)
|
||||
- [Skydive](https://github.com/skydive-project/skydive): An open source real-time network topology and protocols analyzer, via direct integration, see: [model (in code)](https://github.com/skydive-project/skydive/blob/master/config/config.go#L136-L140), [policy rules](https://github.com/skydive-project/skydive/blob/master/rbac/policy.csv)
|
||||
- [Zenpress](https://github.com/insionng/zenpress): A CMS system written in Golang, via direct integration, see: [model](https://github.com/insionng/zenpress/blob/master/content/config/rbac_model.conf), [policy rules (in Gorm)](https://github.com/insionng/zenpress/blob/master/model/user.go#L53-L77)
|
||||
- [Argo CD](https://github.com/argoproj/argo-cd): GitOps continuous delivery for Kubernetes, via direct integration, see: [model](https://github.com/argoproj/argo-cd/blob/master/util/rbac/model.conf), [policy rules](https://github.com/argoproj/argo-cd/blob/master/util/rbac/builtin-policy.csv)
|
||||
- [EngineerCMS](https://github.com/3xxx/EngineerCMS): A CMS to manage knowledge for engineers, via direct integration, see: [model](https://github.com/3xxx/EngineerCMS/blob/master/conf/rbac_model.conf), [policy rules (in SQLite)](https://github.com/3xxx/EngineerCMS/blob/master/database/engineer.db)
|
||||
- [Cyber Auth API](https://github.com/CyberlifeCN/cyber-auth-api): A Golang authentication API project, via direct integration, see: [model](https://github.com/CyberlifeCN/cyber-auth-api/blob/master/conf/authz_model.conf), [policy rules](https://github.com/CyberlifeCN/cyber-auth-api/blob/master/conf/authz_policy.csv)
|
||||
- [IRIS Community](https://github.com/irisnet/iris-community): Website for IRIS Community Activities, via direct integration, see: [model](https://github.com/irisnet/iris-community/blob/master/authz/authz_model.conf), [policy rules](https://github.com/irisnet/iris-community/blob/master/authz/authz_policy.csv)
|
||||
- [Metadata DB](https://github.com/Bnei-Baruch/mdb): BB archive metadata database, via direct integration, see: [model](https://github.com/Bnei-Baruch/mdb/blob/master/data/permissions_model.conf), [policy rules](https://github.com/Bnei-Baruch/mdb/blob/master/data/permissions_policy.csv)
|
||||
|
||||
## License
|
||||
|
||||
This project is licensed under the [Apache 2.0 license](https://github.com/casbin/casbin/blob/master/LICENSE).
|
||||
|
||||
## Contact
|
||||
|
||||
If you have any issues or feature requests, please contact us. PR is welcomed.
|
||||
- https://github.com/casbin/casbin/issues
|
||||
- hsluoyz@gmail.com
|
||||
- Tencent QQ group: [546057381](//shang.qq.com/wpa/qunwpa?idkey=8ac8b91fc97ace3d383d0035f7aa06f7d670fd8e8d4837347354a31c18fac885)
|
||||
|
||||
## Donation
|
||||
|
||||
[](http://www.patreon.com/yangluo)
|
||||
|
||||

|
||||

|
||||
BIN
vendor/github.com/casbin/casbin/casbin-logo.png
generated
vendored
BIN
vendor/github.com/casbin/casbin/casbin-logo.png
generated
vendored
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 34 KiB |
266
vendor/github.com/casbin/casbin/config/config.go
generated
vendored
266
vendor/github.com/casbin/casbin/config/config.go
generated
vendored
@@ -1,266 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package config
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"bytes"
|
||||
"errors"
|
||||
"fmt"
|
||||
"io"
|
||||
"os"
|
||||
"strconv"
|
||||
"strings"
|
||||
"sync"
|
||||
)
|
||||
|
||||
var (
|
||||
// DEFAULT_SECTION specifies the name of a section if no name provided
|
||||
DEFAULT_SECTION = "default"
|
||||
// DEFAULT_COMMENT defines what character(s) indicate a comment `#`
|
||||
DEFAULT_COMMENT = []byte{'#'}
|
||||
// DEFAULT_COMMENT_SEM defines what alternate character(s) indicate a comment `;`
|
||||
DEFAULT_COMMENT_SEM = []byte{';'}
|
||||
// DEFAULT_MULTI_LINE_SEPARATOR defines what character indicates a multi-line content
|
||||
DEFAULT_MULTI_LINE_SEPARATOR = []byte{'\\'}
|
||||
)
|
||||
|
||||
// ConfigInterface defines the behavior of a Config implemenation
|
||||
type ConfigInterface interface {
|
||||
String(key string) string
|
||||
Strings(key string) []string
|
||||
Bool(key string) (bool, error)
|
||||
Int(key string) (int, error)
|
||||
Int64(key string) (int64, error)
|
||||
Float64(key string) (float64, error)
|
||||
Set(key string, value string) error
|
||||
}
|
||||
|
||||
// Config represents an implementation of the ConfigInterface
|
||||
type Config struct {
|
||||
// map is not safe.
|
||||
sync.RWMutex
|
||||
// Section:key=value
|
||||
data map[string]map[string]string
|
||||
}
|
||||
|
||||
// NewConfig create an empty configuration representation from file.
|
||||
func NewConfig(confName string) (ConfigInterface, error) {
|
||||
c := &Config{
|
||||
data: make(map[string]map[string]string),
|
||||
}
|
||||
err := c.parse(confName)
|
||||
return c, err
|
||||
}
|
||||
|
||||
// NewConfigFromText create an empty configuration representation from text.
|
||||
func NewConfigFromText(text string) (ConfigInterface, error) {
|
||||
c := &Config{
|
||||
data: make(map[string]map[string]string),
|
||||
}
|
||||
err := c.parseBuffer(bufio.NewReader(strings.NewReader(text)))
|
||||
return c, err
|
||||
}
|
||||
|
||||
// AddConfig adds a new section->key:value to the configuration.
|
||||
func (c *Config) AddConfig(section string, option string, value string) bool {
|
||||
if section == "" {
|
||||
section = DEFAULT_SECTION
|
||||
}
|
||||
|
||||
if _, ok := c.data[section]; !ok {
|
||||
c.data[section] = make(map[string]string)
|
||||
}
|
||||
|
||||
_, ok := c.data[section][option]
|
||||
c.data[section][option] = value
|
||||
|
||||
return !ok
|
||||
}
|
||||
|
||||
func (c *Config) parse(fname string) (err error) {
|
||||
c.Lock()
|
||||
f, err := os.Open(fname)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer c.Unlock()
|
||||
defer f.Close()
|
||||
|
||||
buf := bufio.NewReader(f)
|
||||
return c.parseBuffer(buf)
|
||||
}
|
||||
|
||||
func (c *Config) parseBuffer(buf *bufio.Reader) error {
|
||||
var section string
|
||||
var lineNum int
|
||||
var buffer bytes.Buffer
|
||||
var canWrite bool
|
||||
for {
|
||||
if canWrite {
|
||||
if err := c.write(section, lineNum, &buffer); err != nil {
|
||||
return err
|
||||
} else {
|
||||
canWrite = false
|
||||
}
|
||||
}
|
||||
lineNum++
|
||||
line, _, err := buf.ReadLine()
|
||||
if err == io.EOF {
|
||||
// force write when buffer is not flushed yet
|
||||
if buffer.Len() > 0 {
|
||||
if err := c.write(section, lineNum, &buffer); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
break
|
||||
} else if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
line = bytes.TrimSpace(line)
|
||||
switch {
|
||||
case bytes.Equal(line, []byte{}), bytes.HasPrefix(line, DEFAULT_COMMENT_SEM),
|
||||
bytes.HasPrefix(line, DEFAULT_COMMENT):
|
||||
canWrite = true
|
||||
continue
|
||||
case bytes.HasPrefix(line, []byte{'['}) && bytes.HasSuffix(line, []byte{']'}):
|
||||
// force write when buffer is not flushed yet
|
||||
if buffer.Len() > 0 {
|
||||
if err := c.write(section, lineNum, &buffer); err != nil {
|
||||
return err
|
||||
}
|
||||
canWrite = false
|
||||
}
|
||||
section = string(line[1 : len(line)-1])
|
||||
default:
|
||||
var p []byte
|
||||
if bytes.HasSuffix(line, DEFAULT_MULTI_LINE_SEPARATOR) {
|
||||
p = bytes.TrimSpace(line[:len(line)-1])
|
||||
} else {
|
||||
p = line
|
||||
canWrite = true
|
||||
}
|
||||
|
||||
if _, err := buffer.Write(p); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func (c *Config) write(section string, lineNum int, b *bytes.Buffer) error {
|
||||
if b.Len() <= 0 {
|
||||
return nil
|
||||
}
|
||||
|
||||
optionVal := bytes.SplitN(b.Bytes(), []byte{'='}, 2)
|
||||
if len(optionVal) != 2 {
|
||||
return fmt.Errorf("parse the content error : line %d , %s = ? ", lineNum, optionVal[0])
|
||||
}
|
||||
option := bytes.TrimSpace(optionVal[0])
|
||||
value := bytes.TrimSpace(optionVal[1])
|
||||
c.AddConfig(section, string(option), string(value))
|
||||
|
||||
// flush buffer after adding
|
||||
b.Reset()
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
// Bool lookups up the value using the provided key and converts the value to a bool
|
||||
func (c *Config) Bool(key string) (bool, error) {
|
||||
return strconv.ParseBool(c.get(key))
|
||||
}
|
||||
|
||||
// Int lookups up the value using the provided key and converts the value to a int
|
||||
func (c *Config) Int(key string) (int, error) {
|
||||
return strconv.Atoi(c.get(key))
|
||||
}
|
||||
|
||||
// Int64 lookups up the value using the provided key and converts the value to a int64
|
||||
func (c *Config) Int64(key string) (int64, error) {
|
||||
return strconv.ParseInt(c.get(key), 10, 64)
|
||||
}
|
||||
|
||||
// Float64 lookups up the value using the provided key and converts the value to a float64
|
||||
func (c *Config) Float64(key string) (float64, error) {
|
||||
return strconv.ParseFloat(c.get(key), 64)
|
||||
}
|
||||
|
||||
// String lookups up the value using the provided key and converts the value to a string
|
||||
func (c *Config) String(key string) string {
|
||||
return c.get(key)
|
||||
}
|
||||
|
||||
// Strings lookups up the value using the provided key and converts the value to an array of string
|
||||
// by splitting the string by comma
|
||||
func (c *Config) Strings(key string) []string {
|
||||
v := c.get(key)
|
||||
if v == "" {
|
||||
return nil
|
||||
}
|
||||
return strings.Split(v, ",")
|
||||
}
|
||||
|
||||
// Set sets the value for the specific key in the Config
|
||||
func (c *Config) Set(key string, value string) error {
|
||||
c.Lock()
|
||||
defer c.Unlock()
|
||||
if len(key) == 0 {
|
||||
return errors.New("key is empty")
|
||||
}
|
||||
|
||||
var (
|
||||
section string
|
||||
option string
|
||||
)
|
||||
|
||||
keys := strings.Split(strings.ToLower(key), "::")
|
||||
if len(keys) >= 2 {
|
||||
section = keys[0]
|
||||
option = keys[1]
|
||||
} else {
|
||||
option = keys[0]
|
||||
}
|
||||
|
||||
c.AddConfig(section, option, value)
|
||||
return nil
|
||||
}
|
||||
|
||||
// section.key or key
|
||||
func (c *Config) get(key string) string {
|
||||
var (
|
||||
section string
|
||||
option string
|
||||
)
|
||||
|
||||
keys := strings.Split(strings.ToLower(key), "::")
|
||||
if len(keys) >= 2 {
|
||||
section = keys[0]
|
||||
option = keys[1]
|
||||
} else {
|
||||
section = DEFAULT_SECTION
|
||||
option = keys[0]
|
||||
}
|
||||
|
||||
if value, ok := c.data[section][option]; ok {
|
||||
return value
|
||||
}
|
||||
|
||||
return ""
|
||||
}
|
||||
75
vendor/github.com/casbin/casbin/effect/default_effector.go
generated
vendored
75
vendor/github.com/casbin/casbin/effect/default_effector.go
generated
vendored
@@ -1,75 +0,0 @@
|
||||
// Copyright 2018 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package effect
|
||||
|
||||
import "github.com/pkg/errors"
|
||||
|
||||
// DefaultEffector is default effector for Casbin.
|
||||
type DefaultEffector struct {
|
||||
}
|
||||
|
||||
// NewDefaultEffector is the constructor for DefaultEffector.
|
||||
func NewDefaultEffector() *DefaultEffector {
|
||||
e := DefaultEffector{}
|
||||
return &e
|
||||
}
|
||||
|
||||
// MergeEffects merges all matching results collected by the enforcer into a single decision.
|
||||
func (e *DefaultEffector) MergeEffects(expr string, effects []Effect, results []float64) (bool, error) {
|
||||
result := false
|
||||
if expr == "some(where (p_eft == allow))" {
|
||||
result = false
|
||||
for _, eft := range effects {
|
||||
if eft == Allow {
|
||||
result = true
|
||||
break
|
||||
}
|
||||
}
|
||||
} else if expr == "!some(where (p_eft == deny))" {
|
||||
result = true
|
||||
for _, eft := range effects {
|
||||
if eft == Deny {
|
||||
result = false
|
||||
break
|
||||
}
|
||||
}
|
||||
} else if expr == "some(where (p_eft == allow)) && !some(where (p_eft == deny))" {
|
||||
result = false
|
||||
for _, eft := range effects {
|
||||
if eft == Allow {
|
||||
result = true
|
||||
} else if eft == Deny {
|
||||
result = false
|
||||
break
|
||||
}
|
||||
}
|
||||
} else if expr == "priority(p_eft) || deny" {
|
||||
result = false
|
||||
for _, eft := range effects {
|
||||
if eft != Indeterminate {
|
||||
if eft == Allow {
|
||||
result = true
|
||||
} else {
|
||||
result = false
|
||||
}
|
||||
break
|
||||
}
|
||||
}
|
||||
} else {
|
||||
return false, errors.New("unsupported effect")
|
||||
}
|
||||
|
||||
return result, nil
|
||||
}
|
||||
31
vendor/github.com/casbin/casbin/effect/effector.go
generated
vendored
31
vendor/github.com/casbin/casbin/effect/effector.go
generated
vendored
@@ -1,31 +0,0 @@
|
||||
// Copyright 2018 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package effect
|
||||
|
||||
// Effect is the result for a policy rule.
|
||||
type Effect int
|
||||
|
||||
// Values for policy effect.
|
||||
const (
|
||||
Allow Effect = iota
|
||||
Indeterminate
|
||||
Deny
|
||||
)
|
||||
|
||||
// Effector is the interface for Casbin effectors.
|
||||
type Effector interface {
|
||||
// MergeEffects merges all matching results collected by the enforcer into a single decision.
|
||||
MergeEffects(expr string, effects []Effect, results []float64) (bool, error)
|
||||
}
|
||||
425
vendor/github.com/casbin/casbin/enforcer.go
generated
vendored
425
vendor/github.com/casbin/casbin/enforcer.go
generated
vendored
@@ -1,425 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package casbin
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
|
||||
"github.com/Knetic/govaluate"
|
||||
|
||||
"github.com/casbin/casbin/effect"
|
||||
"github.com/casbin/casbin/model"
|
||||
"github.com/casbin/casbin/persist"
|
||||
"github.com/casbin/casbin/persist/file-adapter"
|
||||
"github.com/casbin/casbin/rbac"
|
||||
"github.com/casbin/casbin/rbac/default-role-manager"
|
||||
"github.com/casbin/casbin/util"
|
||||
)
|
||||
|
||||
// Enforcer is the main interface for authorization enforcement and policy management.
|
||||
type Enforcer struct {
|
||||
modelPath string
|
||||
model model.Model
|
||||
fm model.FunctionMap
|
||||
eft effect.Effector
|
||||
|
||||
adapter persist.Adapter
|
||||
watcher persist.Watcher
|
||||
rm rbac.RoleManager
|
||||
|
||||
enabled bool
|
||||
autoSave bool
|
||||
autoBuildRoleLinks bool
|
||||
}
|
||||
|
||||
// NewEnforcer creates an enforcer via file or DB.
|
||||
// File:
|
||||
// e := casbin.NewEnforcer("path/to/basic_model.conf", "path/to/basic_policy.csv")
|
||||
// MySQL DB:
|
||||
// a := mysqladapter.NewDBAdapter("mysql", "mysql_username:mysql_password@tcp(127.0.0.1:3306)/")
|
||||
// e := casbin.NewEnforcer("path/to/basic_model.conf", a)
|
||||
func NewEnforcer(params ...interface{}) *Enforcer {
|
||||
e := &Enforcer{}
|
||||
e.rm = defaultrolemanager.NewRoleManager(10)
|
||||
e.eft = effect.NewDefaultEffector()
|
||||
|
||||
parsedParamLen := 0
|
||||
if len(params) >= 1 {
|
||||
enableLog, ok := params[len(params)-1].(bool)
|
||||
if ok {
|
||||
e.EnableLog(enableLog)
|
||||
|
||||
parsedParamLen++
|
||||
}
|
||||
}
|
||||
|
||||
if len(params)-parsedParamLen == 2 {
|
||||
switch params[0].(type) {
|
||||
case string:
|
||||
switch params[1].(type) {
|
||||
case string:
|
||||
e.InitWithFile(params[0].(string), params[1].(string))
|
||||
default:
|
||||
e.InitWithAdapter(params[0].(string), params[1].(persist.Adapter))
|
||||
}
|
||||
default:
|
||||
switch params[1].(type) {
|
||||
case string:
|
||||
panic("Invalid parameters for enforcer.")
|
||||
default:
|
||||
e.InitWithModelAndAdapter(params[0].(model.Model), params[1].(persist.Adapter))
|
||||
}
|
||||
}
|
||||
} else if len(params)-parsedParamLen == 1 {
|
||||
switch params[0].(type) {
|
||||
case string:
|
||||
e.InitWithFile(params[0].(string), "")
|
||||
default:
|
||||
e.InitWithModelAndAdapter(params[0].(model.Model), nil)
|
||||
}
|
||||
} else if len(params)-parsedParamLen == 0 {
|
||||
e.InitWithFile("", "")
|
||||
} else {
|
||||
panic("Invalid parameters for enforcer.")
|
||||
}
|
||||
|
||||
return e
|
||||
}
|
||||
|
||||
// InitWithFile initializes an enforcer with a model file and a policy file.
|
||||
func (e *Enforcer) InitWithFile(modelPath string, policyPath string) {
|
||||
a := fileadapter.NewAdapter(policyPath)
|
||||
e.InitWithAdapter(modelPath, a)
|
||||
}
|
||||
|
||||
// InitWithAdapter initializes an enforcer with a database adapter.
|
||||
func (e *Enforcer) InitWithAdapter(modelPath string, adapter persist.Adapter) {
|
||||
m := NewModel(modelPath, "")
|
||||
e.InitWithModelAndAdapter(m, adapter)
|
||||
|
||||
e.modelPath = modelPath
|
||||
}
|
||||
|
||||
// InitWithModelAndAdapter initializes an enforcer with a model and a database adapter.
|
||||
func (e *Enforcer) InitWithModelAndAdapter(m model.Model, adapter persist.Adapter) {
|
||||
e.adapter = adapter
|
||||
e.watcher = nil
|
||||
|
||||
e.model = m
|
||||
e.model.PrintModel()
|
||||
e.fm = model.LoadFunctionMap()
|
||||
|
||||
e.initialize()
|
||||
|
||||
if e.adapter != nil {
|
||||
// error intentionally ignored
|
||||
e.LoadPolicy()
|
||||
}
|
||||
}
|
||||
|
||||
func (e *Enforcer) initialize() {
|
||||
e.enabled = true
|
||||
e.autoSave = true
|
||||
e.autoBuildRoleLinks = true
|
||||
}
|
||||
|
||||
// NewModel creates a model.
|
||||
func NewModel(text ...string) model.Model {
|
||||
m := make(model.Model)
|
||||
|
||||
if len(text) == 2 {
|
||||
if text[0] != "" {
|
||||
m.LoadModel(text[0])
|
||||
}
|
||||
} else if len(text) == 1 {
|
||||
m.LoadModelFromText(text[0])
|
||||
} else if len(text) != 0 {
|
||||
panic("Invalid parameters for model.")
|
||||
}
|
||||
|
||||
return m
|
||||
}
|
||||
|
||||
// LoadModel reloads the model from the model CONF file.
|
||||
// Because the policy is attached to a model, so the policy is invalidated and needs to be reloaded by calling LoadPolicy().
|
||||
func (e *Enforcer) LoadModel() {
|
||||
e.model = NewModel()
|
||||
e.model.LoadModel(e.modelPath)
|
||||
e.model.PrintModel()
|
||||
e.fm = model.LoadFunctionMap()
|
||||
}
|
||||
|
||||
// GetModel gets the current model.
|
||||
func (e *Enforcer) GetModel() model.Model {
|
||||
return e.model
|
||||
}
|
||||
|
||||
// SetModel sets the current model.
|
||||
func (e *Enforcer) SetModel(m model.Model) {
|
||||
e.model = m
|
||||
e.fm = model.LoadFunctionMap()
|
||||
}
|
||||
|
||||
// GetAdapter gets the current adapter.
|
||||
func (e *Enforcer) GetAdapter() persist.Adapter {
|
||||
return e.adapter
|
||||
}
|
||||
|
||||
// SetAdapter sets the current adapter.
|
||||
func (e *Enforcer) SetAdapter(adapter persist.Adapter) {
|
||||
e.adapter = adapter
|
||||
}
|
||||
|
||||
// SetWatcher sets the current watcher.
|
||||
func (e *Enforcer) SetWatcher(watcher persist.Watcher) {
|
||||
e.watcher = watcher
|
||||
// error intentionally ignored
|
||||
watcher.SetUpdateCallback(func(string) { e.LoadPolicy() })
|
||||
}
|
||||
|
||||
// SetRoleManager sets the current role manager.
|
||||
func (e *Enforcer) SetRoleManager(rm rbac.RoleManager) {
|
||||
e.rm = rm
|
||||
}
|
||||
|
||||
// SetEffector sets the current effector.
|
||||
func (e *Enforcer) SetEffector(eft effect.Effector) {
|
||||
e.eft = eft
|
||||
}
|
||||
|
||||
// ClearPolicy clears all policy.
|
||||
func (e *Enforcer) ClearPolicy() {
|
||||
e.model.ClearPolicy()
|
||||
}
|
||||
|
||||
// LoadPolicy reloads the policy from file/database.
|
||||
func (e *Enforcer) LoadPolicy() error {
|
||||
e.model.ClearPolicy()
|
||||
if err := e.adapter.LoadPolicy(e.model); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
e.model.PrintPolicy()
|
||||
if e.autoBuildRoleLinks {
|
||||
e.BuildRoleLinks()
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// LoadFilteredPolicy reloads a filtered policy from file/database.
|
||||
func (e *Enforcer) LoadFilteredPolicy(filter interface{}) error {
|
||||
e.model.ClearPolicy()
|
||||
|
||||
var filteredAdapter persist.FilteredAdapter
|
||||
|
||||
// Attempt to cast the Adapter as a FilteredAdapter
|
||||
switch e.adapter.(type) {
|
||||
case persist.FilteredAdapter:
|
||||
filteredAdapter = e.adapter.(persist.FilteredAdapter)
|
||||
default:
|
||||
return errors.New("filtered policies are not supported by this adapter")
|
||||
}
|
||||
if err := filteredAdapter.LoadFilteredPolicy(e.model, filter); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
e.model.PrintPolicy()
|
||||
if e.autoBuildRoleLinks {
|
||||
e.BuildRoleLinks()
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// IsFiltered returns true if the loaded policy has been filtered.
|
||||
func (e *Enforcer) IsFiltered() bool {
|
||||
filteredAdapter, ok := e.adapter.(persist.FilteredAdapter)
|
||||
if !ok {
|
||||
return false
|
||||
}
|
||||
return filteredAdapter.IsFiltered()
|
||||
}
|
||||
|
||||
// SavePolicy saves the current policy (usually after changed with Casbin API) back to file/database.
|
||||
func (e *Enforcer) SavePolicy() error {
|
||||
if e.IsFiltered() {
|
||||
return errors.New("cannot save a filtered policy")
|
||||
}
|
||||
if err := e.adapter.SavePolicy(e.model); err != nil {
|
||||
return err
|
||||
}
|
||||
if e.watcher != nil {
|
||||
return e.watcher.Update()
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// EnableEnforce changes the enforcing state of Casbin, when Casbin is disabled, all access will be allowed by the Enforce() function.
|
||||
func (e *Enforcer) EnableEnforce(enable bool) {
|
||||
e.enabled = enable
|
||||
}
|
||||
|
||||
// EnableLog changes whether to print Casbin log to the standard output.
|
||||
func (e *Enforcer) EnableLog(enable bool) {
|
||||
util.EnableLog = enable
|
||||
}
|
||||
|
||||
// EnableAutoSave controls whether to save a policy rule automatically to the adapter when it is added or removed.
|
||||
func (e *Enforcer) EnableAutoSave(autoSave bool) {
|
||||
e.autoSave = autoSave
|
||||
}
|
||||
|
||||
// EnableAutoBuildRoleLinks controls whether to rebuild the role inheritance relations when a role is added or deleted.
|
||||
func (e *Enforcer) EnableAutoBuildRoleLinks(autoBuildRoleLinks bool) {
|
||||
e.autoBuildRoleLinks = autoBuildRoleLinks
|
||||
}
|
||||
|
||||
// BuildRoleLinks manually rebuild the role inheritance relations.
|
||||
func (e *Enforcer) BuildRoleLinks() {
|
||||
// error intentionally ignored
|
||||
e.rm.Clear()
|
||||
e.model.BuildRoleLinks(e.rm)
|
||||
}
|
||||
|
||||
// Enforce decides whether a "subject" can access a "object" with the operation "action", input parameters are usually: (sub, obj, act).
|
||||
func (e *Enforcer) Enforce(rvals ...interface{}) bool {
|
||||
if !e.enabled {
|
||||
return true
|
||||
}
|
||||
|
||||
functions := make(map[string]govaluate.ExpressionFunction)
|
||||
for key, function := range e.fm {
|
||||
functions[key] = function
|
||||
}
|
||||
if _, ok := e.model["g"]; ok {
|
||||
for key, ast := range e.model["g"] {
|
||||
rm := ast.RM
|
||||
functions[key] = util.GenerateGFunction(rm)
|
||||
}
|
||||
}
|
||||
|
||||
expString := e.model["m"]["m"].Value
|
||||
expression, _ := govaluate.NewEvaluableExpressionWithFunctions(expString, functions)
|
||||
|
||||
var policyEffects []effect.Effect
|
||||
var matcherResults []float64
|
||||
if policyLen := len(e.model["p"]["p"].Policy); policyLen != 0 {
|
||||
policyEffects = make([]effect.Effect, policyLen)
|
||||
matcherResults = make([]float64, policyLen)
|
||||
|
||||
for i, pvals := range e.model["p"]["p"].Policy {
|
||||
// util.LogPrint("Policy Rule: ", pvals)
|
||||
|
||||
parameters := make(map[string]interface{}, 8)
|
||||
for j, token := range e.model["r"]["r"].Tokens {
|
||||
parameters[token] = rvals[j]
|
||||
}
|
||||
for j, token := range e.model["p"]["p"].Tokens {
|
||||
parameters[token] = pvals[j]
|
||||
}
|
||||
|
||||
result, err := expression.Evaluate(parameters)
|
||||
// util.LogPrint("Result: ", result)
|
||||
|
||||
if err != nil {
|
||||
policyEffects[i] = effect.Indeterminate
|
||||
panic(err)
|
||||
}
|
||||
|
||||
switch result.(type) {
|
||||
case bool:
|
||||
if !result.(bool) {
|
||||
policyEffects[i] = effect.Indeterminate
|
||||
continue
|
||||
}
|
||||
case float64:
|
||||
if result.(float64) == 0 {
|
||||
policyEffects[i] = effect.Indeterminate
|
||||
continue
|
||||
} else {
|
||||
matcherResults[i] = result.(float64)
|
||||
}
|
||||
default:
|
||||
panic(errors.New("matcher result should be bool, int or float"))
|
||||
}
|
||||
|
||||
if eft, ok := parameters["p_eft"]; ok {
|
||||
if eft == "allow" {
|
||||
policyEffects[i] = effect.Allow
|
||||
} else if eft == "deny" {
|
||||
policyEffects[i] = effect.Deny
|
||||
} else {
|
||||
policyEffects[i] = effect.Indeterminate
|
||||
}
|
||||
} else {
|
||||
policyEffects[i] = effect.Allow
|
||||
}
|
||||
|
||||
if e.model["e"]["e"].Value == "priority(p_eft) || deny" {
|
||||
break
|
||||
}
|
||||
|
||||
}
|
||||
} else {
|
||||
policyEffects = make([]effect.Effect, 1)
|
||||
matcherResults = make([]float64, 1)
|
||||
|
||||
parameters := make(map[string]interface{}, 8)
|
||||
for j, token := range e.model["r"]["r"].Tokens {
|
||||
parameters[token] = rvals[j]
|
||||
}
|
||||
for _, token := range e.model["p"]["p"].Tokens {
|
||||
parameters[token] = ""
|
||||
}
|
||||
|
||||
result, err := expression.Evaluate(parameters)
|
||||
// util.LogPrint("Result: ", result)
|
||||
|
||||
if err != nil {
|
||||
policyEffects[0] = effect.Indeterminate
|
||||
panic(err)
|
||||
}
|
||||
|
||||
if result.(bool) {
|
||||
policyEffects[0] = effect.Allow
|
||||
} else {
|
||||
policyEffects[0] = effect.Indeterminate
|
||||
}
|
||||
}
|
||||
|
||||
// util.LogPrint("Rule Results: ", policyEffects)
|
||||
|
||||
result, err := e.eft.MergeEffects(e.model["e"]["e"].Value, policyEffects, matcherResults)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
// only generate the request --> result string if the message
|
||||
// is going to be logged.
|
||||
if util.EnableLog {
|
||||
reqStr := "Request: "
|
||||
for i, rval := range rvals {
|
||||
if i != len(rvals)-1 {
|
||||
reqStr += fmt.Sprintf("%v, ", rval)
|
||||
} else {
|
||||
reqStr += fmt.Sprintf("%v", rval)
|
||||
}
|
||||
}
|
||||
reqStr += fmt.Sprintf(" ---> %t", result)
|
||||
util.LogPrint(reqStr)
|
||||
}
|
||||
|
||||
return result
|
||||
}
|
||||
74
vendor/github.com/casbin/casbin/enforcer_cached.go
generated
vendored
74
vendor/github.com/casbin/casbin/enforcer_cached.go
generated
vendored
@@ -1,74 +0,0 @@
|
||||
// Copyright 2018 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package casbin
|
||||
|
||||
import (
|
||||
"sync"
|
||||
)
|
||||
|
||||
// CachedEnforcer wraps Enforcer and provides decision cache
|
||||
type CachedEnforcer struct {
|
||||
*Enforcer
|
||||
m map[string]bool
|
||||
enableCache bool
|
||||
locker *sync.Mutex
|
||||
}
|
||||
|
||||
// NewCachedEnforcer creates a cached enforcer via file or DB.
|
||||
func NewCachedEnforcer(params ...interface{}) *CachedEnforcer {
|
||||
e := &CachedEnforcer{}
|
||||
e.Enforcer = NewEnforcer(params...)
|
||||
e.enableCache = true
|
||||
e.m = make(map[string]bool)
|
||||
e.locker = new(sync.Mutex)
|
||||
return e
|
||||
}
|
||||
|
||||
// EnableCache determines whether to enable cache on Enforce(). When enableCache is enabled, cached result (true | false) will be returned for previous decisions.
|
||||
func (e *CachedEnforcer) EnableCache(enableCache bool) {
|
||||
e.enableCache = enableCache
|
||||
}
|
||||
|
||||
// Enforce decides whether a "subject" can access a "object" with the operation "action", input parameters are usually: (sub, obj, act).
|
||||
// if rvals is not string , ingore the cache
|
||||
func (e *CachedEnforcer) Enforce(rvals ...interface{}) bool {
|
||||
if !e.enableCache {
|
||||
return e.Enforcer.Enforce(rvals...)
|
||||
}
|
||||
|
||||
key := ""
|
||||
for _, rval := range rvals {
|
||||
if val, ok := rval.(string); ok {
|
||||
key += val + "$$"
|
||||
} else {
|
||||
return e.Enforcer.Enforce(rvals...)
|
||||
}
|
||||
}
|
||||
|
||||
e.locker.Lock()
|
||||
defer e.locker.Unlock()
|
||||
if _, ok := e.m[key]; ok {
|
||||
return e.m[key]
|
||||
} else {
|
||||
res := e.Enforcer.Enforce(rvals...)
|
||||
e.m[key] = res
|
||||
return res
|
||||
}
|
||||
}
|
||||
|
||||
// InvalidateCache deletes all the existing cached decisions.
|
||||
func (e *CachedEnforcer) InvalidateCache() {
|
||||
e.m = make(map[string]bool)
|
||||
}
|
||||
102
vendor/github.com/casbin/casbin/enforcer_safe.go
generated
vendored
102
vendor/github.com/casbin/casbin/enforcer_safe.go
generated
vendored
@@ -1,102 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package casbin
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
)
|
||||
|
||||
// NewEnforcerSafe calls NewEnforcer in a safe way, returns error instead of causing panic.
|
||||
func NewEnforcerSafe(params ...interface{}) (e *Enforcer, err error) {
|
||||
defer func() {
|
||||
if r := recover(); r != nil {
|
||||
err = fmt.Errorf("%v", r)
|
||||
e = nil
|
||||
}
|
||||
}()
|
||||
|
||||
e = NewEnforcer(params...)
|
||||
err = nil
|
||||
return
|
||||
}
|
||||
|
||||
// LoadModelSafe calls LoadModel in a safe way, returns error instead of causing panic.
|
||||
func (e *Enforcer) LoadModelSafe() (err error) {
|
||||
defer func() {
|
||||
if r := recover(); r != nil {
|
||||
err = fmt.Errorf("%v", r)
|
||||
}
|
||||
}()
|
||||
|
||||
e.LoadModel()
|
||||
err = nil
|
||||
return
|
||||
}
|
||||
|
||||
// EnforceSafe calls Enforce in a safe way, returns error instead of causing panic.
|
||||
func (e *Enforcer) EnforceSafe(rvals ...interface{}) (result bool, err error) {
|
||||
defer func() {
|
||||
if r := recover(); r != nil {
|
||||
err = fmt.Errorf("%v", r)
|
||||
result = false
|
||||
}
|
||||
}()
|
||||
|
||||
result = e.Enforce(rvals...)
|
||||
err = nil
|
||||
return
|
||||
}
|
||||
|
||||
// AddPolicySafe calls AddPolicy in a safe way, returns error instead of causing panic.
|
||||
func (e *Enforcer) AddPolicySafe(params ...interface{}) (result bool, err error) {
|
||||
defer func() {
|
||||
if r := recover(); r != nil {
|
||||
err = fmt.Errorf("%v", r)
|
||||
result = false
|
||||
}
|
||||
}()
|
||||
|
||||
result = e.AddNamedPolicy("p", params...)
|
||||
err = nil
|
||||
return
|
||||
}
|
||||
|
||||
// RemovePolicySafe calls RemovePolicy in a safe way, returns error instead of causing panic.
|
||||
func (e *Enforcer) RemovePolicySafe(params ...interface{}) (result bool, err error) {
|
||||
defer func() {
|
||||
if r := recover(); r != nil {
|
||||
err = fmt.Errorf("%v", r)
|
||||
result = false
|
||||
}
|
||||
}()
|
||||
|
||||
result = e.RemoveNamedPolicy("p", params...)
|
||||
err = nil
|
||||
return
|
||||
}
|
||||
|
||||
// RemoveFilteredPolicySafe calls RemoveFilteredPolicy in a safe way, returns error instead of causing panic.
|
||||
func (e *Enforcer) RemoveFilteredPolicySafe(fieldIndex int, fieldValues ...string) (result bool, err error) {
|
||||
defer func() {
|
||||
if r := recover(); r != nil {
|
||||
err = fmt.Errorf("%v", r)
|
||||
result = false
|
||||
}
|
||||
}()
|
||||
|
||||
result = e.RemoveFilteredNamedPolicy("p", fieldIndex, fieldValues...)
|
||||
err = nil
|
||||
return
|
||||
}
|
||||
223
vendor/github.com/casbin/casbin/enforcer_synced.go
generated
vendored
223
vendor/github.com/casbin/casbin/enforcer_synced.go
generated
vendored
@@ -1,223 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package casbin
|
||||
|
||||
import (
|
||||
"log"
|
||||
"sync"
|
||||
"time"
|
||||
|
||||
"github.com/casbin/casbin/persist"
|
||||
)
|
||||
|
||||
// SyncedEnforcer wraps Enforcer and provides synchronized access
|
||||
type SyncedEnforcer struct {
|
||||
*Enforcer
|
||||
m sync.RWMutex
|
||||
autoLoad bool
|
||||
}
|
||||
|
||||
// NewSyncedEnforcer creates a synchronized enforcer via file or DB.
|
||||
func NewSyncedEnforcer(params ...interface{}) *SyncedEnforcer {
|
||||
e := &SyncedEnforcer{}
|
||||
e.Enforcer = NewEnforcer(params...)
|
||||
e.autoLoad = false
|
||||
return e
|
||||
}
|
||||
|
||||
// StartAutoLoadPolicy starts a go routine that will every specified duration call LoadPolicy
|
||||
func (e *SyncedEnforcer) StartAutoLoadPolicy(d time.Duration) {
|
||||
e.autoLoad = true
|
||||
go func() {
|
||||
n := 1
|
||||
log.Print("Start automatically load policy")
|
||||
for {
|
||||
if !e.autoLoad {
|
||||
log.Print("Stop automatically load policy")
|
||||
break
|
||||
}
|
||||
|
||||
// error intentionally ignored
|
||||
e.LoadPolicy()
|
||||
// Uncomment this line to see when the policy is loaded.
|
||||
// log.Print("Load policy for time: ", n)
|
||||
n++
|
||||
time.Sleep(d)
|
||||
}
|
||||
}()
|
||||
}
|
||||
|
||||
// StopAutoLoadPolicy causes the go routine to exit.
|
||||
func (e *SyncedEnforcer) StopAutoLoadPolicy() {
|
||||
e.autoLoad = false
|
||||
}
|
||||
|
||||
// SetWatcher sets the current watcher.
|
||||
func (e *SyncedEnforcer) SetWatcher(watcher persist.Watcher) {
|
||||
e.watcher = watcher
|
||||
// error intentionally ignored
|
||||
watcher.SetUpdateCallback(func(string) { e.LoadPolicy() })
|
||||
}
|
||||
|
||||
// ClearPolicy clears all policy.
|
||||
func (e *SyncedEnforcer) ClearPolicy() {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
e.Enforcer.ClearPolicy()
|
||||
}
|
||||
|
||||
// LoadPolicy reloads the policy from file/database.
|
||||
func (e *SyncedEnforcer) LoadPolicy() error {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.LoadPolicy()
|
||||
}
|
||||
|
||||
// SavePolicy saves the current policy (usually after changed with Casbin API) back to file/database.
|
||||
func (e *SyncedEnforcer) SavePolicy() error {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.SavePolicy()
|
||||
}
|
||||
|
||||
// BuildRoleLinks manually rebuild the role inheritance relations.
|
||||
func (e *SyncedEnforcer) BuildRoleLinks() {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
e.Enforcer.BuildRoleLinks()
|
||||
}
|
||||
|
||||
// Enforce decides whether a "subject" can access a "object" with the operation "action", input parameters are usually: (sub, obj, act).
|
||||
func (e *SyncedEnforcer) Enforce(rvals ...interface{}) bool {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.Enforce(rvals...)
|
||||
}
|
||||
|
||||
// GetAllSubjects gets the list of subjects that show up in the current policy.
|
||||
func (e *SyncedEnforcer) GetAllSubjects() []string {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.GetAllSubjects()
|
||||
}
|
||||
|
||||
// GetAllObjects gets the list of objects that show up in the current policy.
|
||||
func (e *SyncedEnforcer) GetAllObjects() []string {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.GetAllObjects()
|
||||
}
|
||||
|
||||
// GetAllActions gets the list of actions that show up in the current policy.
|
||||
func (e *SyncedEnforcer) GetAllActions() []string {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.GetAllActions()
|
||||
}
|
||||
|
||||
// GetAllRoles gets the list of roles that show up in the current policy.
|
||||
func (e *SyncedEnforcer) GetAllRoles() []string {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.GetAllRoles()
|
||||
}
|
||||
|
||||
// GetPolicy gets all the authorization rules in the policy.
|
||||
func (e *SyncedEnforcer) GetPolicy() [][]string {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.GetPolicy()
|
||||
}
|
||||
|
||||
// GetFilteredPolicy gets all the authorization rules in the policy, field filters can be specified.
|
||||
func (e *SyncedEnforcer) GetFilteredPolicy(fieldIndex int, fieldValues ...string) [][]string {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.GetFilteredPolicy(fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// GetGroupingPolicy gets all the role inheritance rules in the policy.
|
||||
func (e *SyncedEnforcer) GetGroupingPolicy() [][]string {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.GetGroupingPolicy()
|
||||
}
|
||||
|
||||
// GetFilteredGroupingPolicy gets all the role inheritance rules in the policy, field filters can be specified.
|
||||
func (e *SyncedEnforcer) GetFilteredGroupingPolicy(fieldIndex int, fieldValues ...string) [][]string {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.GetFilteredGroupingPolicy(fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// HasPolicy determines whether an authorization rule exists.
|
||||
func (e *SyncedEnforcer) HasPolicy(params ...interface{}) bool {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.HasPolicy(params...)
|
||||
}
|
||||
|
||||
// AddPolicy adds an authorization rule to the current policy.
|
||||
// If the rule already exists, the function returns false and the rule will not be added.
|
||||
// Otherwise the function returns true by adding the new rule.
|
||||
func (e *SyncedEnforcer) AddPolicy(params ...interface{}) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.AddPolicy(params...)
|
||||
}
|
||||
|
||||
// RemovePolicy removes an authorization rule from the current policy.
|
||||
func (e *SyncedEnforcer) RemovePolicy(params ...interface{}) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.RemovePolicy(params...)
|
||||
}
|
||||
|
||||
// RemoveFilteredPolicy removes an authorization rule from the current policy, field filters can be specified.
|
||||
func (e *SyncedEnforcer) RemoveFilteredPolicy(fieldIndex int, fieldValues ...string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.RemoveFilteredPolicy(fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// HasGroupingPolicy determines whether a role inheritance rule exists.
|
||||
func (e *SyncedEnforcer) HasGroupingPolicy(params ...interface{}) bool {
|
||||
e.m.RLock()
|
||||
defer e.m.RUnlock()
|
||||
return e.Enforcer.HasGroupingPolicy(params...)
|
||||
}
|
||||
|
||||
// AddGroupingPolicy adds a role inheritance rule to the current policy.
|
||||
// If the rule already exists, the function returns false and the rule will not be added.
|
||||
// Otherwise the function returns true by adding the new rule.
|
||||
func (e *SyncedEnforcer) AddGroupingPolicy(params ...interface{}) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.AddGroupingPolicy(params...)
|
||||
}
|
||||
|
||||
// RemoveGroupingPolicy removes a role inheritance rule from the current policy.
|
||||
func (e *SyncedEnforcer) RemoveGroupingPolicy(params ...interface{}) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.RemoveGroupingPolicy(params...)
|
||||
}
|
||||
|
||||
// RemoveFilteredGroupingPolicy removes a role inheritance rule from the current policy, field filters can be specified.
|
||||
func (e *SyncedEnforcer) RemoveFilteredGroupingPolicy(fieldIndex int, fieldValues ...string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.RemoveFilteredGroupingPolicy(fieldIndex, fieldValues...)
|
||||
}
|
||||
85
vendor/github.com/casbin/casbin/internal_api.go
generated
vendored
85
vendor/github.com/casbin/casbin/internal_api.go
generated
vendored
@@ -1,85 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package casbin
|
||||
|
||||
const (
|
||||
notImplemented = "not implemented"
|
||||
)
|
||||
|
||||
// addPolicy adds a rule to the current policy.
|
||||
func (e *Enforcer) addPolicy(sec string, ptype string, rule []string) bool {
|
||||
ruleAdded := e.model.AddPolicy(sec, ptype, rule)
|
||||
if !ruleAdded {
|
||||
return ruleAdded
|
||||
}
|
||||
|
||||
if e.adapter != nil && e.autoSave {
|
||||
if err := e.adapter.AddPolicy(sec, ptype, rule); err != nil {
|
||||
if err.Error() != notImplemented {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
if e.watcher != nil {
|
||||
// error intentionally ignored
|
||||
e.watcher.Update()
|
||||
}
|
||||
}
|
||||
|
||||
return ruleAdded
|
||||
}
|
||||
|
||||
// removePolicy removes a rule from the current policy.
|
||||
func (e *Enforcer) removePolicy(sec string, ptype string, rule []string) bool {
|
||||
ruleRemoved := e.model.RemovePolicy(sec, ptype, rule)
|
||||
if !ruleRemoved {
|
||||
return ruleRemoved
|
||||
}
|
||||
|
||||
if e.adapter != nil && e.autoSave {
|
||||
if err := e.adapter.RemovePolicy(sec, ptype, rule); err != nil {
|
||||
if err.Error() != notImplemented {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
if e.watcher != nil {
|
||||
// error intentionally ignored
|
||||
e.watcher.Update()
|
||||
}
|
||||
}
|
||||
|
||||
return ruleRemoved
|
||||
}
|
||||
|
||||
// removeFilteredPolicy removes rules based on field filters from the current policy.
|
||||
func (e *Enforcer) removeFilteredPolicy(sec string, ptype string, fieldIndex int, fieldValues ...string) bool {
|
||||
ruleRemoved := e.model.RemoveFilteredPolicy(sec, ptype, fieldIndex, fieldValues...)
|
||||
if !ruleRemoved {
|
||||
return ruleRemoved
|
||||
}
|
||||
|
||||
if e.adapter != nil && e.autoSave {
|
||||
if err := e.adapter.RemoveFilteredPolicy(sec, ptype, fieldIndex, fieldValues...); err != nil {
|
||||
if err.Error() != notImplemented {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
if e.watcher != nil {
|
||||
// error intentionally ignored
|
||||
e.watcher.Update()
|
||||
}
|
||||
}
|
||||
|
||||
return ruleRemoved
|
||||
}
|
||||
265
vendor/github.com/casbin/casbin/management_api.go
generated
vendored
265
vendor/github.com/casbin/casbin/management_api.go
generated
vendored
@@ -1,265 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package casbin
|
||||
|
||||
// GetAllSubjects gets the list of subjects that show up in the current policy.
|
||||
func (e *Enforcer) GetAllSubjects() []string {
|
||||
return e.GetAllNamedSubjects("p")
|
||||
}
|
||||
|
||||
// GetAllNamedSubjects gets the list of subjects that show up in the current named policy.
|
||||
func (e *Enforcer) GetAllNamedSubjects(ptype string) []string {
|
||||
return e.model.GetValuesForFieldInPolicy("p", ptype, 0)
|
||||
}
|
||||
|
||||
// GetAllObjects gets the list of objects that show up in the current policy.
|
||||
func (e *Enforcer) GetAllObjects() []string {
|
||||
return e.GetAllNamedObjects("p")
|
||||
}
|
||||
|
||||
// GetAllNamedObjects gets the list of objects that show up in the current named policy.
|
||||
func (e *Enforcer) GetAllNamedObjects(ptype string) []string {
|
||||
return e.model.GetValuesForFieldInPolicy("p", ptype, 1)
|
||||
}
|
||||
|
||||
// GetAllActions gets the list of actions that show up in the current policy.
|
||||
func (e *Enforcer) GetAllActions() []string {
|
||||
return e.GetAllNamedActions("p")
|
||||
}
|
||||
|
||||
// GetAllNamedActions gets the list of actions that show up in the current named policy.
|
||||
func (e *Enforcer) GetAllNamedActions(ptype string) []string {
|
||||
return e.model.GetValuesForFieldInPolicy("p", ptype, 2)
|
||||
}
|
||||
|
||||
// GetAllRoles gets the list of roles that show up in the current policy.
|
||||
func (e *Enforcer) GetAllRoles() []string {
|
||||
return e.GetAllNamedRoles("g")
|
||||
}
|
||||
|
||||
// GetAllNamedRoles gets the list of roles that show up in the current named policy.
|
||||
func (e *Enforcer) GetAllNamedRoles(ptype string) []string {
|
||||
return e.model.GetValuesForFieldInPolicy("g", ptype, 1)
|
||||
}
|
||||
|
||||
// GetPolicy gets all the authorization rules in the policy.
|
||||
func (e *Enforcer) GetPolicy() [][]string {
|
||||
return e.GetNamedPolicy("p")
|
||||
}
|
||||
|
||||
// GetFilteredPolicy gets all the authorization rules in the policy, field filters can be specified.
|
||||
func (e *Enforcer) GetFilteredPolicy(fieldIndex int, fieldValues ...string) [][]string {
|
||||
return e.GetFilteredNamedPolicy("p", fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// GetNamedPolicy gets all the authorization rules in the named policy.
|
||||
func (e *Enforcer) GetNamedPolicy(ptype string) [][]string {
|
||||
return e.model.GetPolicy("p", ptype)
|
||||
}
|
||||
|
||||
// GetFilteredNamedPolicy gets all the authorization rules in the named policy, field filters can be specified.
|
||||
func (e *Enforcer) GetFilteredNamedPolicy(ptype string, fieldIndex int, fieldValues ...string) [][]string {
|
||||
return e.model.GetFilteredPolicy("p", ptype, fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// GetGroupingPolicy gets all the role inheritance rules in the policy.
|
||||
func (e *Enforcer) GetGroupingPolicy() [][]string {
|
||||
return e.GetNamedGroupingPolicy("g")
|
||||
}
|
||||
|
||||
// GetFilteredGroupingPolicy gets all the role inheritance rules in the policy, field filters can be specified.
|
||||
func (e *Enforcer) GetFilteredGroupingPolicy(fieldIndex int, fieldValues ...string) [][]string {
|
||||
return e.GetFilteredNamedGroupingPolicy("g", fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// GetNamedGroupingPolicy gets all the role inheritance rules in the policy.
|
||||
func (e *Enforcer) GetNamedGroupingPolicy(ptype string) [][]string {
|
||||
return e.model.GetPolicy("g", ptype)
|
||||
}
|
||||
|
||||
// GetFilteredNamedGroupingPolicy gets all the role inheritance rules in the policy, field filters can be specified.
|
||||
func (e *Enforcer) GetFilteredNamedGroupingPolicy(ptype string, fieldIndex int, fieldValues ...string) [][]string {
|
||||
return e.model.GetFilteredPolicy("g", ptype, fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// HasPolicy determines whether an authorization rule exists.
|
||||
func (e *Enforcer) HasPolicy(params ...interface{}) bool {
|
||||
return e.HasNamedPolicy("p", params...)
|
||||
}
|
||||
|
||||
// HasNamedPolicy determines whether a named authorization rule exists.
|
||||
func (e *Enforcer) HasNamedPolicy(ptype string, params ...interface{}) bool {
|
||||
if strSlice, ok := params[0].([]string); len(params) == 1 && ok {
|
||||
return e.model.HasPolicy("p", ptype, strSlice)
|
||||
}
|
||||
|
||||
policy := make([]string, 0)
|
||||
for _, param := range params {
|
||||
policy = append(policy, param.(string))
|
||||
}
|
||||
|
||||
return e.model.HasPolicy("p", ptype, policy)
|
||||
}
|
||||
|
||||
// AddPolicy adds an authorization rule to the current policy.
|
||||
// If the rule already exists, the function returns false and the rule will not be added.
|
||||
// Otherwise the function returns true by adding the new rule.
|
||||
func (e *Enforcer) AddPolicy(params ...interface{}) bool {
|
||||
return e.AddNamedPolicy("p", params...)
|
||||
}
|
||||
|
||||
// AddNamedPolicy adds an authorization rule to the current named policy.
|
||||
// If the rule already exists, the function returns false and the rule will not be added.
|
||||
// Otherwise the function returns true by adding the new rule.
|
||||
func (e *Enforcer) AddNamedPolicy(ptype string, params ...interface{}) bool {
|
||||
var ruleAdded bool
|
||||
if strSlice, ok := params[0].([]string); len(params) == 1 && ok {
|
||||
ruleAdded = e.addPolicy("p", ptype, strSlice)
|
||||
} else {
|
||||
policy := make([]string, 0)
|
||||
for _, param := range params {
|
||||
policy = append(policy, param.(string))
|
||||
}
|
||||
|
||||
ruleAdded = e.addPolicy("p", ptype, policy)
|
||||
}
|
||||
|
||||
return ruleAdded
|
||||
}
|
||||
|
||||
// RemovePolicy removes an authorization rule from the current policy.
|
||||
func (e *Enforcer) RemovePolicy(params ...interface{}) bool {
|
||||
return e.RemoveNamedPolicy("p", params...)
|
||||
}
|
||||
|
||||
// RemoveFilteredPolicy removes an authorization rule from the current policy, field filters can be specified.
|
||||
func (e *Enforcer) RemoveFilteredPolicy(fieldIndex int, fieldValues ...string) bool {
|
||||
return e.RemoveFilteredNamedPolicy("p", fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// RemoveNamedPolicy removes an authorization rule from the current named policy.
|
||||
func (e *Enforcer) RemoveNamedPolicy(ptype string, params ...interface{}) bool {
|
||||
var ruleRemoved bool
|
||||
if strSlice, ok := params[0].([]string); len(params) == 1 && ok {
|
||||
ruleRemoved = e.removePolicy("p", ptype, strSlice)
|
||||
} else {
|
||||
policy := make([]string, 0)
|
||||
for _, param := range params {
|
||||
policy = append(policy, param.(string))
|
||||
}
|
||||
|
||||
ruleRemoved = e.removePolicy("p", ptype, policy)
|
||||
}
|
||||
|
||||
return ruleRemoved
|
||||
}
|
||||
|
||||
// RemoveFilteredNamedPolicy removes an authorization rule from the current named policy, field filters can be specified.
|
||||
func (e *Enforcer) RemoveFilteredNamedPolicy(ptype string, fieldIndex int, fieldValues ...string) bool {
|
||||
return e.removeFilteredPolicy("p", ptype, fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// HasGroupingPolicy determines whether a role inheritance rule exists.
|
||||
func (e *Enforcer) HasGroupingPolicy(params ...interface{}) bool {
|
||||
return e.HasNamedGroupingPolicy("g", params...)
|
||||
}
|
||||
|
||||
// HasNamedGroupingPolicy determines whether a named role inheritance rule exists.
|
||||
func (e *Enforcer) HasNamedGroupingPolicy(ptype string, params ...interface{}) bool {
|
||||
if strSlice, ok := params[0].([]string); len(params) == 1 && ok {
|
||||
return e.model.HasPolicy("g", ptype, strSlice)
|
||||
}
|
||||
|
||||
policy := make([]string, 0)
|
||||
for _, param := range params {
|
||||
policy = append(policy, param.(string))
|
||||
}
|
||||
|
||||
return e.model.HasPolicy("g", ptype, policy)
|
||||
}
|
||||
|
||||
// AddGroupingPolicy adds a role inheritance rule to the current policy.
|
||||
// If the rule already exists, the function returns false and the rule will not be added.
|
||||
// Otherwise the function returns true by adding the new rule.
|
||||
func (e *Enforcer) AddGroupingPolicy(params ...interface{}) bool {
|
||||
return e.AddNamedGroupingPolicy("g", params...)
|
||||
}
|
||||
|
||||
// AddNamedGroupingPolicy adds a named role inheritance rule to the current policy.
|
||||
// If the rule already exists, the function returns false and the rule will not be added.
|
||||
// Otherwise the function returns true by adding the new rule.
|
||||
func (e *Enforcer) AddNamedGroupingPolicy(ptype string, params ...interface{}) bool {
|
||||
var ruleAdded bool
|
||||
if strSlice, ok := params[0].([]string); len(params) == 1 && ok {
|
||||
ruleAdded = e.addPolicy("g", ptype, strSlice)
|
||||
} else {
|
||||
policy := make([]string, 0)
|
||||
for _, param := range params {
|
||||
policy = append(policy, param.(string))
|
||||
}
|
||||
|
||||
ruleAdded = e.addPolicy("g", ptype, policy)
|
||||
}
|
||||
|
||||
if e.autoBuildRoleLinks {
|
||||
e.BuildRoleLinks()
|
||||
}
|
||||
return ruleAdded
|
||||
}
|
||||
|
||||
// RemoveGroupingPolicy removes a role inheritance rule from the current policy.
|
||||
func (e *Enforcer) RemoveGroupingPolicy(params ...interface{}) bool {
|
||||
return e.RemoveNamedGroupingPolicy("g", params...)
|
||||
}
|
||||
|
||||
// RemoveFilteredGroupingPolicy removes a role inheritance rule from the current policy, field filters can be specified.
|
||||
func (e *Enforcer) RemoveFilteredGroupingPolicy(fieldIndex int, fieldValues ...string) bool {
|
||||
return e.RemoveFilteredNamedGroupingPolicy("g", fieldIndex, fieldValues...)
|
||||
}
|
||||
|
||||
// RemoveNamedGroupingPolicy removes a role inheritance rule from the current named policy.
|
||||
func (e *Enforcer) RemoveNamedGroupingPolicy(ptype string, params ...interface{}) bool {
|
||||
var ruleRemoved bool
|
||||
if strSlice, ok := params[0].([]string); len(params) == 1 && ok {
|
||||
ruleRemoved = e.removePolicy("g", ptype, strSlice)
|
||||
} else {
|
||||
policy := make([]string, 0)
|
||||
for _, param := range params {
|
||||
policy = append(policy, param.(string))
|
||||
}
|
||||
|
||||
ruleRemoved = e.removePolicy("g", ptype, policy)
|
||||
}
|
||||
|
||||
if e.autoBuildRoleLinks {
|
||||
e.BuildRoleLinks()
|
||||
}
|
||||
return ruleRemoved
|
||||
}
|
||||
|
||||
// RemoveFilteredNamedGroupingPolicy removes a role inheritance rule from the current named policy, field filters can be specified.
|
||||
func (e *Enforcer) RemoveFilteredNamedGroupingPolicy(ptype string, fieldIndex int, fieldValues ...string) bool {
|
||||
ruleRemoved := e.removeFilteredPolicy("g", ptype, fieldIndex, fieldValues...)
|
||||
|
||||
if e.autoBuildRoleLinks {
|
||||
e.BuildRoleLinks()
|
||||
}
|
||||
return ruleRemoved
|
||||
}
|
||||
|
||||
// AddFunction adds a customized function.
|
||||
func (e *Enforcer) AddFunction(name string, function func(args ...interface{}) (interface{}, error)) {
|
||||
e.fm.AddFunction(name, function)
|
||||
}
|
||||
60
vendor/github.com/casbin/casbin/model/assertion.go
generated
vendored
60
vendor/github.com/casbin/casbin/model/assertion.go
generated
vendored
@@ -1,60 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package model
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"strings"
|
||||
|
||||
"github.com/casbin/casbin/rbac"
|
||||
"github.com/casbin/casbin/util"
|
||||
)
|
||||
|
||||
// Assertion represents an expression in a section of the model.
|
||||
// For example: r = sub, obj, act
|
||||
type Assertion struct {
|
||||
Key string
|
||||
Value string
|
||||
Tokens []string
|
||||
Policy [][]string
|
||||
RM rbac.RoleManager
|
||||
}
|
||||
|
||||
func (ast *Assertion) buildRoleLinks(rm rbac.RoleManager) {
|
||||
ast.RM = rm
|
||||
count := strings.Count(ast.Value, "_")
|
||||
for _, rule := range ast.Policy {
|
||||
if count < 2 {
|
||||
panic(errors.New("the number of \"_\" in role definition should be at least 2"))
|
||||
}
|
||||
if len(rule) < count {
|
||||
panic(errors.New("grouping policy elements do not meet role definition"))
|
||||
}
|
||||
|
||||
if count == 2 {
|
||||
// error intentionally ignored
|
||||
ast.RM.AddLink(rule[0], rule[1])
|
||||
} else if count == 3 {
|
||||
// error intentionally ignored
|
||||
ast.RM.AddLink(rule[0], rule[1], rule[2])
|
||||
} else if count == 4 {
|
||||
// error intentionally ignored
|
||||
ast.RM.AddLink(rule[0], rule[1], rule[2], rule[3])
|
||||
}
|
||||
}
|
||||
|
||||
util.LogPrint("Role links for: " + ast.Key)
|
||||
ast.RM.PrintRoles()
|
||||
}
|
||||
40
vendor/github.com/casbin/casbin/model/function.go
generated
vendored
40
vendor/github.com/casbin/casbin/model/function.go
generated
vendored
@@ -1,40 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package model
|
||||
|
||||
import "github.com/casbin/casbin/util"
|
||||
|
||||
// FunctionMap represents the collection of Function.
|
||||
type FunctionMap map[string]func(args ...interface{}) (interface{}, error)
|
||||
|
||||
// Function represents a function that is used in the matchers, used to get attributes in ABAC.
|
||||
type Function func(args ...interface{}) (interface{}, error)
|
||||
|
||||
// AddFunction adds an expression function.
|
||||
func (fm FunctionMap) AddFunction(name string, function Function) {
|
||||
fm[name] = function
|
||||
}
|
||||
|
||||
// LoadFunctionMap loads an initial function map.
|
||||
func LoadFunctionMap() FunctionMap {
|
||||
fm := make(FunctionMap)
|
||||
|
||||
fm.AddFunction("keyMatch", util.KeyMatchFunc)
|
||||
fm.AddFunction("keyMatch2", util.KeyMatch2Func)
|
||||
fm.AddFunction("regexMatch", util.RegexMatchFunc)
|
||||
fm.AddFunction("ipMatch", util.IPMatchFunc)
|
||||
|
||||
return fm
|
||||
}
|
||||
129
vendor/github.com/casbin/casbin/model/model.go
generated
vendored
129
vendor/github.com/casbin/casbin/model/model.go
generated
vendored
@@ -1,129 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package model
|
||||
|
||||
import (
|
||||
"strconv"
|
||||
"strings"
|
||||
|
||||
"github.com/casbin/casbin/config"
|
||||
"github.com/casbin/casbin/util"
|
||||
)
|
||||
|
||||
// Model represents the whole access control model.
|
||||
type Model map[string]AssertionMap
|
||||
|
||||
// AssertionMap is the collection of assertions, can be "r", "p", "g", "e", "m".
|
||||
type AssertionMap map[string]*Assertion
|
||||
|
||||
var sectionNameMap = map[string]string{
|
||||
"r": "request_definition",
|
||||
"p": "policy_definition",
|
||||
"g": "role_definition",
|
||||
"e": "policy_effect",
|
||||
"m": "matchers",
|
||||
}
|
||||
|
||||
func loadAssertion(model Model, cfg config.ConfigInterface, sec string, key string) bool {
|
||||
value := cfg.String(sectionNameMap[sec] + "::" + key)
|
||||
return model.AddDef(sec, key, value)
|
||||
}
|
||||
|
||||
// AddDef adds an assertion to the model.
|
||||
func (model Model) AddDef(sec string, key string, value string) bool {
|
||||
ast := Assertion{}
|
||||
ast.Key = key
|
||||
ast.Value = value
|
||||
|
||||
if ast.Value == "" {
|
||||
return false
|
||||
}
|
||||
|
||||
if sec == "r" || sec == "p" {
|
||||
ast.Tokens = strings.Split(ast.Value, ", ")
|
||||
for i := range ast.Tokens {
|
||||
ast.Tokens[i] = key + "_" + ast.Tokens[i]
|
||||
}
|
||||
} else {
|
||||
ast.Value = util.RemoveComments(util.EscapeAssertion(ast.Value))
|
||||
}
|
||||
|
||||
_, ok := model[sec]
|
||||
if !ok {
|
||||
model[sec] = make(AssertionMap)
|
||||
}
|
||||
|
||||
model[sec][key] = &ast
|
||||
return true
|
||||
}
|
||||
|
||||
func getKeySuffix(i int) string {
|
||||
if i == 1 {
|
||||
return ""
|
||||
}
|
||||
|
||||
return strconv.Itoa(i)
|
||||
}
|
||||
|
||||
func loadSection(model Model, cfg config.ConfigInterface, sec string) {
|
||||
i := 1
|
||||
for {
|
||||
if !loadAssertion(model, cfg, sec, sec+getKeySuffix(i)) {
|
||||
break
|
||||
} else {
|
||||
i++
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// LoadModel loads the model from model CONF file.
|
||||
func (model Model) LoadModel(path string) {
|
||||
cfg, err := config.NewConfig(path)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
loadSection(model, cfg, "r")
|
||||
loadSection(model, cfg, "p")
|
||||
loadSection(model, cfg, "e")
|
||||
loadSection(model, cfg, "m")
|
||||
|
||||
loadSection(model, cfg, "g")
|
||||
}
|
||||
|
||||
// LoadModelFromText loads the model from the text.
|
||||
func (model Model) LoadModelFromText(text string) {
|
||||
cfg, err := config.NewConfigFromText(text)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
loadSection(model, cfg, "r")
|
||||
loadSection(model, cfg, "p")
|
||||
loadSection(model, cfg, "e")
|
||||
loadSection(model, cfg, "m")
|
||||
|
||||
loadSection(model, cfg, "g")
|
||||
}
|
||||
|
||||
// PrintModel prints the model to the log.
|
||||
func (model Model) PrintModel() {
|
||||
util.LogPrint("Model:")
|
||||
for k, v := range model {
|
||||
for i, j := range v {
|
||||
util.LogPrintf("%s.%s: %s", k, i, j.Value)
|
||||
}
|
||||
}
|
||||
}
|
||||
146
vendor/github.com/casbin/casbin/model/policy.go
generated
vendored
146
vendor/github.com/casbin/casbin/model/policy.go
generated
vendored
@@ -1,146 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package model
|
||||
|
||||
import (
|
||||
"github.com/casbin/casbin/rbac"
|
||||
"github.com/casbin/casbin/util"
|
||||
)
|
||||
|
||||
// BuildRoleLinks initializes the roles in RBAC.
|
||||
func (model Model) BuildRoleLinks(rm rbac.RoleManager) {
|
||||
for _, ast := range model["g"] {
|
||||
ast.buildRoleLinks(rm)
|
||||
}
|
||||
}
|
||||
|
||||
// PrintPolicy prints the policy to log.
|
||||
func (model Model) PrintPolicy() {
|
||||
util.LogPrint("Policy:")
|
||||
for key, ast := range model["p"] {
|
||||
util.LogPrint(key, ": ", ast.Value, ": ", ast.Policy)
|
||||
}
|
||||
|
||||
for key, ast := range model["g"] {
|
||||
util.LogPrint(key, ": ", ast.Value, ": ", ast.Policy)
|
||||
}
|
||||
}
|
||||
|
||||
// ClearPolicy clears all current policy.
|
||||
func (model Model) ClearPolicy() {
|
||||
for _, ast := range model["p"] {
|
||||
ast.Policy = nil
|
||||
}
|
||||
|
||||
for _, ast := range model["g"] {
|
||||
ast.Policy = nil
|
||||
}
|
||||
}
|
||||
|
||||
// GetPolicy gets all rules in a policy.
|
||||
func (model Model) GetPolicy(sec string, ptype string) [][]string {
|
||||
return model[sec][ptype].Policy
|
||||
}
|
||||
|
||||
// GetFilteredPolicy gets rules based on field filters from a policy.
|
||||
func (model Model) GetFilteredPolicy(sec string, ptype string, fieldIndex int, fieldValues ...string) [][]string {
|
||||
res := [][]string{}
|
||||
|
||||
for _, rule := range model[sec][ptype].Policy {
|
||||
matched := true
|
||||
for i, fieldValue := range fieldValues {
|
||||
if fieldValue != "" && rule[fieldIndex+i] != fieldValue {
|
||||
matched = false
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
if matched {
|
||||
res = append(res, rule)
|
||||
}
|
||||
}
|
||||
|
||||
return res
|
||||
}
|
||||
|
||||
// HasPolicy determines whether a model has the specified policy rule.
|
||||
func (model Model) HasPolicy(sec string, ptype string, rule []string) bool {
|
||||
for _, r := range model[sec][ptype].Policy {
|
||||
if util.ArrayEquals(rule, r) {
|
||||
return true
|
||||
}
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
// AddPolicy adds a policy rule to the model.
|
||||
func (model Model) AddPolicy(sec string, ptype string, rule []string) bool {
|
||||
if !model.HasPolicy(sec, ptype, rule) {
|
||||
model[sec][ptype].Policy = append(model[sec][ptype].Policy, rule)
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
// RemovePolicy removes a policy rule from the model.
|
||||
func (model Model) RemovePolicy(sec string, ptype string, rule []string) bool {
|
||||
for i, r := range model[sec][ptype].Policy {
|
||||
if util.ArrayEquals(rule, r) {
|
||||
model[sec][ptype].Policy = append(model[sec][ptype].Policy[:i], model[sec][ptype].Policy[i+1:]...)
|
||||
return true
|
||||
}
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
// RemoveFilteredPolicy removes policy rules based on field filters from the model.
|
||||
func (model Model) RemoveFilteredPolicy(sec string, ptype string, fieldIndex int, fieldValues ...string) bool {
|
||||
tmp := [][]string{}
|
||||
res := false
|
||||
for _, rule := range model[sec][ptype].Policy {
|
||||
matched := true
|
||||
for i, fieldValue := range fieldValues {
|
||||
if fieldValue != "" && rule[fieldIndex+i] != fieldValue {
|
||||
matched = false
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
if matched {
|
||||
res = true
|
||||
} else {
|
||||
tmp = append(tmp, rule)
|
||||
}
|
||||
}
|
||||
|
||||
model[sec][ptype].Policy = tmp
|
||||
return res
|
||||
}
|
||||
|
||||
// GetValuesForFieldInPolicy gets all values for a field for all rules in a policy, duplicated values are removed.
|
||||
func (model Model) GetValuesForFieldInPolicy(sec string, ptype string, fieldIndex int) []string {
|
||||
values := []string{}
|
||||
|
||||
for _, rule := range model[sec][ptype].Policy {
|
||||
values = append(values, rule[fieldIndex])
|
||||
}
|
||||
|
||||
util.ArrayRemoveDuplicates(&values)
|
||||
// sort.Strings(values)
|
||||
|
||||
return values
|
||||
}
|
||||
56
vendor/github.com/casbin/casbin/persist/adapter.go
generated
vendored
56
vendor/github.com/casbin/casbin/persist/adapter.go
generated
vendored
@@ -1,56 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package persist
|
||||
|
||||
import (
|
||||
"strings"
|
||||
|
||||
"github.com/casbin/casbin/model"
|
||||
)
|
||||
|
||||
// LoadPolicyLine loads a text line as a policy rule to model.
|
||||
func LoadPolicyLine(line string, model model.Model) {
|
||||
if line == "" {
|
||||
return
|
||||
}
|
||||
|
||||
if strings.HasPrefix(line, "#") {
|
||||
return
|
||||
}
|
||||
|
||||
tokens := strings.Split(line, ", ")
|
||||
|
||||
key := tokens[0]
|
||||
sec := key[:1]
|
||||
model[sec][key].Policy = append(model[sec][key].Policy, tokens[1:])
|
||||
}
|
||||
|
||||
// Adapter is the interface for Casbin adapters.
|
||||
type Adapter interface {
|
||||
// LoadPolicy loads all policy rules from the storage.
|
||||
LoadPolicy(model model.Model) error
|
||||
// SavePolicy saves all policy rules to the storage.
|
||||
SavePolicy(model model.Model) error
|
||||
|
||||
// AddPolicy adds a policy rule to the storage.
|
||||
// This is part of the Auto-Save feature.
|
||||
AddPolicy(sec string, ptype string, rule []string) error
|
||||
// RemovePolicy removes a policy rule from the storage.
|
||||
// This is part of the Auto-Save feature.
|
||||
RemovePolicy(sec string, ptype string, rule []string) error
|
||||
// RemoveFilteredPolicy removes policy rules that match the filter from the storage.
|
||||
// This is part of the Auto-Save feature.
|
||||
RemoveFilteredPolicy(sec string, ptype string, fieldIndex int, fieldValues ...string) error
|
||||
}
|
||||
29
vendor/github.com/casbin/casbin/persist/adapter_filtered.go
generated
vendored
29
vendor/github.com/casbin/casbin/persist/adapter_filtered.go
generated
vendored
@@ -1,29 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package persist
|
||||
|
||||
import (
|
||||
"github.com/casbin/casbin/model"
|
||||
)
|
||||
|
||||
// FilteredAdapter is the interface for Casbin adapters supporting filtered policies.
|
||||
type FilteredAdapter interface {
|
||||
Adapter
|
||||
|
||||
// LoadFilteredPolicy loads only policy rules that match the filter.
|
||||
LoadFilteredPolicy(model model.Model, filter interface{}) error
|
||||
// IsFiltered returns true if the loaded policy has been filtered.
|
||||
IsFiltered() bool
|
||||
}
|
||||
117
vendor/github.com/casbin/casbin/persist/file-adapter/adapter.go
generated
vendored
117
vendor/github.com/casbin/casbin/persist/file-adapter/adapter.go
generated
vendored
@@ -1,117 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package fileadapter
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"bytes"
|
||||
"errors"
|
||||
"os"
|
||||
"strings"
|
||||
|
||||
"github.com/casbin/casbin/model"
|
||||
"github.com/casbin/casbin/persist"
|
||||
"github.com/casbin/casbin/util"
|
||||
)
|
||||
|
||||
// Adapter is the file adapter for Casbin.
|
||||
// It can load policy from file or save policy to file.
|
||||
type Adapter struct {
|
||||
filePath string
|
||||
}
|
||||
|
||||
// NewAdapter is the constructor for Adapter.
|
||||
func NewAdapter(filePath string) *Adapter {
|
||||
return &Adapter{filePath: filePath}
|
||||
}
|
||||
|
||||
// LoadPolicy loads all policy rules from the storage.
|
||||
func (a *Adapter) LoadPolicy(model model.Model) error {
|
||||
if a.filePath == "" {
|
||||
return errors.New("invalid file path, file path cannot be empty")
|
||||
}
|
||||
|
||||
return a.loadPolicyFile(model, persist.LoadPolicyLine)
|
||||
}
|
||||
|
||||
// SavePolicy saves all policy rules to the storage.
|
||||
func (a *Adapter) SavePolicy(model model.Model) error {
|
||||
if a.filePath == "" {
|
||||
return errors.New("invalid file path, file path cannot be empty")
|
||||
}
|
||||
|
||||
var tmp bytes.Buffer
|
||||
|
||||
for ptype, ast := range model["p"] {
|
||||
for _, rule := range ast.Policy {
|
||||
tmp.WriteString(ptype + ", ")
|
||||
tmp.WriteString(util.ArrayToString(rule))
|
||||
tmp.WriteString("\n")
|
||||
}
|
||||
}
|
||||
|
||||
for ptype, ast := range model["g"] {
|
||||
for _, rule := range ast.Policy {
|
||||
tmp.WriteString(ptype + ", ")
|
||||
tmp.WriteString(util.ArrayToString(rule))
|
||||
tmp.WriteString("\n")
|
||||
}
|
||||
}
|
||||
|
||||
return a.savePolicyFile(strings.TrimRight(tmp.String(), "\n"))
|
||||
}
|
||||
|
||||
func (a *Adapter) loadPolicyFile(model model.Model, handler func(string, model.Model)) error {
|
||||
f, err := os.Open(a.filePath)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer f.Close()
|
||||
|
||||
scanner := bufio.NewScanner(f)
|
||||
for scanner.Scan() {
|
||||
line := strings.TrimSpace(scanner.Text())
|
||||
handler(line, model)
|
||||
}
|
||||
return scanner.Err()
|
||||
}
|
||||
|
||||
func (a *Adapter) savePolicyFile(text string) error {
|
||||
f, err := os.Create(a.filePath)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
w := bufio.NewWriter(f)
|
||||
// error intentionally ignored
|
||||
w.WriteString(text)
|
||||
w.Flush()
|
||||
f.Close()
|
||||
return nil
|
||||
}
|
||||
|
||||
// AddPolicy adds a policy rule to the storage.
|
||||
func (a *Adapter) AddPolicy(sec string, ptype string, rule []string) error {
|
||||
return errors.New("not implemented")
|
||||
}
|
||||
|
||||
// RemovePolicy removes a policy rule from the storage.
|
||||
func (a *Adapter) RemovePolicy(sec string, ptype string, rule []string) error {
|
||||
return errors.New("not implemented")
|
||||
}
|
||||
|
||||
// RemoveFilteredPolicy removes policy rules that match the filter from the storage.
|
||||
func (a *Adapter) RemoveFilteredPolicy(sec string, ptype string, fieldIndex int, fieldValues ...string) error {
|
||||
return errors.New("not implemented")
|
||||
}
|
||||
137
vendor/github.com/casbin/casbin/persist/file-adapter/adapter_filtered.go
generated
vendored
137
vendor/github.com/casbin/casbin/persist/file-adapter/adapter_filtered.go
generated
vendored
@@ -1,137 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package fileadapter
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"errors"
|
||||
"os"
|
||||
"strings"
|
||||
|
||||
"github.com/casbin/casbin/model"
|
||||
"github.com/casbin/casbin/persist"
|
||||
)
|
||||
|
||||
// FilteredAdapter is the filtered file adapter for Casbin. It can load policy
|
||||
// from file or save policy to file and supports loading of filtered policies.
|
||||
type FilteredAdapter struct {
|
||||
*Adapter
|
||||
filtered bool
|
||||
}
|
||||
|
||||
// Filter defines the filtering rules for a FilteredAdapter's policy. Empty values
|
||||
// are ignored, but all others must match the filter.
|
||||
type Filter struct {
|
||||
P []string
|
||||
G []string
|
||||
}
|
||||
|
||||
// NewFilteredAdapter is the constructor for FilteredAdapter.
|
||||
func NewFilteredAdapter(filePath string) *FilteredAdapter {
|
||||
a := FilteredAdapter{}
|
||||
a.Adapter = NewAdapter(filePath)
|
||||
return &a
|
||||
}
|
||||
|
||||
// LoadPolicy loads all policy rules from the storage.
|
||||
func (a *FilteredAdapter) LoadPolicy(model model.Model) error {
|
||||
a.filtered = false
|
||||
return a.Adapter.LoadPolicy(model)
|
||||
}
|
||||
|
||||
// LoadFilteredPolicy loads only policy rules that match the filter.
|
||||
func (a *FilteredAdapter) LoadFilteredPolicy(model model.Model, filter interface{}) error {
|
||||
if filter == nil {
|
||||
return a.LoadPolicy(model)
|
||||
}
|
||||
if a.filePath == "" {
|
||||
return errors.New("invalid file path, file path cannot be empty")
|
||||
}
|
||||
|
||||
filterValue, ok := filter.(*Filter)
|
||||
if !ok {
|
||||
return errors.New("invalid filter type")
|
||||
}
|
||||
err := a.loadFilteredPolicyFile(model, filterValue, persist.LoadPolicyLine)
|
||||
if err == nil {
|
||||
a.filtered = true
|
||||
}
|
||||
return err
|
||||
}
|
||||
|
||||
func (a *FilteredAdapter) loadFilteredPolicyFile(model model.Model, filter *Filter, handler func(string, model.Model)) error {
|
||||
f, err := os.Open(a.filePath)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer f.Close()
|
||||
|
||||
scanner := bufio.NewScanner(f)
|
||||
for scanner.Scan() {
|
||||
line := strings.TrimSpace(scanner.Text())
|
||||
|
||||
if filterLine(line, filter) {
|
||||
continue
|
||||
}
|
||||
|
||||
handler(line, model)
|
||||
}
|
||||
return scanner.Err()
|
||||
}
|
||||
|
||||
// IsFiltered returns true if the loaded policy has been filtered.
|
||||
func (a *FilteredAdapter) IsFiltered() bool {
|
||||
return a.filtered
|
||||
}
|
||||
|
||||
// SavePolicy saves all policy rules to the storage.
|
||||
func (a *FilteredAdapter) SavePolicy(model model.Model) error {
|
||||
if a.filtered {
|
||||
return errors.New("cannot save a filtered policy")
|
||||
}
|
||||
return a.Adapter.SavePolicy(model)
|
||||
}
|
||||
|
||||
func filterLine(line string, filter *Filter) bool {
|
||||
if filter == nil {
|
||||
return false
|
||||
}
|
||||
p := strings.Split(line, ",")
|
||||
if len(p) == 0 {
|
||||
return true
|
||||
}
|
||||
var filterSlice []string
|
||||
switch strings.TrimSpace(p[0]) {
|
||||
case "p":
|
||||
filterSlice = filter.P
|
||||
case "g":
|
||||
filterSlice = filter.G
|
||||
}
|
||||
return filterWords(p, filterSlice)
|
||||
}
|
||||
|
||||
func filterWords(line []string, filter []string) bool {
|
||||
if len(line) < len(filter)+1 {
|
||||
return true
|
||||
}
|
||||
var skipLine bool
|
||||
for i, v := range filter {
|
||||
if len(v) > 0 && strings.TrimSpace(v) != strings.TrimSpace(line[i+1]) {
|
||||
skipLine = true
|
||||
break
|
||||
}
|
||||
}
|
||||
return skipLine
|
||||
}
|
||||
100
vendor/github.com/casbin/casbin/persist/file-adapter/adapter_mock.go
generated
vendored
100
vendor/github.com/casbin/casbin/persist/file-adapter/adapter_mock.go
generated
vendored
@@ -1,100 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package fileadapter
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"errors"
|
||||
"io"
|
||||
"os"
|
||||
"strings"
|
||||
|
||||
"github.com/casbin/casbin/model"
|
||||
"github.com/casbin/casbin/persist"
|
||||
)
|
||||
|
||||
// AdapterMock is the file adapter for Casbin.
|
||||
// It can load policy from file or save policy to file.
|
||||
type AdapterMock struct {
|
||||
filePath string
|
||||
errorValue string
|
||||
}
|
||||
|
||||
// NewAdapterMock is the constructor for AdapterMock.
|
||||
func NewAdapterMock(filePath string) *AdapterMock {
|
||||
a := AdapterMock{}
|
||||
a.filePath = filePath
|
||||
return &a
|
||||
}
|
||||
|
||||
// LoadPolicy loads all policy rules from the storage.
|
||||
func (a *AdapterMock) LoadPolicy(model model.Model) error {
|
||||
err := a.loadPolicyFile(model, persist.LoadPolicyLine)
|
||||
return err
|
||||
}
|
||||
|
||||
// SavePolicy saves all policy rules to the storage.
|
||||
func (a *AdapterMock) SavePolicy(model model.Model) error {
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *AdapterMock) loadPolicyFile(model model.Model, handler func(string, model.Model)) error {
|
||||
f, err := os.Open(a.filePath)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer f.Close()
|
||||
|
||||
buf := bufio.NewReader(f)
|
||||
for {
|
||||
line, err := buf.ReadString('\n')
|
||||
line = strings.TrimSpace(line)
|
||||
handler(line, model)
|
||||
if err != nil {
|
||||
if err == io.EOF {
|
||||
return nil
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// SetMockErr sets string to be returned by of the mock during testing
|
||||
func (a *AdapterMock) SetMockErr(errorToSet string) {
|
||||
a.errorValue = errorToSet
|
||||
}
|
||||
|
||||
// GetMockErr returns a mock error or nil
|
||||
func (a *AdapterMock) GetMockErr() error {
|
||||
var returnError error
|
||||
if a.errorValue != "" {
|
||||
returnError = errors.New(a.errorValue)
|
||||
}
|
||||
return returnError
|
||||
}
|
||||
|
||||
// AddPolicy adds a policy rule to the storage.
|
||||
func (a *AdapterMock) AddPolicy(sec string, ptype string, rule []string) error {
|
||||
return a.GetMockErr()
|
||||
}
|
||||
|
||||
// RemovePolicy removes a policy rule from the storage.
|
||||
func (a *AdapterMock) RemovePolicy(sec string, ptype string, rule []string) error {
|
||||
return a.GetMockErr()
|
||||
}
|
||||
|
||||
// RemoveFilteredPolicy removes policy rules that match the filter from the storage.
|
||||
func (a *AdapterMock) RemoveFilteredPolicy(sec string, ptype string, fieldIndex int, fieldValues ...string) error {
|
||||
return a.GetMockErr()
|
||||
}
|
||||
27
vendor/github.com/casbin/casbin/persist/watcher.go
generated
vendored
27
vendor/github.com/casbin/casbin/persist/watcher.go
generated
vendored
@@ -1,27 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package persist
|
||||
|
||||
// Watcher is the interface for Casbin watchers.
|
||||
type Watcher interface {
|
||||
// SetUpdateCallback sets the callback function that the watcher will call
|
||||
// when the policy in DB has been changed by other instances.
|
||||
// A classic callback is Enforcer.LoadPolicy().
|
||||
SetUpdateCallback(func(string)) error
|
||||
// Update calls the update callback of other instances to synchronize their policy.
|
||||
// It is usually called after changing the policy in DB, like Enforcer.SavePolicy(),
|
||||
// Enforcer.AddPolicy(), Enforcer.RemovePolicy(), etc.
|
||||
Update() error
|
||||
}
|
||||
257
vendor/github.com/casbin/casbin/rbac/default-role-manager/role_manager.go
generated
vendored
257
vendor/github.com/casbin/casbin/rbac/default-role-manager/role_manager.go
generated
vendored
@@ -1,257 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package defaultrolemanager
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"sync"
|
||||
|
||||
"github.com/casbin/casbin/rbac"
|
||||
"github.com/casbin/casbin/util"
|
||||
)
|
||||
|
||||
// RoleManager provides a default implementation for the RoleManager interface
|
||||
type RoleManager struct {
|
||||
allRoles *sync.Map
|
||||
maxHierarchyLevel int
|
||||
}
|
||||
|
||||
// NewRoleManager is the constructor for creating an instance of the
|
||||
// default RoleManager implementation.
|
||||
func NewRoleManager(maxHierarchyLevel int) rbac.RoleManager {
|
||||
rm := RoleManager{}
|
||||
rm.allRoles = &sync.Map{}
|
||||
rm.maxHierarchyLevel = maxHierarchyLevel
|
||||
return &rm
|
||||
}
|
||||
|
||||
func (rm *RoleManager) hasRole(name string) bool {
|
||||
_, ok := rm.allRoles.Load(name)
|
||||
return ok
|
||||
}
|
||||
|
||||
func (rm *RoleManager) createRole(name string) *Role {
|
||||
role, _ := rm.allRoles.LoadOrStore(name, newRole(name))
|
||||
return role.(*Role)
|
||||
}
|
||||
|
||||
// Clear clears all stored data and resets the role manager to the initial state.
|
||||
func (rm *RoleManager) Clear() error {
|
||||
rm.allRoles = &sync.Map{}
|
||||
return nil
|
||||
}
|
||||
|
||||
// AddLink adds the inheritance link between role: name1 and role: name2.
|
||||
// aka role: name1 inherits role: name2.
|
||||
// domain is a prefix to the roles.
|
||||
func (rm *RoleManager) AddLink(name1 string, name2 string, domain ...string) error {
|
||||
if len(domain) == 1 {
|
||||
name1 = domain[0] + "::" + name1
|
||||
name2 = domain[0] + "::" + name2
|
||||
} else if len(domain) > 1 {
|
||||
return errors.New("error: domain should be 1 parameter")
|
||||
}
|
||||
|
||||
role1 := rm.createRole(name1)
|
||||
role2 := rm.createRole(name2)
|
||||
role1.addRole(role2)
|
||||
return nil
|
||||
}
|
||||
|
||||
// DeleteLink deletes the inheritance link between role: name1 and role: name2.
|
||||
// aka role: name1 does not inherit role: name2 any more.
|
||||
// domain is a prefix to the roles.
|
||||
func (rm *RoleManager) DeleteLink(name1 string, name2 string, domain ...string) error {
|
||||
if len(domain) == 1 {
|
||||
name1 = domain[0] + "::" + name1
|
||||
name2 = domain[0] + "::" + name2
|
||||
} else if len(domain) > 1 {
|
||||
return errors.New("error: domain should be 1 parameter")
|
||||
}
|
||||
|
||||
if !rm.hasRole(name1) || !rm.hasRole(name2) {
|
||||
return errors.New("error: name1 or name2 does not exist")
|
||||
}
|
||||
|
||||
role1 := rm.createRole(name1)
|
||||
role2 := rm.createRole(name2)
|
||||
role1.deleteRole(role2)
|
||||
return nil
|
||||
}
|
||||
|
||||
// HasLink determines whether role: name1 inherits role: name2.
|
||||
// domain is a prefix to the roles.
|
||||
func (rm *RoleManager) HasLink(name1 string, name2 string, domain ...string) (bool, error) {
|
||||
if len(domain) == 1 {
|
||||
name1 = domain[0] + "::" + name1
|
||||
name2 = domain[0] + "::" + name2
|
||||
} else if len(domain) > 1 {
|
||||
return false, errors.New("error: domain should be 1 parameter")
|
||||
}
|
||||
|
||||
if name1 == name2 {
|
||||
return true, nil
|
||||
}
|
||||
|
||||
if !rm.hasRole(name1) || !rm.hasRole(name2) {
|
||||
return false, nil
|
||||
}
|
||||
|
||||
role1 := rm.createRole(name1)
|
||||
return role1.hasRole(name2, rm.maxHierarchyLevel), nil
|
||||
}
|
||||
|
||||
// GetRoles gets the roles that a subject inherits.
|
||||
// domain is a prefix to the roles.
|
||||
func (rm *RoleManager) GetRoles(name string, domain ...string) ([]string, error) {
|
||||
if len(domain) == 1 {
|
||||
name = domain[0] + "::" + name
|
||||
} else if len(domain) > 1 {
|
||||
return nil, errors.New("error: domain should be 1 parameter")
|
||||
}
|
||||
|
||||
if !rm.hasRole(name) {
|
||||
return nil, errors.New("error: name does not exist")
|
||||
}
|
||||
|
||||
roles := rm.createRole(name).getRoles()
|
||||
if len(domain) == 1 {
|
||||
for i := range roles {
|
||||
roles[i] = roles[i][len(domain[0])+2:]
|
||||
}
|
||||
}
|
||||
return roles, nil
|
||||
}
|
||||
|
||||
// GetUsers gets the users that inherits a subject.
|
||||
// domain is an unreferenced parameter here, may be used in other implementations.
|
||||
func (rm *RoleManager) GetUsers(name string, domain ...string) ([]string, error) {
|
||||
if !rm.hasRole(name) {
|
||||
return nil, errors.New("error: name does not exist")
|
||||
}
|
||||
|
||||
names := []string{}
|
||||
rm.allRoles.Range(func(_, value interface{}) bool {
|
||||
role := value.(*Role)
|
||||
if role.hasDirectRole(name) {
|
||||
names = append(names, role.name)
|
||||
}
|
||||
return true
|
||||
})
|
||||
return names, nil
|
||||
}
|
||||
|
||||
// PrintRoles prints all the roles to log.
|
||||
func (rm *RoleManager) PrintRoles() error {
|
||||
line := ""
|
||||
rm.allRoles.Range(func(_, value interface{}) bool {
|
||||
if text := value.(*Role).toString(); text != "" {
|
||||
if line == "" {
|
||||
line = text
|
||||
} else {
|
||||
line += ", " + text
|
||||
}
|
||||
}
|
||||
return true
|
||||
})
|
||||
util.LogPrint(line)
|
||||
return nil
|
||||
}
|
||||
|
||||
// Role represents the data structure for a role in RBAC.
|
||||
type Role struct {
|
||||
name string
|
||||
roles []*Role
|
||||
}
|
||||
|
||||
func newRole(name string) *Role {
|
||||
r := Role{}
|
||||
r.name = name
|
||||
return &r
|
||||
}
|
||||
|
||||
func (r *Role) addRole(role *Role) {
|
||||
for _, rr := range r.roles {
|
||||
if rr.name == role.name {
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
r.roles = append(r.roles, role)
|
||||
}
|
||||
|
||||
func (r *Role) deleteRole(role *Role) {
|
||||
for i, rr := range r.roles {
|
||||
if rr.name == role.name {
|
||||
r.roles = append(r.roles[:i], r.roles[i+1:]...)
|
||||
return
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (r *Role) hasRole(name string, hierarchyLevel int) bool {
|
||||
if r.name == name {
|
||||
return true
|
||||
}
|
||||
|
||||
if hierarchyLevel <= 0 {
|
||||
return false
|
||||
}
|
||||
|
||||
for _, role := range r.roles {
|
||||
if role.hasRole(name, hierarchyLevel-1) {
|
||||
return true
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func (r *Role) hasDirectRole(name string) bool {
|
||||
for _, role := range r.roles {
|
||||
if role.name == name {
|
||||
return true
|
||||
}
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
func (r *Role) toString() string {
|
||||
names := ""
|
||||
if len(r.roles) == 0 {
|
||||
return ""
|
||||
}
|
||||
for i, role := range r.roles {
|
||||
if i == 0 {
|
||||
names += role.name
|
||||
} else {
|
||||
names += ", " + role.name
|
||||
}
|
||||
}
|
||||
|
||||
if len(r.roles) == 1 {
|
||||
return r.name + " < " + names
|
||||
} else {
|
||||
return r.name + " < (" + names + ")"
|
||||
}
|
||||
}
|
||||
|
||||
func (r *Role) getRoles() []string {
|
||||
names := []string{}
|
||||
for _, role := range r.roles {
|
||||
names = append(names, role.name)
|
||||
}
|
||||
return names
|
||||
}
|
||||
38
vendor/github.com/casbin/casbin/rbac/role_manager.go
generated
vendored
38
vendor/github.com/casbin/casbin/rbac/role_manager.go
generated
vendored
@@ -1,38 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package rbac
|
||||
|
||||
// RoleManager provides interface to define the operations for managing roles.
|
||||
type RoleManager interface {
|
||||
// Clear clears all stored data and resets the role manager to the initial state.
|
||||
Clear() error
|
||||
// AddLink adds the inheritance link between two roles. role: name1 and role: name2.
|
||||
// domain is a prefix to the roles (can be used for other purposes).
|
||||
AddLink(name1 string, name2 string, domain ...string) error
|
||||
// DeleteLink deletes the inheritance link between two roles. role: name1 and role: name2.
|
||||
// domain is a prefix to the roles (can be used for other purposes).
|
||||
DeleteLink(name1 string, name2 string, domain ...string) error
|
||||
// HasLink determines whether a link exists between two roles. role: name1 inherits role: name2.
|
||||
// domain is a prefix to the roles (can be used for other purposes).
|
||||
HasLink(name1 string, name2 string, domain ...string) (bool, error)
|
||||
// GetRoles gets the roles that a user inherits.
|
||||
// domain is a prefix to the roles (can be used for other purposes).
|
||||
GetRoles(name string, domain ...string) ([]string, error)
|
||||
// GetUsers gets the users that inherits a role.
|
||||
// domain is a prefix to the users (can be used for other purposes).
|
||||
GetUsers(name string, domain ...string) ([]string, error)
|
||||
// PrintRoles prints all the roles to log.
|
||||
PrintRoles() error
|
||||
}
|
||||
127
vendor/github.com/casbin/casbin/rbac_api.go
generated
vendored
127
vendor/github.com/casbin/casbin/rbac_api.go
generated
vendored
@@ -1,127 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package casbin
|
||||
|
||||
// GetRolesForUser gets the roles that a user has.
|
||||
func (e *Enforcer) GetRolesForUser(name string) []string {
|
||||
res, _ := e.model["g"]["g"].RM.GetRoles(name)
|
||||
return res
|
||||
}
|
||||
|
||||
// GetUsersForRole gets the users that has a role.
|
||||
func (e *Enforcer) GetUsersForRole(name string) []string {
|
||||
res, _ := e.model["g"]["g"].RM.GetUsers(name)
|
||||
return res
|
||||
}
|
||||
|
||||
// HasRoleForUser determines whether a user has a role.
|
||||
func (e *Enforcer) HasRoleForUser(name string, role string) bool {
|
||||
roles := e.GetRolesForUser(name)
|
||||
|
||||
hasRole := false
|
||||
for _, r := range roles {
|
||||
if r == role {
|
||||
hasRole = true
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
return hasRole
|
||||
}
|
||||
|
||||
// AddRoleForUser adds a role for a user.
|
||||
// Returns false if the user already has the role (aka not affected).
|
||||
func (e *Enforcer) AddRoleForUser(user string, role string) bool {
|
||||
return e.AddGroupingPolicy(user, role)
|
||||
}
|
||||
|
||||
// DeleteRoleForUser deletes a role for a user.
|
||||
// Returns false if the user does not have the role (aka not affected).
|
||||
func (e *Enforcer) DeleteRoleForUser(user string, role string) bool {
|
||||
return e.RemoveGroupingPolicy(user, role)
|
||||
}
|
||||
|
||||
// DeleteRolesForUser deletes all roles for a user.
|
||||
// Returns false if the user does not have any roles (aka not affected).
|
||||
func (e *Enforcer) DeleteRolesForUser(user string) bool {
|
||||
return e.RemoveFilteredGroupingPolicy(0, user)
|
||||
}
|
||||
|
||||
// DeleteUser deletes a user.
|
||||
// Returns false if the user does not exist (aka not affected).
|
||||
func (e *Enforcer) DeleteUser(user string) bool {
|
||||
return e.RemoveFilteredGroupingPolicy(0, user)
|
||||
}
|
||||
|
||||
// DeleteRole deletes a role.
|
||||
func (e *Enforcer) DeleteRole(role string) {
|
||||
e.RemoveFilteredGroupingPolicy(1, role)
|
||||
e.RemoveFilteredPolicy(0, role)
|
||||
}
|
||||
|
||||
// DeletePermission deletes a permission.
|
||||
// Returns false if the permission does not exist (aka not affected).
|
||||
func (e *Enforcer) DeletePermission(permission ...string) bool {
|
||||
return e.RemoveFilteredPolicy(1, permission...)
|
||||
}
|
||||
|
||||
// AddPermissionForUser adds a permission for a user or role.
|
||||
// Returns false if the user or role already has the permission (aka not affected).
|
||||
func (e *Enforcer) AddPermissionForUser(user string, permission ...string) bool {
|
||||
params := make([]interface{}, 0, len(permission)+1)
|
||||
|
||||
params = append(params, user)
|
||||
for _, perm := range permission {
|
||||
params = append(params, perm)
|
||||
}
|
||||
|
||||
return e.AddPolicy(params...)
|
||||
}
|
||||
|
||||
// DeletePermissionForUser deletes a permission for a user or role.
|
||||
// Returns false if the user or role does not have the permission (aka not affected).
|
||||
func (e *Enforcer) DeletePermissionForUser(user string, permission ...string) bool {
|
||||
params := make([]interface{}, 0, len(permission)+1)
|
||||
|
||||
params = append(params, user)
|
||||
for _, perm := range permission {
|
||||
params = append(params, perm)
|
||||
}
|
||||
|
||||
return e.RemovePolicy(params...)
|
||||
}
|
||||
|
||||
// DeletePermissionsForUser deletes permissions for a user or role.
|
||||
// Returns false if the user or role does not have any permissions (aka not affected).
|
||||
func (e *Enforcer) DeletePermissionsForUser(user string) bool {
|
||||
return e.RemoveFilteredPolicy(0, user)
|
||||
}
|
||||
|
||||
// GetPermissionsForUser gets permissions for a user or role.
|
||||
func (e *Enforcer) GetPermissionsForUser(user string) [][]string {
|
||||
return e.GetFilteredPolicy(0, user)
|
||||
}
|
||||
|
||||
// HasPermissionForUser determines whether a user has a permission.
|
||||
func (e *Enforcer) HasPermissionForUser(user string, permission ...string) bool {
|
||||
params := make([]interface{}, 0, len(permission)+1)
|
||||
|
||||
params = append(params, user)
|
||||
for _, perm := range permission {
|
||||
params = append(params, perm)
|
||||
}
|
||||
|
||||
return e.HasPolicy(params...)
|
||||
}
|
||||
121
vendor/github.com/casbin/casbin/rbac_api_synced.go
generated
vendored
121
vendor/github.com/casbin/casbin/rbac_api_synced.go
generated
vendored
@@ -1,121 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package casbin
|
||||
|
||||
// GetRolesForUser gets the roles that a user has.
|
||||
func (e *SyncedEnforcer) GetRolesForUser(name string) []string {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.GetRolesForUser(name)
|
||||
}
|
||||
|
||||
// GetUsersForRole gets the users that has a role.
|
||||
func (e *SyncedEnforcer) GetUsersForRole(name string) []string {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.GetUsersForRole(name)
|
||||
}
|
||||
|
||||
// HasRoleForUser determines whether a user has a role.
|
||||
func (e *SyncedEnforcer) HasRoleForUser(name string, role string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.HasRoleForUser(name, role)
|
||||
}
|
||||
|
||||
// AddRoleForUser adds a role for a user.
|
||||
// Returns false if the user already has the role (aka not affected).
|
||||
func (e *SyncedEnforcer) AddRoleForUser(user string, role string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.AddRoleForUser(user, role)
|
||||
}
|
||||
|
||||
// DeleteRoleForUser deletes a role for a user.
|
||||
// Returns false if the user does not have the role (aka not affected).
|
||||
func (e *SyncedEnforcer) DeleteRoleForUser(user string, role string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.DeleteRoleForUser(user, role)
|
||||
}
|
||||
|
||||
// DeleteRolesForUser deletes all roles for a user.
|
||||
// Returns false if the user does not have any roles (aka not affected).
|
||||
func (e *SyncedEnforcer) DeleteRolesForUser(user string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.DeleteRolesForUser(user)
|
||||
}
|
||||
|
||||
// DeleteUser deletes a user.
|
||||
// Returns false if the user does not exist (aka not affected).
|
||||
func (e *SyncedEnforcer) DeleteUser(user string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.DeleteUser(user)
|
||||
}
|
||||
|
||||
// DeleteRole deletes a role.
|
||||
func (e *SyncedEnforcer) DeleteRole(role string) {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
e.Enforcer.DeleteRole(role)
|
||||
}
|
||||
|
||||
// DeletePermission deletes a permission.
|
||||
// Returns false if the permission does not exist (aka not affected).
|
||||
func (e *SyncedEnforcer) DeletePermission(permission ...string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.DeletePermission(permission...)
|
||||
}
|
||||
|
||||
// AddPermissionForUser adds a permission for a user or role.
|
||||
// Returns false if the user or role already has the permission (aka not affected).
|
||||
func (e *SyncedEnforcer) AddPermissionForUser(user string, permission ...string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.AddPermissionForUser(user, permission...)
|
||||
}
|
||||
|
||||
// DeletePermissionForUser deletes a permission for a user or role.
|
||||
// Returns false if the user or role does not have the permission (aka not affected).
|
||||
func (e *SyncedEnforcer) DeletePermissionForUser(user string, permission ...string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.DeletePermissionForUser(user, permission...)
|
||||
}
|
||||
|
||||
// DeletePermissionsForUser deletes permissions for a user or role.
|
||||
// Returns false if the user or role does not have any permissions (aka not affected).
|
||||
func (e *SyncedEnforcer) DeletePermissionsForUser(user string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.DeletePermissionsForUser(user)
|
||||
}
|
||||
|
||||
// GetPermissionsForUser gets permissions for a user or role.
|
||||
func (e *SyncedEnforcer) GetPermissionsForUser(user string) [][]string {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.GetPermissionsForUser(user)
|
||||
}
|
||||
|
||||
// HasPermissionForUser determines whether a user has a permission.
|
||||
func (e *SyncedEnforcer) HasPermissionForUser(user string, permission ...string) bool {
|
||||
e.m.Lock()
|
||||
defer e.m.Unlock()
|
||||
return e.Enforcer.HasPermissionForUser(user, permission...)
|
||||
}
|
||||
38
vendor/github.com/casbin/casbin/rbac_api_with_domains.go
generated
vendored
38
vendor/github.com/casbin/casbin/rbac_api_with_domains.go
generated
vendored
@@ -1,38 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package casbin
|
||||
|
||||
// GetRolesForUserInDomain gets the roles that a user has inside a domain.
|
||||
func (e *Enforcer) GetRolesForUserInDomain(name string, domain string) []string {
|
||||
res, _ := e.model["g"]["g"].RM.GetRoles(name, domain)
|
||||
return res
|
||||
}
|
||||
|
||||
// GetPermissionsForUserInDomain gets permissions for a user or role inside a domain.
|
||||
func (e *Enforcer) GetPermissionsForUserInDomain(user string, domain string) [][]string {
|
||||
return e.GetFilteredPolicy(0, user, domain)
|
||||
}
|
||||
|
||||
// AddRoleForUserInDomain adds a role for a user inside a domain.
|
||||
// Returns false if the user already has the role (aka not affected).
|
||||
func (e *Enforcer) AddRoleForUserInDomain(user string, role string, domain string) bool {
|
||||
return e.AddGroupingPolicy(user, role, domain)
|
||||
}
|
||||
|
||||
// DeleteRoleForUserInDomain deletes a role for a user inside a domain.
|
||||
// Returns false if the user does not have the role (aka not affected).
|
||||
func (e *Enforcer) DeleteRoleForUserInDomain(user string, role string, domain string) bool {
|
||||
return e.RemoveGroupingPolicy(user, role, domain)
|
||||
}
|
||||
160
vendor/github.com/casbin/casbin/util/builtin_operators.go
generated
vendored
160
vendor/github.com/casbin/casbin/util/builtin_operators.go
generated
vendored
@@ -1,160 +0,0 @@
|
||||
// Copyright 2017 The casbin Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package util
|
||||
|
||||
import (
|
||||
"net"
|
||||
"regexp"
|
||||
"strings"
|
||||
|
||||
"github.com/casbin/casbin/rbac"
|
||||
)
|
||||
|
||||
// KeyMatch determines whether key1 matches the pattern of key2 (similar to RESTful path), key2 can contain a *.
|
||||
// For example, "/foo/bar" matches "/foo/*"
|
||||
func KeyMatch(key1 string, key2 string) bool {
|
||||
i := strings.Index(key2, "*")
|
||||
if i == -1 {
|
||||
return key1 == key2
|
||||
}
|
||||
|
||||
if len(key1) > i {
|
||||
return key1[:i] == key2[:i]
|
||||
}
|
||||
return key1 == key2[:i]
|
||||
}
|
||||
|
||||
// KeyMatchFunc is the wrapper for KeyMatch.
|
||||
func KeyMatchFunc(args ...interface{}) (interface{}, error) {
|
||||
name1 := args[0].(string)
|
||||
name2 := args[1].(string)
|
||||
|
||||
return (bool)(KeyMatch(name1, name2)), nil
|
||||
}
|
||||
|
||||
// KeyMatch2 determines whether key1 matches the pattern of key2 (similar to RESTful path), key2 can contain a *.
|
||||
// For example, "/foo/bar" matches "/foo/*", "/resource1" matches "/:resource"
|
||||
func KeyMatch2(key1 string, key2 string) bool {
|
||||
key2 = strings.Replace(key2, "/*", "/.*", -1)
|
||||
|
||||
re := regexp.MustCompile(`(.*):[^/]+(.*)`)
|
||||
for {
|
||||
if !strings.Contains(key2, "/:") {
|
||||
break
|
||||
}
|
||||
|
||||
key2 = "^" + re.ReplaceAllString(key2, "$1[^/]+$2") + "$"
|
||||
}
|
||||
|
||||
return RegexMatch(key1, key2)
|
||||
}
|
||||
|
||||
// KeyMatch2Func is the wrapper for KeyMatch2.
|
||||
func KeyMatch2Func(args ...interface{}) (interface{}, error) {
|
||||
name1 := args[0].(string)
|
||||
name2 := args[1].(string)
|
||||
|
||||
return (bool)(KeyMatch2(name1, name2)), nil
|
||||
}
|
||||
|
||||
// KeyMatch3 determines whether key1 matches the pattern of key2 (similar to RESTful path), key2 can contain a *.
|
||||
// For example, "/foo/bar" matches "/foo/*", "/resource1" matches "/{resource}"
|
||||
func KeyMatch3(key1 string, key2 string) bool {
|
||||
key2 = strings.Replace(key2, "/*", "/.*", -1)
|
||||
|
||||
re := regexp.MustCompile(`(.*)\{[^/]+\}(.*)`)
|
||||
for {
|
||||
if !strings.Contains(key2, "/{") {
|
||||
break
|
||||
}
|
||||
|
||||
key2 = re.ReplaceAllString(key2, "$1[^/]+$2")
|
||||
}
|
||||
|
||||
return RegexMatch(key1, key2)
|
||||
}
|
||||
|
||||
// KeyMatch3Func is the wrapper for KeyMatch3.
|
||||
func KeyMatch3Func(args ...interface{}) (interface{}, error) {
|
||||
name1 := args[0].(string)
|
||||
name2 := args[1].(string)
|
||||
|
||||
return (bool)(KeyMatch3(name1, name2)), nil
|
||||
}
|
||||
|
||||
// RegexMatch determines whether key1 matches the pattern of key2 in regular expression.
|
||||
func RegexMatch(key1 string, key2 string) bool {
|
||||
res, err := regexp.MatchString(key2, key1)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
// RegexMatchFunc is the wrapper for RegexMatch.
|
||||
func RegexMatchFunc(args ...interface{}) (interface{}, error) {
|
||||
name1 := args[0].(string)
|
||||
name2 := args[1].(string)
|
||||
|
||||
return (bool)(RegexMatch(name1, name2)), nil
|
||||
}
|
||||
|
||||
// IPMatch determines whether IP address ip1 matches the pattern of IP address ip2, ip2 can be an IP address or a CIDR pattern.
|
||||
// For example, "192.168.2.123" matches "192.168.2.0/24"
|
||||
func IPMatch(ip1 string, ip2 string) bool {
|
||||
objIP1 := net.ParseIP(ip1)
|
||||
if objIP1 == nil {
|
||||
panic("invalid argument: ip1 in IPMatch() function is not an IP address.")
|
||||
}
|
||||
|
||||
_, cidr, err := net.ParseCIDR(ip2)
|
||||
if err != nil {
|
||||
objIP2 := net.ParseIP(ip2)
|
||||
if objIP2 == nil {
|
||||
panic("invalid argument: ip2 in IPMatch() function is neither an IP address nor a CIDR.")
|
||||
}
|
||||
|
||||
return objIP1.Equal(objIP2)
|
||||
}
|
||||
|
||||
return cidr.Contains(objIP1)
|
||||
}
|
||||
|
||||
// IPMatchFunc is the wrapper for IPMatch.
|
||||
func IPMatchFunc(args ...interface{}) (interface{}, error) {
|
||||
ip1 := args[0].(string)
|
||||
ip2 := args[1].(string)
|
||||
|
||||
return (bool)(IPMatch(ip1, ip2)), nil
|
||||
}
|
||||
|
||||
// GenerateGFunction is the factory method of the g(_, _) function.
|
||||
func GenerateGFunction(rm rbac.RoleManager) func(args ...interface{}) (interface{}, error) {
|
||||
return func(args ...interface{}) (interface{}, error) {
|
||||
name1 := args[0].(string)
|
||||
name2 := args[1].(string)
|
||||
|
||||
if rm == nil {
|
||||
return name1 == name2, nil
|
||||
} else if len(args) == 2 {
|
||||
res, _ := rm.HasLink(name1, name2)
|
||||
return res, nil
|
||||
} else {
|
||||
domain := args[2].(string)
|
||||
res, _ := rm.HasLink(name1, name2, domain)
|
||||
return res, nil
|
||||
}
|
||||
}
|
||||
}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user